

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「人工知能分野の問題」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「人工知能分野の問題」の内容。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
本記事の範囲は問題数としては少ないものの、合格に向けては必須の基礎知識になります。
ここを理解していないと、機械学習やディープラーニングがどういうものかを理解できません。
ここから先の学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
人工知能分野での問題に関する内容が多くなってしまってので、記事を二つに分割してお届けしようと思いますね。
ハノイの塔
ハノイの塔とは簡単なパズル問題のこと。
詳細は以下の通りです。
○三本の杭と中央に穴の空いた円盤がある。同じ大きさの円盤はない。
○始めは左の杭に上から小さい順に円盤が重なっている。
○円盤を動かせるのは一度に1つで、小さい円盤の上に大きな円盤はおけない。
○全ての円盤を右の杭に最小の数で移動するには?という問題
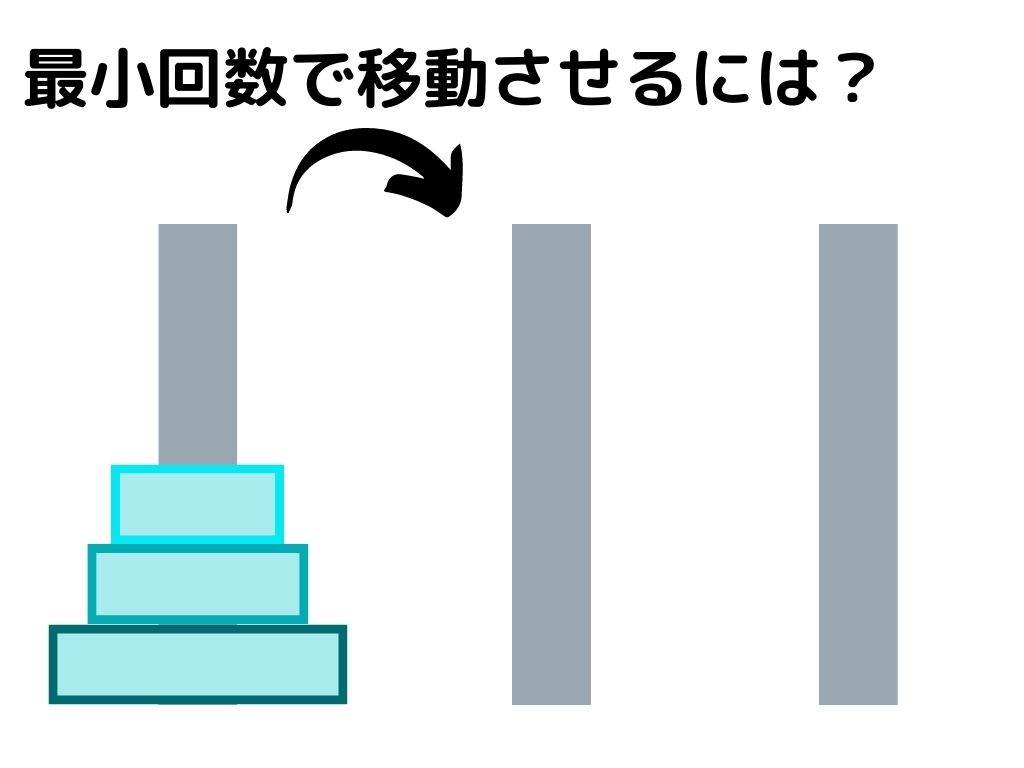
この問題、構造自体は簡単ですが、円盤の枚数が増える毎に指数関数的に手数が増えてしまいます。
直線的な変化ではなく、指数的な変化の問題の代表例として、よく挙がるようですね。
モンテカルロ法
モンテカルロ法とはボードゲームにおいて最善手を評価するための方法の1つ。
次の一手を決めるときに、地道に打てる手それぞれで何回もプレイアウトします。
その中で一番勝率が高かった手を選ぶ手法のことですね。
AIがボードゲームで勝つために、検討されていた方法のようです。
ローブナーコンテスト
ローブナーコンテストとは、聴覚・視覚が人間と区別が付くかどうかを競い合うコンテスト。
どうやって競い合うのかと言えば、チューリングテストです。
チューリングテストの結果で「人間が、どれくらいAIと区別できたか」を判定します。
聴覚・視覚共に30%以上の区別がつかないと授与される「ローブナー賞金賞」は、未だに取られたことがないようですね。
中国語の部屋
中国語の部屋とは、以下のような問題です。
1.中国語が分からない人を小部屋に閉じ込め、小さな穴から紙だけやりとりできる
2.外から中国人が中国語で質問を紙に書いて入れる
3.中の人はマニュアルに従って、答えを探す(中国語は理解していない)
4.外の人は正答であれば「中の人は中国語を理解してる」と思ってしまう
つまり中の人はマニュアルに従って答えているだけなのに、外の人は「中国語を理解している」と感じるようです。
これがAIの問題とどう関係するの?と思った方。
AIの中で行われていることは何だったでしょうか。
ひたすら計算を繰り返している、プログラムなんです。
なのでAIはマニュアルに従っているだけとも言えますよね。
「AIは人語を理解している」と思ってしまう、と考えると身近に思える人もいるのでは?
チューリングテストを否定した論文で、書かれていたようです。
機械翻訳
機械翻訳とは、違う言語の翻訳を機械が行ってくれること。
Google翻訳とかあるので、イメージしやすいかと思います。
そして、機械翻訳にはアルゴリズムが数種類あります。
歴史の中で、だんだん高性能なやり方が開発されていきました。
古い順に並べると以下の三つ。
・ルールベース機械翻訳
・統計学的機械翻訳
・ニューラル機械翻訳
一つずつ見ていきましょう。
ルールベース機械翻訳
ルールベース機械翻訳とは、各言語の「文法」を人手で入力して、変換した手法。
1954~1970年にジョージタウン大学で研究されたようですね。
文法を人手で入力していくので、単純に時間がかかりますし、大変です。
統計学的機械翻訳
統計学的機械翻訳とは、ある言語とその対訳を学習させて、モデルとするもの。
1990年代にIBMが提唱し始めたやり方です。
統計学を用いて、原文と訳文を機械に学習させていたようですね。
ニューラル機械翻訳
ニューラル機械翻訳とはニューラルネットワークを用いている機械翻訳のこと。
名前の通りですね。
これが現在最も使われている手法です。
統計学的機械翻訳と手法は同じで、ニューラルネットワークを用いたことで、飛躍的に精度が向上したようです。
特徴表現学習
特徴表現学習とは、特徴量の加工・抽出まで学習器が行うこと。
ディープラーニングがこれに当たりますね。
自然言語処理等の分野で使われるようです。
特徴量の加工・抽出は分析者にとって、非常に大変な作業のようですね。
これを学習器が行うとなると、スピードも精度も上がります。
まとめ
今回は大項目「人工知能分野の問題」についての解説、第二弾でした。
本記事の重要なことは以下の3つ。
・モンテカルロ法
・機械翻訳には数種類のやり方がある
・特徴表現学習
以上が大項目「人工知能分野の問題」の内容でした。
結構長い記事になってしまいましたが、これまでの記事で周辺知識の基礎は一通りできたと思います。
次からはいよいよ、前半のメインパート「機械学習の具体的な手法」に入っていきます。
たくさんの手法や、それを突っ込む内容になると思いますが、分かりやすい記事にしますね。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~

続きは以下のページからどうぞ!




コメント