

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「ディープラーニングの手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの手法」の内容。
その中でも「モデルの解釈性・軽量化」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
長かったディープラーニングの手法も、これで最後の単元になりますね。
ディープラーニングは計算量が多くなるのが普通なので、実装となるとなるべく軽量化したい。
さらに構造も複雑なので「なんでその結果を導いたのか」が分からなくなりがちです。
そこで今回の内容である「モデルの解釈性・軽量化」ということが重要になってきます。
今までの記事で、見たことある単語も出てくるかもしれませんが、復習の意味も兼ねて触れていきますね。
まずは、モデルの解釈性を上げるための工夫を見ていきましょう。
CAM
CAMとは、ディープラーニングで機械がなぜその結果を返したのかを分かりやすくする技術の一つ。
主に画像認識の分野で使われます。
これまででたくさん見てきたように、ディープラーニングは構造が複雑すぎて「なぜその結果になったのか」が見えにくくなりがちです。
そこで、XAI(説明可能なAI)という考え方が現れました。
その流れを受けて、開発された技術ですね。
画像認識でも「なぜAIは画像を犬に分類したのか」みたいなのが気になってきます。
そこでCAMでは、特定のクラスに寄与したとされる入力領域をハイライトする手法。
イメージは以下の図のような感じ。

左は「なぜ”歯磨き”に分類したのか」、右は「なぜ”木を切る”に分類したのか」が赤くなっていますね。
AIは特に赤い部分に注目して画像分類を行っていたことが分かります。
Grad-CAM
Grad-CAMとは、CAMの発展手法のこと。
基本的にはCAMと同じで、モデルに対してある入力とその予測に対して局所的な説明を与える手法です。
なのでCAMと同じことができます。
異なる点は、様々なモデルに利用できるようになった点。
様々なモデル、といっても画像認識分野の中の「画像分類以外」のタスクにも使えるという意味のようですが。
Grad-CAMは、Gradient-weighted Class Activation Mappingの略です。
Gradient-weightedとあるように、勾配に重みをつけることで、どこが重要かを可視化することに成功したみたいですね。
LIME
LIMEとは自然言語処理などに使われる、XAI技術の一つ。
複雑なモデルを線形回帰のような簡単なモデルで表現しなおすことで、解釈性の向上を目指しているようですね。
ライブラリも用意されており、実装しやすいという点もメリットでしょう。
こちらは先ほどまでの画像分類も、自然言語処理でも使われるようです。
可視化すると以下のような出力が取得可能。
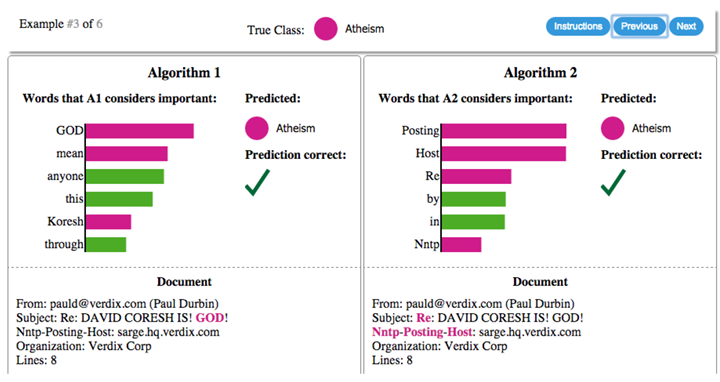
こちらは自然言語処理で、メールの文面からAlgorithm 1とAlgorithm 2を使って、Atheism(無神論者)かChristianity(キリスト教者)かを判断。
メールの文面(Document)から「どの単語を参考にしたか」が可視化されています。
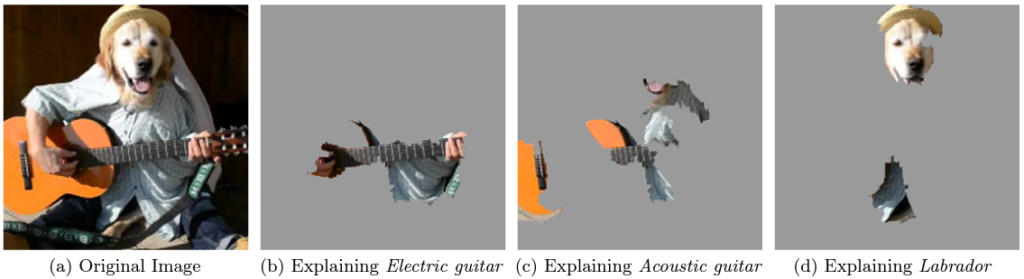
こちらは画像分類で、画像のどの位置を参考にして、その分類を行ったのかを可視化。
エレクトリックギター(b)、アコースティックギター(c)、ラブラドール(d)として分類した理由を可視化していますね。
LIMEは非常に便利なのですが、近似した分類器が元の分類器と違う分類をしてしまったりなど、問題もあるようです。

SHAP
SHAPとは、2016年、Lundberg and Leeが発表したXAI技術の一つ。
シャープレイ値を計算することで、各説明変数がどれくらい影響したのかを説明するようです。
シャープレイ値というのは、協力ゲーム理論で使われる値。
各プレイヤーに、結果への影響ごとに、公平に報酬を分配するものです。
SHAPに当てはめると「各”特徴量”に、結果への影響ごとに、公平に”予測値の差”を分配する」となります。
どういうことか?
実際に論文の図を見てみましょう。

上の図のxが「各特徴量」、Φが「予測値の差」です。
この例では全特徴量は「x1,2,3,4」。
E[f(z)]から、特徴量「x1,2,3」の影響を一つずつ考えると、「Φ1,2,3,4」という影響が現れます。
Φが大きいほど、最終的な予測値f(x)への特徴量の影響が大きいということですね。
最初のE[f(z)]の決め方は、いろいろあるようです。
一つには注目する変数(今回はx1,2,3,4)以外で作成した関数の期待値を使う、という方法があるみたいですね。
クラウドAI
クラウドAIとは、AIが搭載されたクラウドにデータを送信し、学習・推論する技術。
後に紹介する「エッジAI」とよく対になって紹介されているようです。
「普通のこと言ってない?」と思った方、大正解。
従来から使用されていたAIの技術ですね。
