

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「ディープラーニングの概要」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの概要」の内容。
その中でも「ニューラルネットワーク」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
今回はディープラーニングの概要ということもあって、ディープラーニングの基礎的な内容。
ここを理解していないと、ディープラーニングがどういうものかを理解できません。
ここから先の学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
今回はディープラーニングの主な枠組みや、基本的な用語を押さえていきたいと思います。
今までの記事で、見たことある単語も出てくるとは思いますが、復習の意味も兼ねて触れていきますね。
単純パーセプトロン
単純パーセプトロンとは、入力層と出力層の二層のみからなるニューラルネットワークのこと。
全てのディープラーニングの基礎となる考え方です。
線形分類しか行うことができません。
単純パーセプトロンのイメージ図は以下のような感じ。

ニューラルネットワークとは「教師あり学習」の一種類でした。
つまりディープラーニングの位置づけとしては、以下の図のようなイメージになります。

このように「教師あり学習」の中の「ニューラルネットワーク」の中の「ディープラーニング」という位置づけが基本です。

多層パーセプトロン
多層パーセプトロンとは入力層と出力層に加えて、一層以上の「隠れ層」をもつニューラルネットワークのこと。
イメージとしては以下の図の通り。
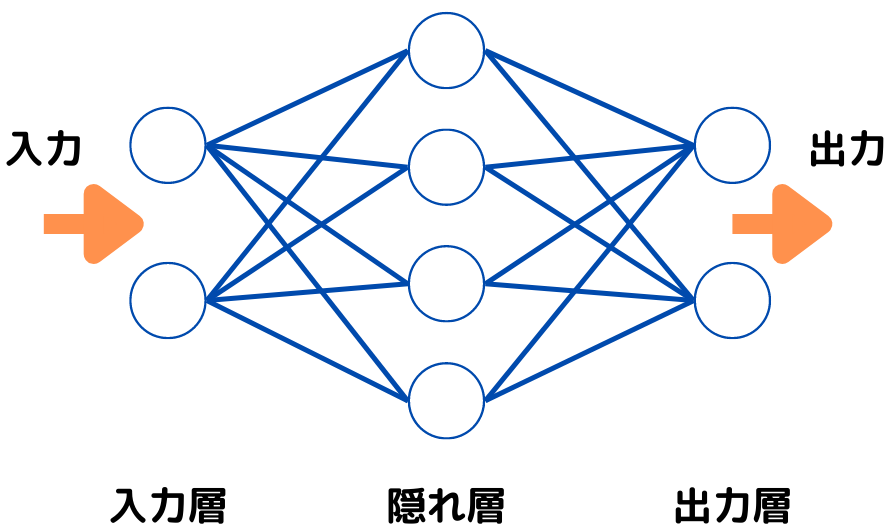
単純パーセプトロンの構造に、「隠れ層」が追加されていますね。
隠れ層に関しては、以下で触れます。
隠れ層
隠れ層とは、入力層と出力層の間に挟まれた層のこと。
先ほどの図で見たとおりですよね。
隠れ層には、入出力を対応させる関数が入っています。
これを活性化関数といいます。
多層パーセプトロンの図で例を見てみましょう。
今回の例では活性化関数を「入力が0未満で0、0以上で1」を返す関数とします。
データの流れ的には左から右へ流れていきます。
なので、まず真ん中の隠れ層には、左の入力層からデータが来ますよね。
隠れ層に「3」というデータが入ってきたなら、活性化関数を元に「1」という出力を右へ、
隠れ層に「-1」というデータが入ってきたなら、活性化関数を元に「0」という出力を右に伝えます。
活性化関数には、いろんな種類があり、詳しくは後の記事で触れますね。
ディープラーニング
ディープラーニングとは、ニューラルネットワークの隠れ層の数を増やしたもの。
別の言い方をすると、層を深くしたものと言えます。
隠れ層の数、というのは以下の図のように二種類あります。


単純パーセプトロンだと、線形分類しかできませんでした。
単純に1層の隠れ層だけだと、入力層のデータを一回しか変換しないので、分類に限界があるのは想像できるのではないでしょうか。
ということは「隠れ層をたくさんにすれば、もっと複雑な分類もできるでしょう」となりますよね。
そこで隠れ層をたくさんにすることで、実際により複雑な分類ができるようになりました。
なので画像分類などの、膨大な情報量かつ複雑な分類を可能にしたというわけですね。
信用割当問題
信用割当問題とは、ニューラルネットワーク内のどのパラメータ(重み・バイアス)が出力層での正解に貢献しているのか、誤差を生じさせているのかが分からない問題のこと。
この問題は、出力が間違っていた時に発生します。
出力が間違っていると、それを修正するために原因を探しますよね。
この原因を探すときに「どのパラメータが出力層に影響してるのか」を知りたいことがあります。
しかし信用割当問題が発生してしまうと、原因が分かりません。
そこで、この問題を解決するために生まれたのが誤差逆伝播法です。
誤差逆伝播法
誤差逆伝播法とは、パラメータを出力層に近い順から連鎖的に求める方法。
出力と正解ラベル(教師データ)との誤差を埋めるために行います。
誤差逆伝播法のイメージは以下のような感じ。

このようにデータの流れとは逆に伝わってパラメータを求めているように見えるため、「誤差逆伝播法」と呼ばれるようですね。
勾配消失問題
勾配消失問題とは誤差逆伝播法において、隠れ層を重ねるごとに学習が進まなくなってしまう現象のこと。
教師あり学習の誤差を最小化する際に、「勾配」という微分すると得られるものを求めます。
「勾配」というのは「関数の傾き」で、勾配の最小値が誤差の最小値です。
つまり、一つ一つのパラメータを求めるたびに微分をして、それを掛け合わせていくわけですね。
しかし微分して1以下になってしまうようだと、掛けるたびに小さくなってしまいます。
0に近づいてしまうことで、うまくパラメータ更新ができなくなってしまい、学習が進まなくなるというわけですね。
まとめ
今回は大項目「ディープラーニングの概要」の中の一つニューラルネットワークについての解説でした。
本記事をまとめると以下の3つ。
・単純パーセプトロン
・多層パーセプトロン
・隠れ層
・ディープラーニング
・信用割当問題
・誤差逆伝播法
・勾配消失問題
以上が大項目「ディープラーニングの概要」の中の一つニューラルネットワークの内容でした。
ディープラーニングに関しても、細かく学習しようとするとキリがありませんし、専門的過ぎて難しくなってきます。
そこで、強化学習と同じように「そこそこ」で理解し、あとは「そういうのもあるのね」くらいで理解するのがいいでしょう。
そこで以下のようなことが重要になってくるのではないかと。
・ディープラーニングの特徴(それぞれの手法はどんな特徴があるのか)
・それぞれの手法のアルゴリズム(数式を覚えるのではなく、何が行われているか)
・何に使用されているのか(有名なもののみ)
ディープラーニングは様々な手法があるので、この三つだけでも非常に大変です。
しかし、学習を進めていると有名なものは、何度も出てくるので覚えられるようになります。
後は、新しい技術を知っているかどうかになりますが、シラバスに載っているものを押さえておけば問題ないかと。
次回は「ディープラーニングの概要」の「ディープラーニングのアプローチ」に触れていきたいと思います。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント