

※本記事はアフィリエイト広告を含んでいます



どーも、着実に入社が近づいてきて、楽しみと不安が入り交じっているりけーこっとんです。
このデータサイエンティストとして働く時が迫っている中、りけーこっとんは統計学やプログラミングの専門家ではありません。
かろうじて理系だったので、高校数学くらいまでの知識しかないのが現状…
そこで今回紹介する「データ分析のための統計学入門」を読み始めました。
今回はその第一章のまとめ・解説をしていきたいと思います。
「データ分析のための統計学入門」 とはアメリカのデータサイエンティストの方々が統計について、統計をどう実際の分析や現場に利用していくかを執筆したもの。
「アメリカの人が書いたって事は、英語…?読める気がしない…」
という方も日本語訳があるので大丈夫!(日本語無料版には、練習問題の解説が付いていません)
これから統計を学ぶ人たち、データサイエンティストを目指す人たちは、読んでおいて損はないと思います。
日本統計協会も「大学で初めて統計学を学ぶ学生、ビジネスでデータ分析をしている社会人のために
書かれた豊富で実践的な練習問題を含む最適な統計学入門書」というお墨付き。
何よりも魅力的なのは、無料公開という点!
統計学についてド素人な自分にとって、どの書籍を買ったら良いか分からなかったので、すごくありがたいです。