処理手順としては、以下の通り。
1.IoT機器やセンサーなど端末でデータ収集
2.大量のデータをクラウドに送信
3.クラウドで学習・推論
4.結果を端末に送る
至って自然なやり取りですよね。
しかし後に、新しい考え方が出てきました。
「エッジAI」の登場です。
エッジ AI
エッジ AIとは、IoT機器やセンサーなどの端末にAIを搭載し、端末のみで学習・推論を行う技術。
エッジとは「端」という意味で、「端だけで処理を完結させるAI」ということになります。
従来はクラウドAIのように、端末(IoT機器・センサー)で処理した情報を都度クラウドに送信して処理していました。
これだと、通信コストや速度の問題、通信のセキュリティなどの問題が出てきてしまいます。
そこでクラウドと通信せず、なるべく端末内だけで処理を完結させることが目的。
通信が極力減るため、次のようなメリットがあります。
・高速・低遅延処理が可能
・通信コストの削減
・通信時のセキュリティの危険性が減る
しかし、端末にニューラルネットワークを導入するということは、計算処理性能も当然低くなってしまいます。
そこで、以下のようなネットワークの軽量化手法が考えられました。
・蒸留
・量子化
・プルーニング
それぞれ見ていきましょう。
蒸留
りけーこっとんの記事を通してみてくださっている方は、何回か登場しているかもしれませんね。
蒸留とはすでに学習してあるモデルを使用し、より軽量なモデルを生み出すこと。
学習済みモデルに与えた入力と、それに対する出力を学習データとします。
よく似た手法に転移学習・ファインチューニングなどもありましたので、詳しくは以下をぜひご覧ください。

本記事では、モデル圧縮手法として紹介しています。
エッジAI(前章参照)はクラウドのような計算能力は無いので、モデルを軽くすることが重要なんですね。
そこで「量子化」「プルーニング」という他の圧縮手法も紹介したいと思います。
量子化
量子化とは、パラーメータなどの数値をより小さいビットで表現することで、モデルの軽量化を図る手法のこと。
よく使われるライブラリなどでは32ビットが一般的。
これでは情報量が多いので、8ビットなどに少なくします。
するとネットワークの構造を変えなくても、モデルを圧縮できるんですね。
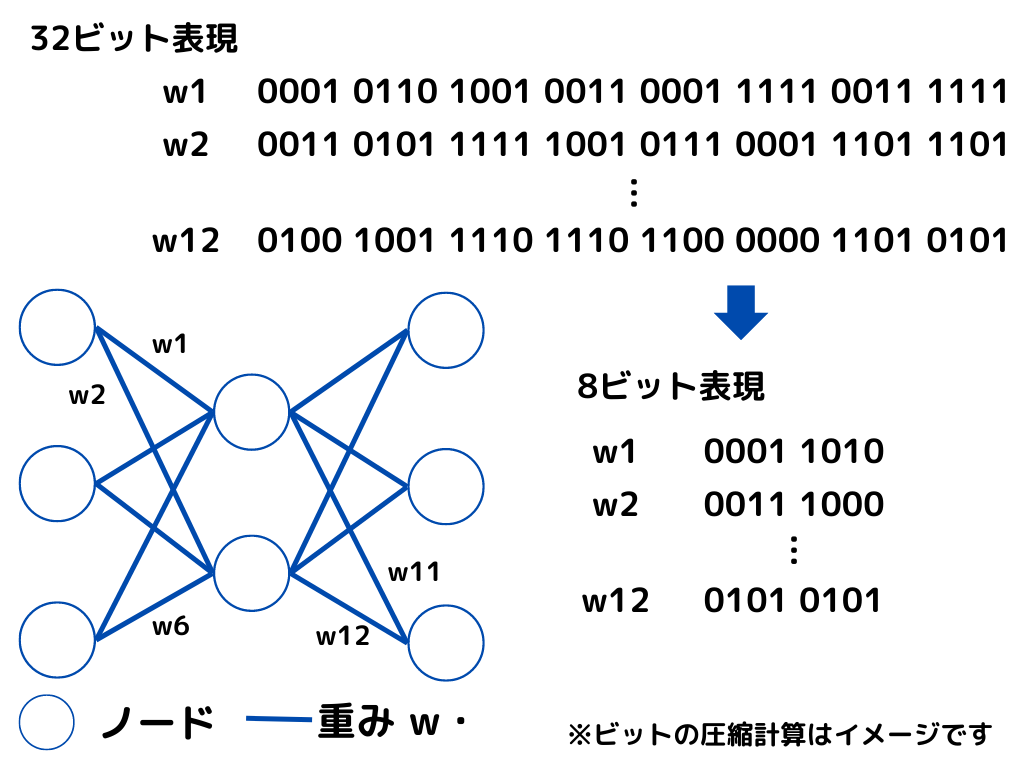
上記のイメージのように、大分数字が圧縮されましたね。
明らかにデータ量が少なくなったことが分かると思います。
ただし表現できる数字が少なくなる分、もちろん精度は落ちるので注意が必要。
前回の記事「音声処理①」で出てきた「量子化」と混同しないように、注意してください。
(同じ名前なのでややこしいですよね)
プルーニング
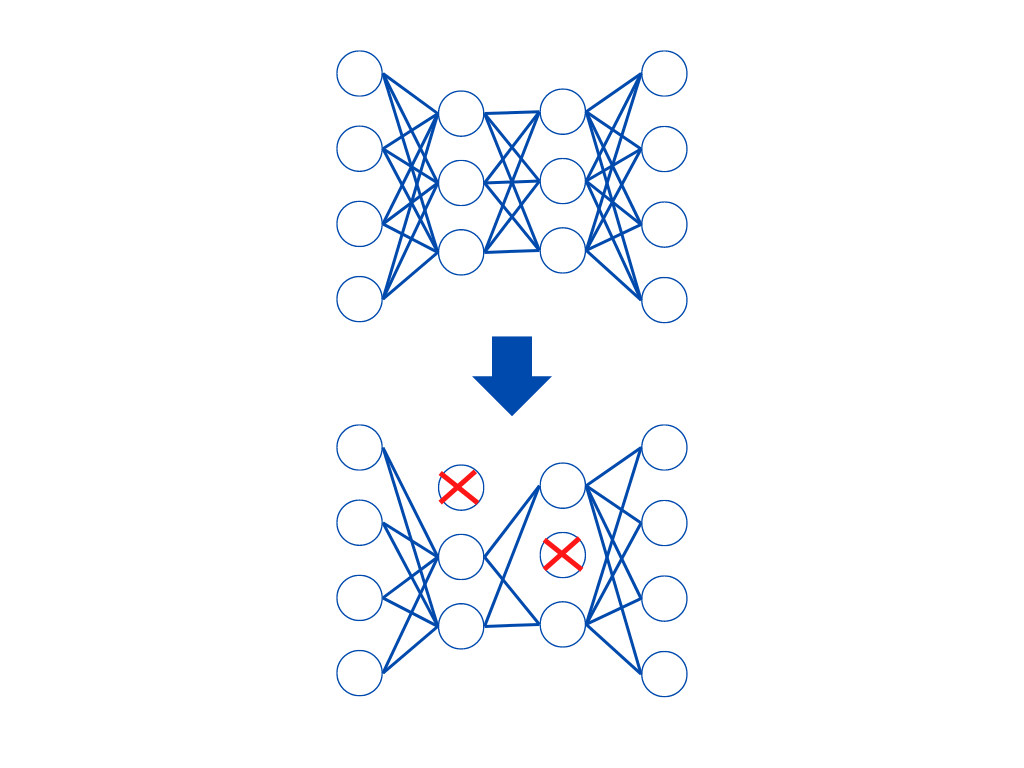
プルーニングとは、隠れ層にあるノードで重みが小さい箇所の接続を永久に削除する手法。
ニューラルネットワークには、ノード(下図:〇)とエッジ(下図:一)があるんでしたね。
すべてのノードを使うとデータ量が多いです。
そこで重みが小さい(あまり結果に影響しない)ノードを削除することで、軽量化を図ります。
似たAI関連の用語としてドロップアウトがあります。
ドロップアウトはモデルの予測精度を上げるための方法。
何回か同じ構造のネットワークで学習する際に、ランダムにノードを削除しますが、重みなどは考慮しません。
また、複数回の学習で削除するノードは毎回異なります。
対してプルーニングは、モデルを軽量化するための手法。
重みが小さいノードを削除し、そのノードが再び使われることはありません。
まとめ
今回は大項目「ディープラーニングの手法」の中の一つ「モデルの解釈性・軽量化」についての解説でした。
本記事をまとめると以下の3つ。
・CAM
・Grad-CAM
・LIME
・SHAP
・クラウドAI
・エッジ AI
・蒸留
・量子化
・プルーニング
以上が大項目「ディープラーニングの概要」の中の一つ「モデルの解釈性・軽量化」の内容でした。
ディープラーニングに関しても、細かく学習しようとするとキリがありませんし、専門的過ぎて難しくなってきます。
そこで、強化学習と同じように「そこそこ」で理解し、あとは「そういうのもあるのね」くらいで理解するのがいいでしょう。
そこで以下のようなことが重要になってくるのではないかと。
・ディープラーニングの特徴(それぞれの手法はどんな特徴があるのか)
・それぞれの手法のアルゴリズム(数式を覚えるのではなく、何が行われているか)
・何に使用されているのか(有名なもののみ)
ディープラーニングは様々な手法があるので、この三つだけでも非常に大変です。
しかし、学習を進めていると有名なものは、何度も出てくるので覚えられるようになります。
後は、新しい技術を知っているかどうかになりますが、シラバスに載っているものを押さえておけば問題ないかと。
今回でようやく「ディープラーニングの手法」の章が終了!
次回は「ディープラーニングの社会実装に向けて」の「AIと社会~データの収集」に触れていきたいと思います。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント