
G検定|機械学習の具体的な手法|ε-greedy方策・UCB方策などを分かりやすく解説

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。
なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


目次
大項目「機械学習の具体的な手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「機械学習の具体的な手法」の内容。
その中でも「強化学習」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
本記事の範囲は、合格に向けては必須の基礎知識になります。
これから先の機械学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
強化学習に関する内容が多くなってしまったので、記事を複数回に分割してお届けしようと思いますね。
強化学習の概要
強化学習とは、ある環境下で目的を達成するために、一連の行動結果の報酬を最大化するように学習する機械学習の手法こと。
具体的な手順としては以下の通り。
1.現在の「環境」から「状態」を観測する
2.「状態」から「方策」に基づいて、「行動」する
3.「行動」により変わった次の「状態」と「報酬」を付与する。
4.1に戻る
このように「教師あり学習」「教師なし学習」とは異なる、三種類目の機械学習手法です。
「方策」とは簡単に言うと、エージェント(ロボットなど学習主体)の行動選択のルールのこと。
「方策」に関しては、「方策反復法」のところで詳しく解説します。
イメージとしては以下の様な感じ。
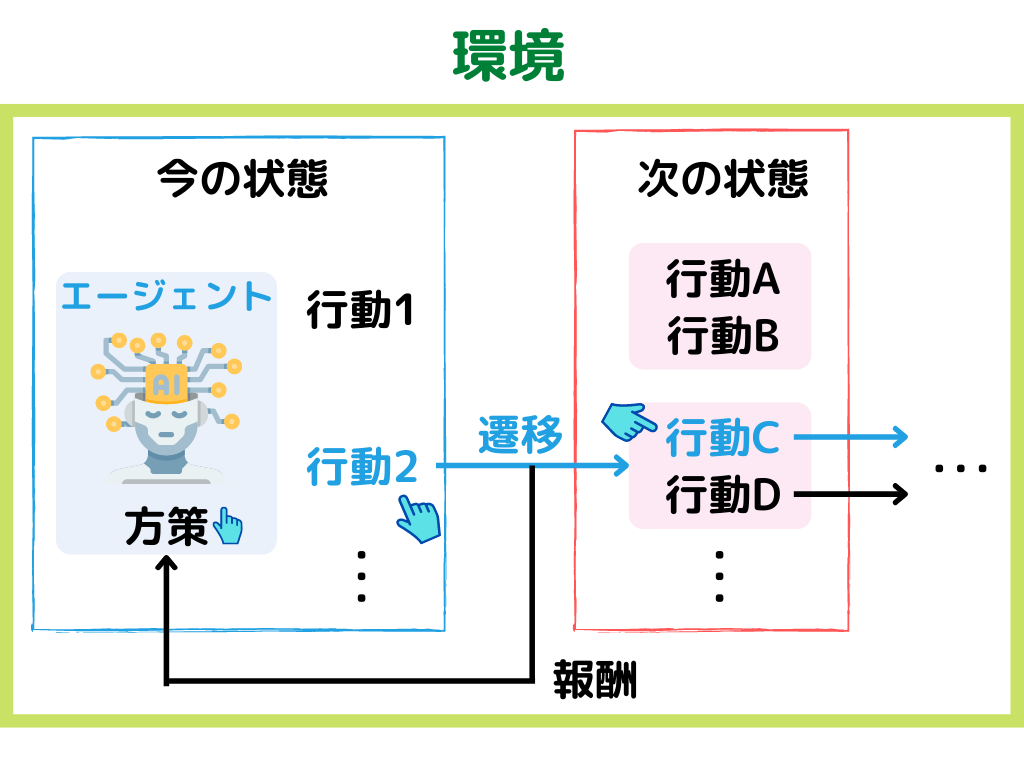
上の例では、「方策」で行動2を選んだ後、行動Cを選ぶ、という例です。
前回までは「モデルベース手法」「価値関数ベース手法」「方策ベース手法」の3つを扱ってきました。
今回はシラバスに載っているけど、そもそもの数学の話だったり、複数の手法にまたがっている単語について解説していきたいと思います。
バンディットアルゴリズム
バンディットアルゴリズムとは、強化学習でエージェント(学習主体:ロボットなど)の行動選択の仕方の一種。
強化学習で使用されていることから分かるとおり、どの選択肢(方策)が良いか事前に情報が無くても学習できます。
アルファ碁にも使用されたようですね。
目的は全ての試行における、全報酬の合計値の最大化です。
具体的な手順は以下の通り。
1.まず1回目の試行(囲碁をする、迷路をクリアする)において「方策1」を行う
2.「方策1」の結果、得られる報酬を全て合計する
3.報酬から2回目の試行には、どの「方策」が良いか決める
4.2回目の試行を行う
5.2から繰り返し
このように行動を選択した結果得られる報酬を毎回反映し、次の選択に活かしています。
次の方針を決める時に現在知っている情報から、報酬が最大となる方策しか選ばないことを利用といい、
次の方針を決める時に現在知っている情報以外も知るために、報酬が最大となる方策以外も選ぶことを探索といいます。
このバンディットアルゴリズムには「利用」と「探索」があるように、行動の選び方の具体的な方策が何個かあるんですね。
・greedy方策
・ε-greedy方策
・UCB方策
・ボルツマン方策、softmax方策
シラバスに載っているものもあるので、それぞれ見ていきましょう。

greedy方策
greedy方策とは、最適行動価値関数を最大化するような行動を取る方策のこと。
つまり、「報酬」が最大化されるような方策しか選びません。
先ほど出てきた「利用」のみを行う方針に近いでしょうか。
ε-greedy方策
ε-greedy方策とは、一定確率(ε)で最適な行動以外を取る方策のこと。
greedy方策のように最適な行動のみ選んでいると、別の行動を学ぶ可能性がなくなってしまいますよね。
最適な行動・方策を取るだけが、「目的」を達成するものでしょうか。
ボードゲームとかだと、あえて最適 “ではない” 行動を取ることが勝利に繋がったりしますよね。
このように現実問題に適用するときに、不具合が出てきてしまいます。
この問題に対処するため、εの確率で別行動を取れば、多様な「目的を達成するための行動」が取れるのではないでしょうか。
こう考えられて出てきたのがε-greedy方策です。
UCB方策
UCB方策とは、行動を選択する際に毎回「スコア」と言われる値を算出し、最高値をとる行動を取ること。
「スコア」の部分を計算するときに、「利用」と「探索」がバランス良く行われるような計算を行っています。
単純に方策選択で報酬の最大化を目指してしまうと、1個の「方策」ばかり使ってしまうことになりかねません。
そこで、「選択回数の少ない「方策」も選べるように式を補正しよう」となったのが、「スコア」の式ですね。
ボルツマン方策・softmax方策
ボルツマン方策・softmax方策とは最適な行動外の選択確率がボルツマン分布に従う方策のこと。
名前は二つありますがどちらも同じ意味です。
考え方としてはε-greedy方策に似ているかと。
他の行動を選ぶ確率が、εではなく「ボルツマン分布」から取り出すという手法ですね。
マルコフ決定過程モデル
マルコフ決定過程モデルとは、状態遷移が確率的に生じる動的システムの確率モデルにおいて、マルコフ性を満たすモデル。
つまり今の状態から次の状態に変わるときに、何%はAの状態、何%はBの状態という風に、確率で次の状態が決まること
これを「状態遷移が確率的に起こる動的システムの確率モデル」と言っています。
実はこれ、強化学習の方策と同じ事を言ってることに、お気づきでしょうか?
方策について少し振り返ると、方策とは、
こんな「状態」の時に、次はどう「行動」するのが良いのかを表す確率分布のことでしたよね。
なので機械学習的に言うと、強化学習において「マルコフ性」を満たすものを「マルコフ決定過程モデル」と呼んでいます。
では「マルコフ性」とは何なのでしょうか?
マルコフ性
マルコフ性とは、確率論分野での確率モデルの特性の一種。
その過程の将来の条件付き確率分布が現在状態のみに依存し、過去のいかなる状態にも依存しない特性を持つことです。
ちょっと難しいですよね。
簡単に言っちゃうと、「次の確率分布(方策)は、今の状態からしか影響を受けない」特性です。
実際の確率モデル(囲碁など)は「前々から打っていた手が、後になって効いてくる」事がありますよね。
これは「今の状態からしか影響を受けない」とは言えません。
ただ、最初から実際の世界にも適用できる計算を考えるのも、行うのも大変です。
なので「今の状態からしか影響を受けない」とすることで、計算を簡単にしてるみたいですね。(それでも複雑なので、詳しい式は割愛します)
A3C
A3CとはAsynchronous Advantage Actor-Criticの略。
この名前の通り「Asynchronous」「Advantage」「Actor-Critic」3つの技術を統合したものです。
アルファ碁にも使用されていたようですね。
複数のエージェント(学習主体:ロボットなど)を非同期で並列に学習するのが特徴
3つの技術が統合されているということで、それぞれについて軽く触れておきます。
Advantage
AdvantageとはQ関数更新のやり方の一種。
Q関数更新は基本的に「次のステップの状態や価値関数から今のQ値を計算する」ものでした。
そのQ関数の更新を「1ステップ先だけじゃなく、2ステップ以上先まで動かして更新する」方法
これがAdvantageです。
Actor-Critic
これは前の記事でも出てきました。
覚えているでしょうか?
Actor-CriticとはTD誤差学習の一つであり、行動選択に最小限の計算量しかいらず、確率的な行動選択を学習する手法。
応用では、ロボットの制御などロボット工学などでも活用が進んでいるようです。
「行動を選択するActor」と、「Q関数(行動価値関数)を計算することで行動を評価するCritic」を交互に学習。
そうすることで、精度の向上を図っていくようです。
Asynchronous
Asynchronousとは、非同期でマルチエージェントな分散学習のこと。
Asynchronousが日本語で「非同期」という意味から、そのままですよね。
もう少し分かりやすい言葉で書くと
非同期で(複数の学習アルゴリズムはそれぞれで勝手に学習を進める)、マルチエージェント(複数の学習アルゴリズム)な分散学習
ということです。
例えばAlphaGoでは以下4つの学習アルゴリズムがあります。
・SL Policy
・Rollout Policy
・RL Policy
・Value Network
この4つのアルゴリズムが、それぞれで勝手に学習を進めること(非同期)で、強化学習を行うようです。
まとめ
今回は大項目「機械学習の具体的な手法」の中の一つ強化学習についての解説、第三弾でした。
本記事の重要キーワードは以下。
・バンディットアルゴリズム
・ε-greedy方策
・UCB方策
・マルコフ決定過程モデル
・マルコフ性
・A3C
・Actor-Critic
以上が大項目「機械学習の具体的な手法」の中の一つ強化学習の内容でした。
強化学習は深く理解しようと思うと超難しいので、G検定合格においては以下のことが大事かと。(りけーこっとんも、まだよく分かってません)
・学習の特徴(他の手法と比べて何が違うのか)
・学習の内部で行われていること(アルゴリズム) ※詳しい数式まで覚える必要はなし
・使用されている具体例(どの強化学習手法に用いられているか・現実問題にどう活かしているのか)
今回で「強化学習」の章は終了です。
次回からは、大項目「機械学習の具体的な手法」の中の一つ「モデルの評価」にはいっていきたいと思います。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!