下のURLから、無料公開されているページに飛べます。
http://www.kunitomo-lab.sakura.ne.jp/2021-3-3Open(S).pdf
今回の記事は「読む前にさらっと概要を知りたい」という人向け。
より厳密な内容、詳しい内容は原文を読んで貰いたいと思うので、ここでは概略を絵を使ってさらっていきたいと思います。
では早速始めていきましょう。
第一章で学んだこと
第一章はデータ分析への導入。
ここで今回りけーこっとんが学んだ内容はこんな感じです。
・データ分析、統計が実際の現場にどう使われているか
・統計、分析のやり方の基本と簡単な概略
自分は統計の知識が全くなかったので、ここから始めてもらえることは非常にありがたかったです。
第一章は
「なぜデータ分析って必要なの?」→「それは実際にこういう事にも使われていて、便利だからなんだ」→「じゃあ、こんな便利なものを詳しく扱う基礎を説明するよ」
という感じで進むので入りやすい。
では詳しく見ていきましょう。
1.1から1.4の解説
1.1 事例研究:ステントにより発作を抑える?
まず心臓発作をステントという人工装置で抑えられるのかという例を元に、統計データ・分析がどれだけ大きな影響を与えているかを示しています。
このブロックは
「なぜ統計分析をするの?」→「それは心臓発作を抑える道具の効果を見ることに使われるように、医療の現場など様々な場面で役立っているからなんだ」
ということを伝えている感じですかね。
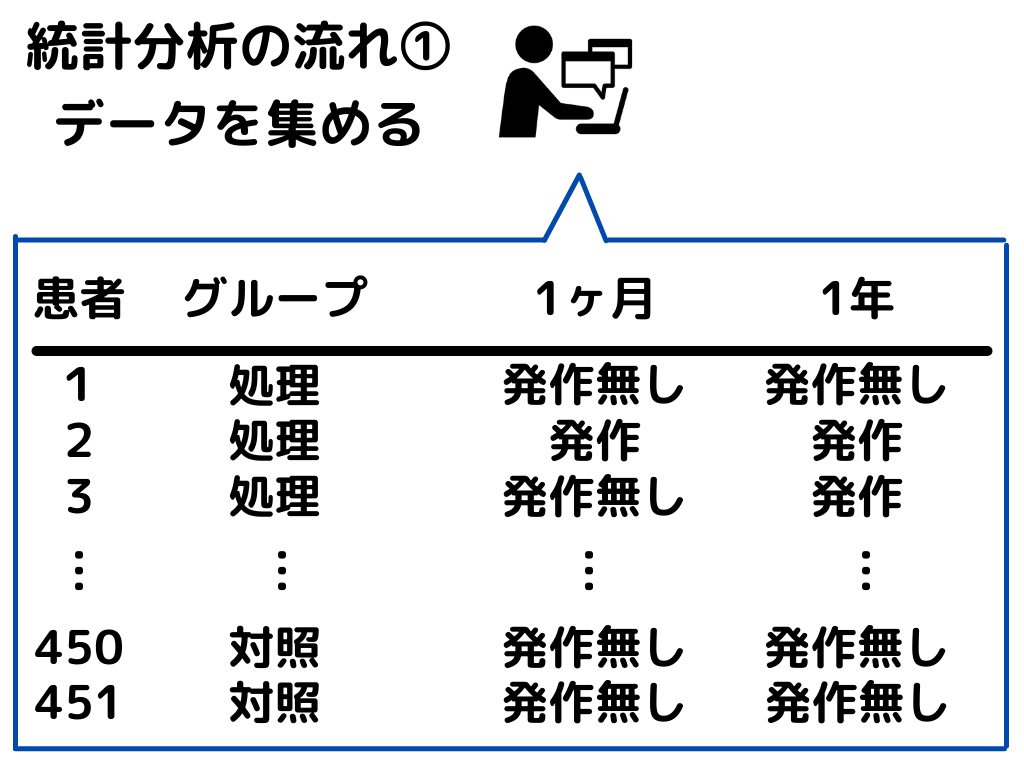

このように一人一人のデータと、そのデータの統計的分析によって、ステントが効果的だったかが分かりますよね。
ここで自分が新しく知ったキーワードは処理群と対照群。
処理群:実験をする際に、処理を施す集団のこと。今回の例だと、ステント治療を受けた人たち。
対照群:実験をする際に、処理を施さない集団のこと。今回の例だとステント治療を受けなかった人たち。
1.2 データの形式
このブロックでは「前のブロックでデータ分析が重要だとわかったと思うから、その基礎を説明していくね」という部分です。
データを集めるときは、例えばこんな感じでエクセルを使うなどして表を作ります。
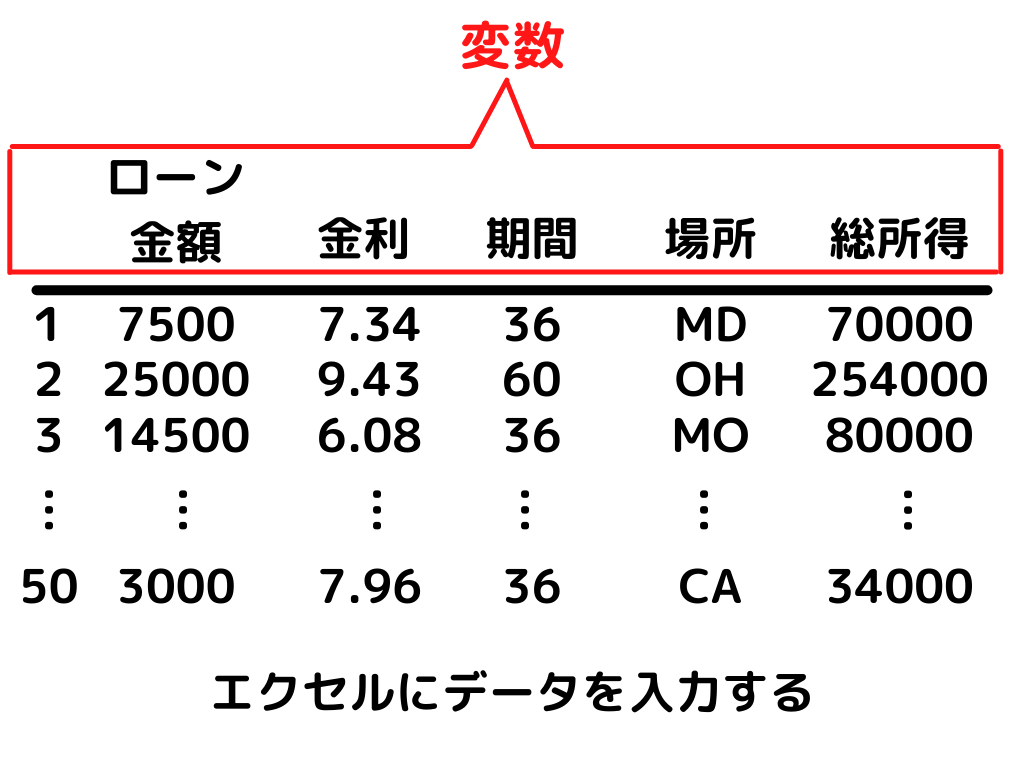
この表でいう「金額、金利、期間、場所、総所得」は変数といいます。
「場所も変数…?」
って思いますよね。
変数って「数」って言ってるのに、数に関係なさそうな要素でもデータによって変わるものであれば、「変数」と呼ぶようですね。
この変数の種類にはこんなものがあります。
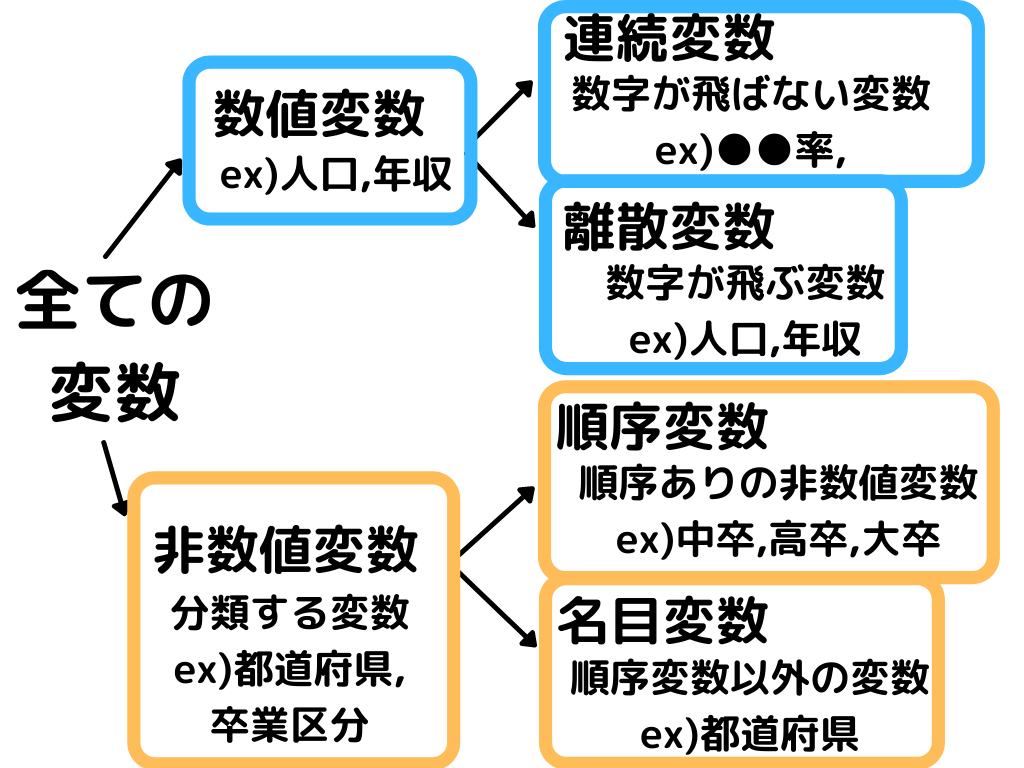
この変数同士の関係を見ることで「その変数同士に関係ってあるの?ないの?」が分かります。
じゃあここで「そもそもどうやってそのデータを集めるの?」っていう疑問が出てきますよね。
データの集め方には観察研究と統計的実験の二種類があります。
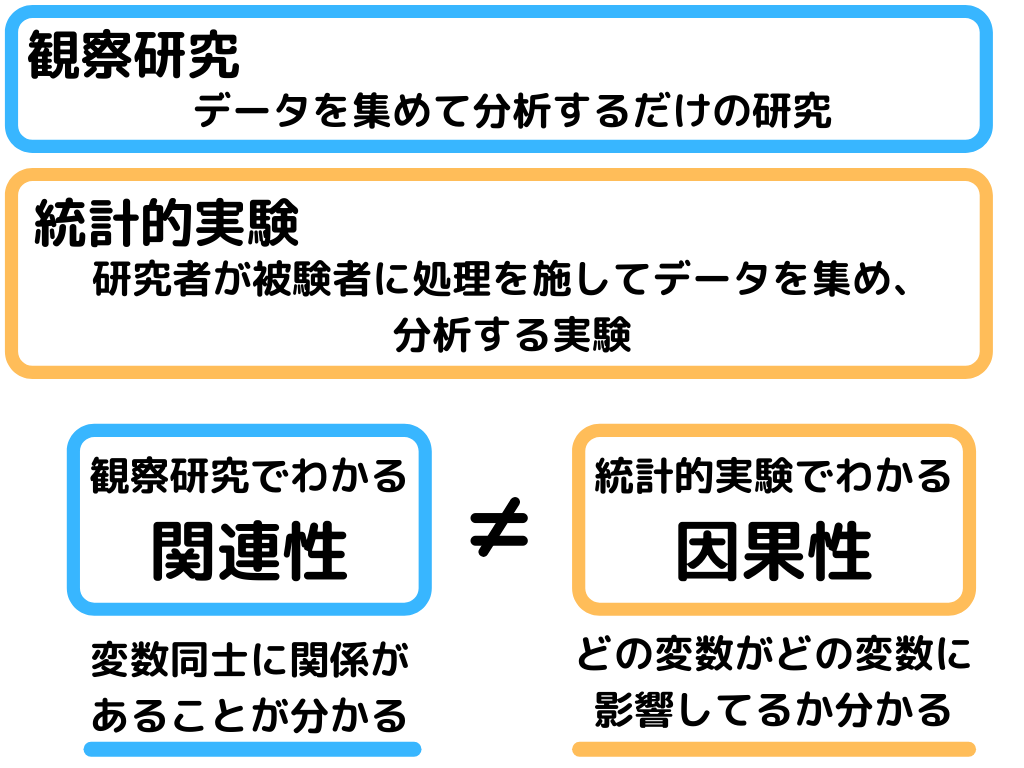
自分は正直、観察研究と統計研究、同じものだと思ってました…
研究者がなにか処置を施せば「統計的実験」になるみたいですね。
そして「関連性」と「因果性」の違いもむずい…
「関連性」は要素1・2・3どれも4に影響する可能性はあるけど、今回の研究では1と4に関係があることが分かった、という感じ。
「因果性」は要素1が4に影響することが分かる、という感じですかね。
1.3 サンプリングの原理と方法
じゃあ、研究をするための準備段階として何をするのか。
それが母集団を決めて、標本を集める、です。(恥ずかしながら、この定義もあいまいでした)
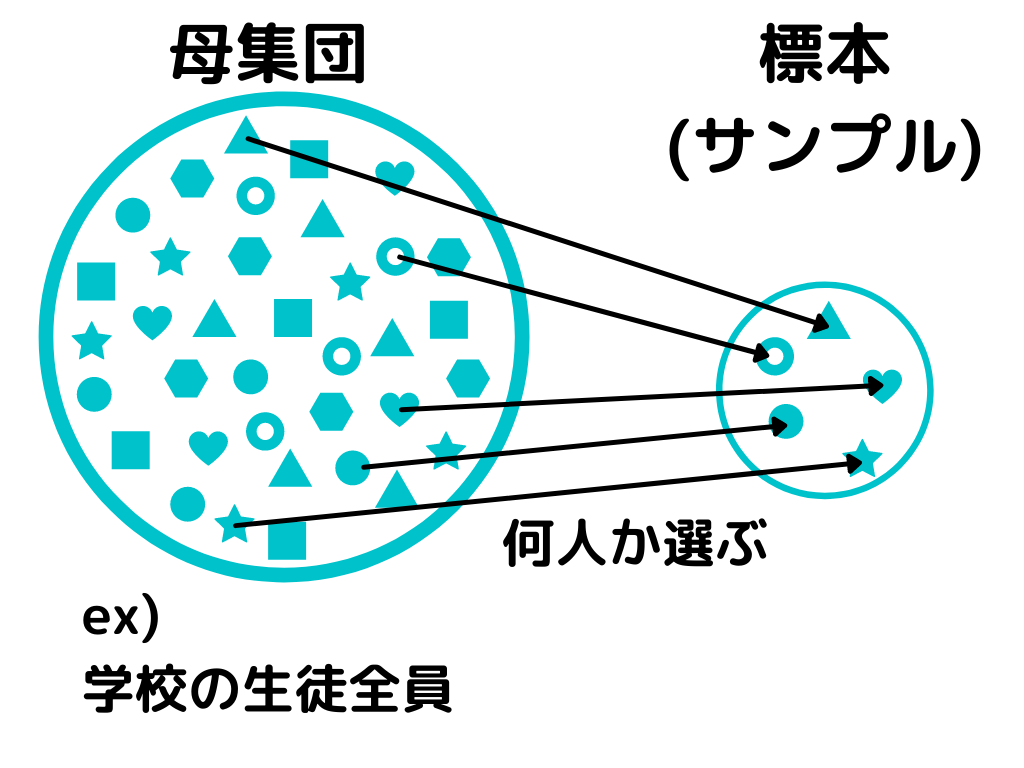
こうやってデータを集めたら、表にまとめてデータ分析をして変数(1.2参照)の関係性を見ていきます。
この関係性を見る時に、交絡変数に注意!
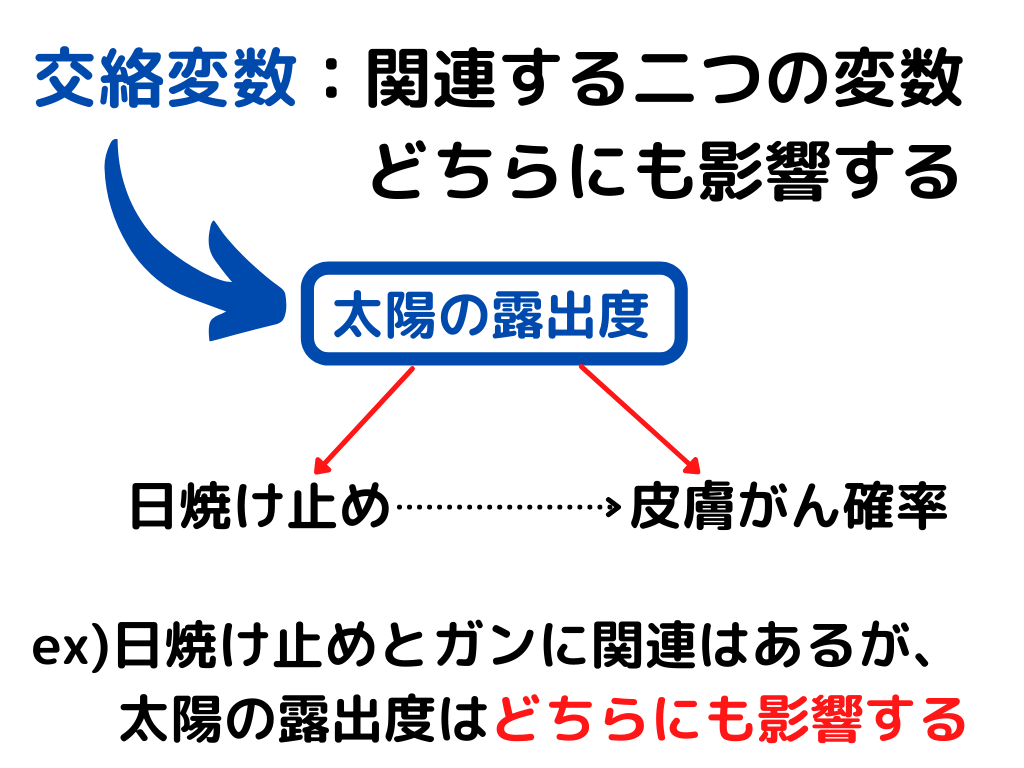
こうなってしまっては皮膚がんになる確率に影響を及ぼしているのは「日焼け止め」なのか「太陽の露出度」なのか分からないですよね。
観察研究はこういうことが多いので、仮説を立てたり、関連性を言うだけに使うことが多いようです。
このブロックの最初で母集団から標本集めるといいましたが、統計的実験でのサンプルの取り方は4つです!
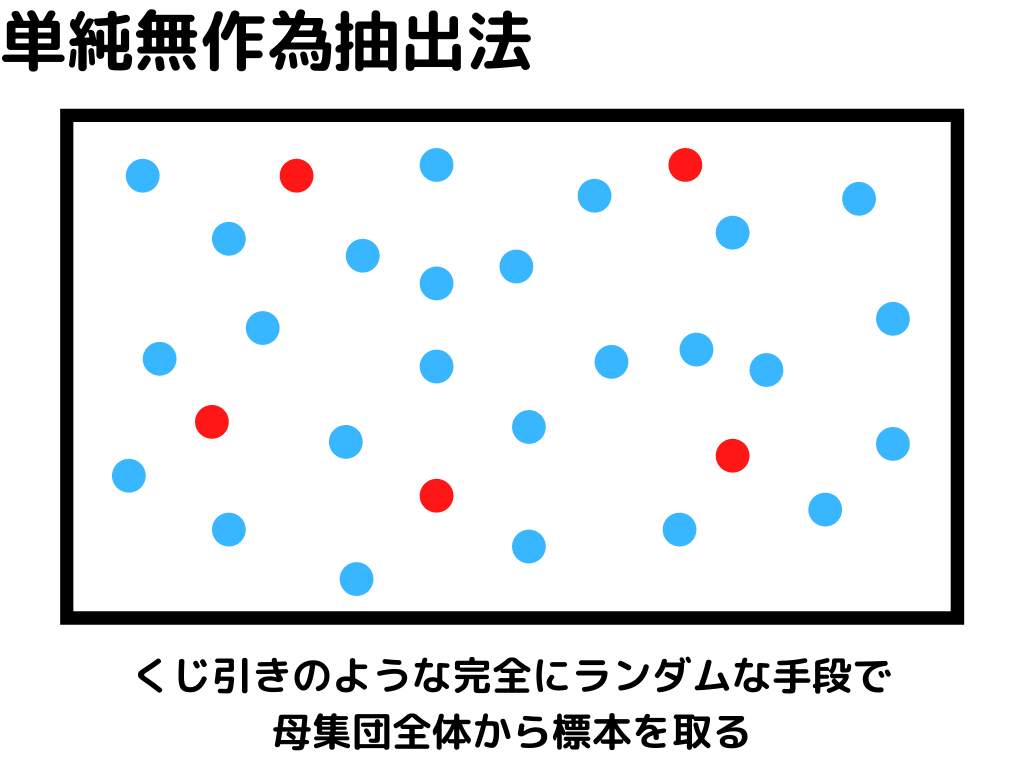
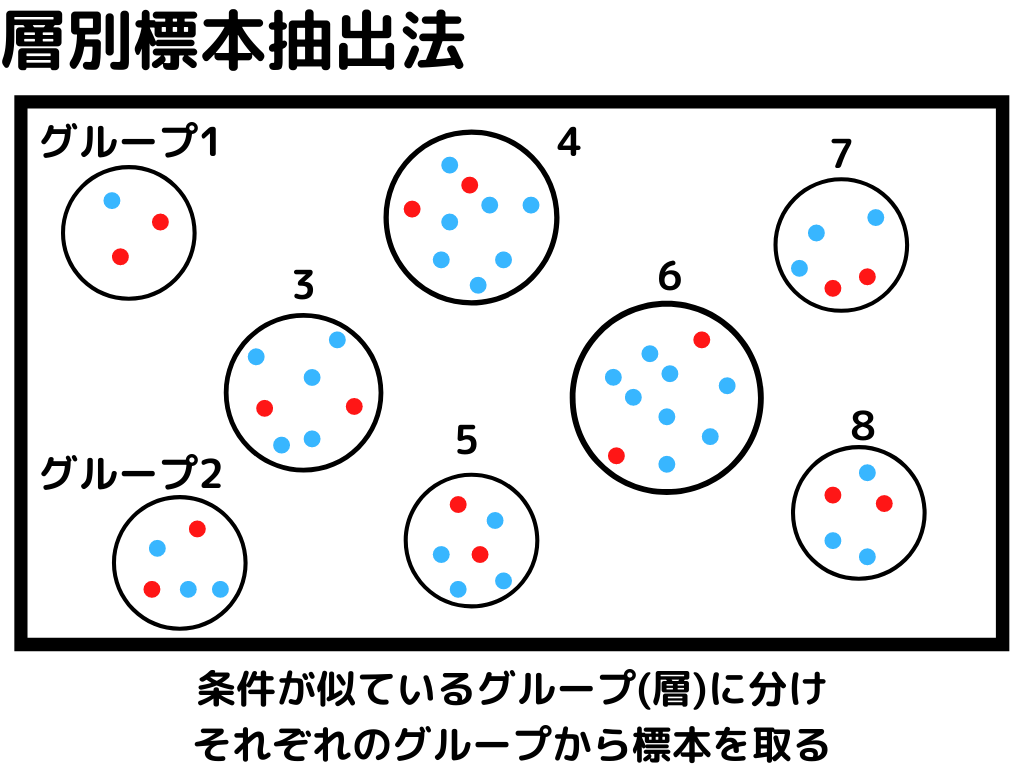
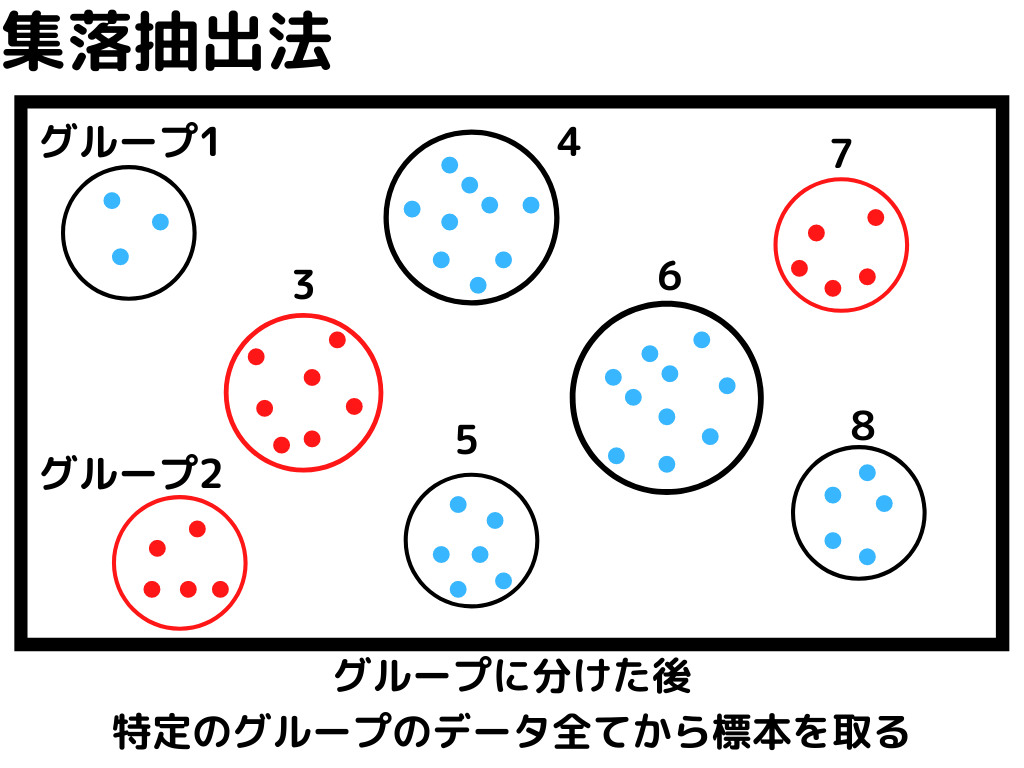
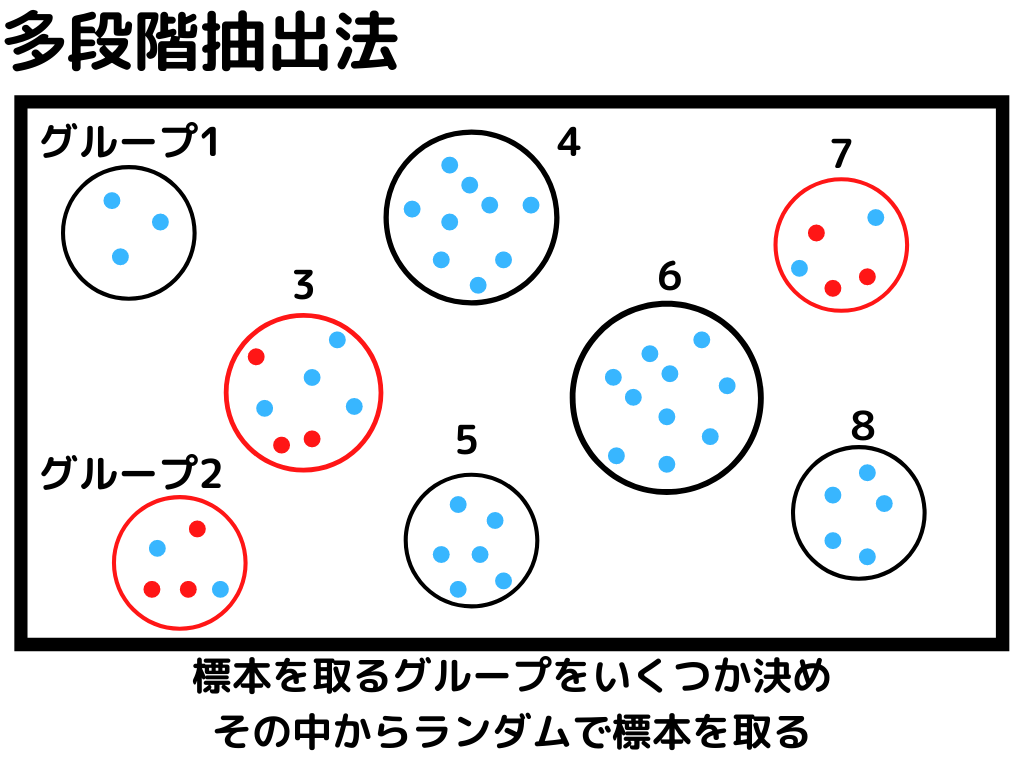
統計的実験の標本集めは「母集団からちゃんとバラバラに標本が取れているか」が大事。
偏って集めてしまうと、正確に関係性が見えないことが多々あるからです。
なので、実験や母集団の特徴によって、この四つの方法を駆使するようですね。
1.4 統計的実験
ここまで読んでりけーこっとん的に腑に落ちない部分がありました。
それは「統計的実験の全体的な流れを教えてほしい」。
そう思ったところにこのブロックがありました。
統計的実験の流れはこんな感じ。
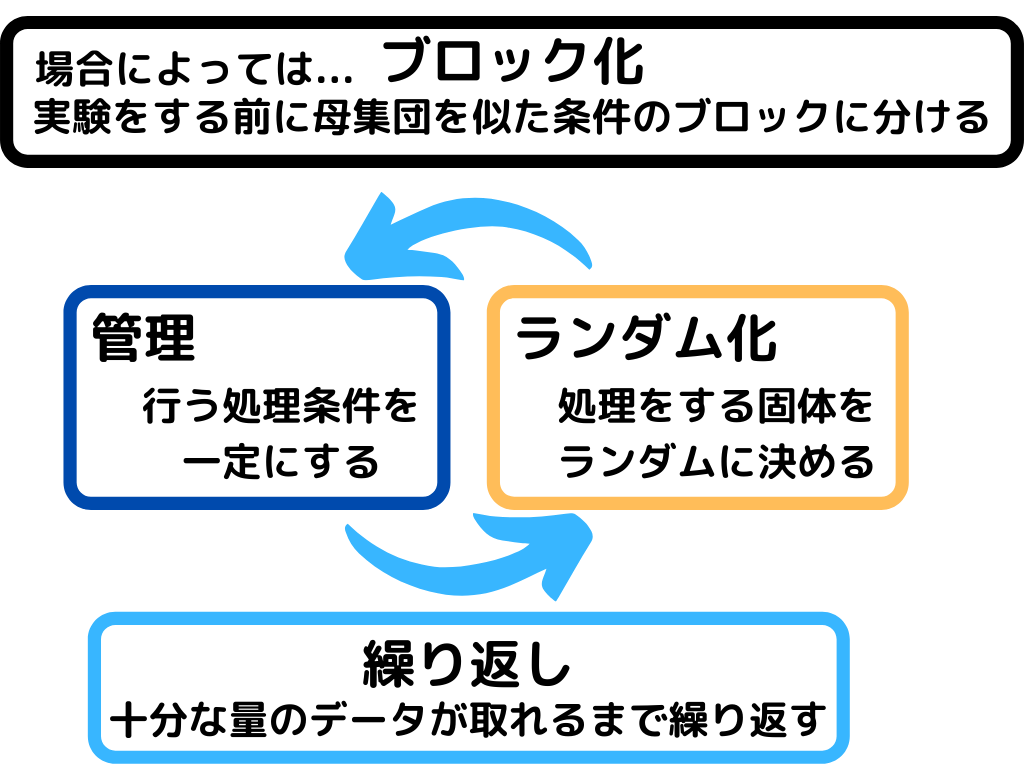
これは母集団と標本(1.3参照)を集める際の流れですね。
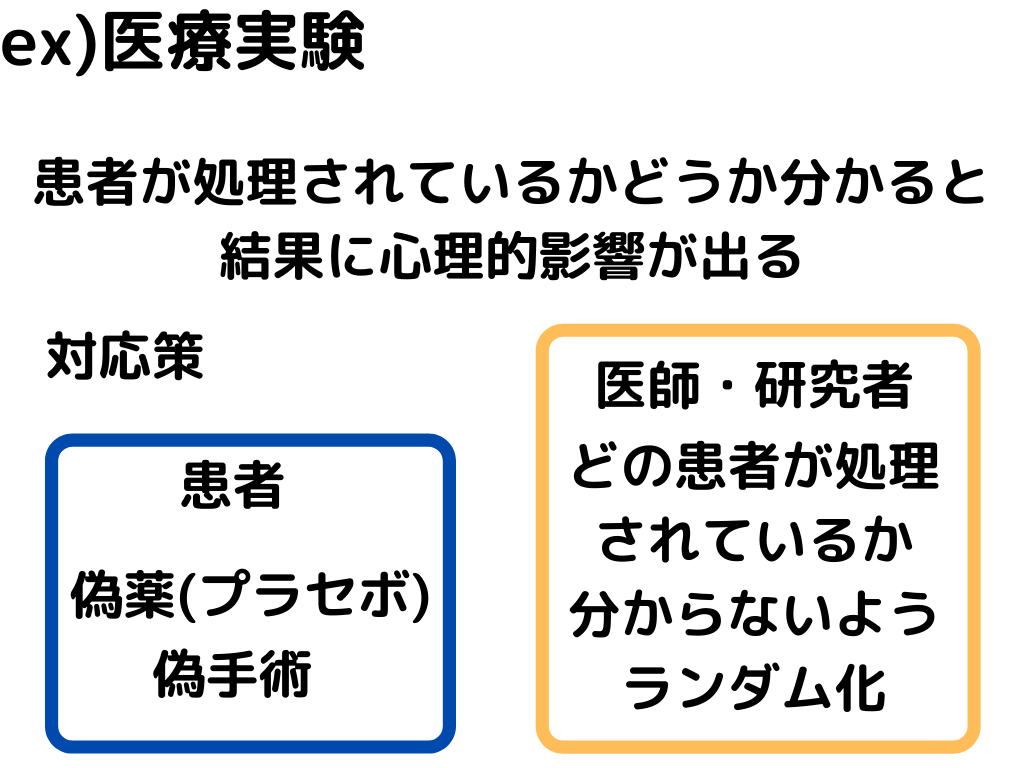
また、データの偏り(バイアス)を無くすための方法の一例としてこんなやり方があるようです。
まとめ
第一章の内容をまとめるとこんな感じ。

今回は「データ分析のための統計学入門」の第一章を簡単にまとめました。
自分が読んでいて思ったことは、初心者からデータ分析関係やデータサイエンティストを目指す人は、本書から読んだほうが効率がいいという事。
実際の例と図解を用いながら丁寧に進めてくれるので、分かりやすさが違います。
データ分析の専門書の1冊目としては最適だと思います!
もちろん専門書なので、もっと軽くわかりやすくという方は漫画版や薄い冊子のものがいいですね。
自分もまだまだデータ分析に関して初心者なので、本書を読んで学習を進めていきたいです。
これからも自分の学習の進捗に合わせて投稿しますね。
春からのデータサイエンティストに向けて一歩前進!
ではまた~
続きの第二章は以下のページからどうぞ!



コメント