
G検定|機械学習の具体的な手法|ニューラルネットワーク・バギング・ブースティングなどを分かりやすく解説

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。
なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


目次
大項目「機械学習の具体的な手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「機械学習の具体的な手法」の内容。
その中でも「教師あり学習」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
本記事の範囲は、合格に向けては必須の基礎知識になります。
これから先の機械学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
教師あり学習に関する内容が多くなってしまったので、記事を複数回に分割してお届けしようと思いますね。
教師あり学習の概要
教師あり学習とは教師データ(正解データ)に、学習の結果を近づけようとする機械学習の手法。
教師データ(正解データ)とは予め人間が用意したデータで、データの通りに機械が予測できれば正解、そうでなければ不正解となるデータのことです。
例えば犬と猫の画像があったとしましょう。
人間が用意した犬と猫の画像は「教師データ」です。
機械が画像に何が写っているかを予測した結果、犬を犬、猫を猫と出せるようにしたいのが、教師あり学習。
全体的な構成は以下の画像の通り。
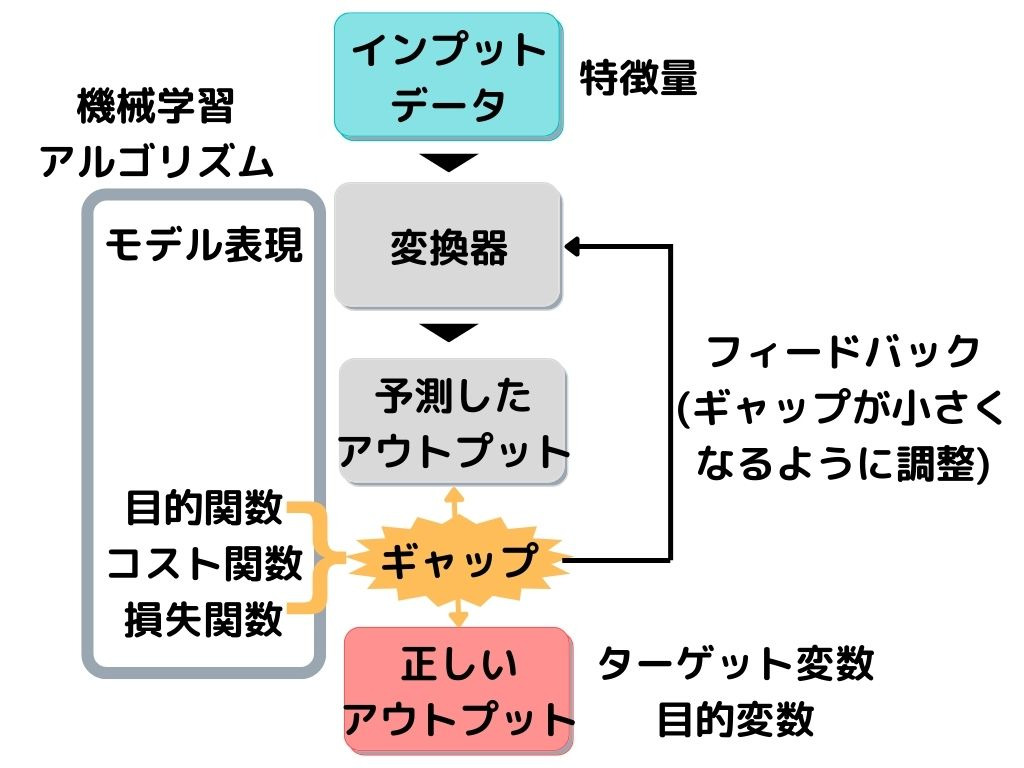
教師データは上の図で言うと「正しいアウトプット」に相当します。
専門用語だと「ターゲット変数」「目的変数」なんて言ったりもしますね。
変換器が「予測したアウトプット」と「正しいアウトプット」のギャップ(誤差)を埋めるために、何回も調整(学習)するのが、教師あり学習です。
これから出てくる手法は全て「変換器」の部分。
専門用語では変換器を「モデル表現」、ギャップや誤差を「目的関数・コスト関数・損失関数」なんても言います。
このモデル表現や目的関数を合わせて「機械学習アルゴリズム」と言ったりもしますね。
そして変換器に入力するデータが「特徴量」と言われます。
りけーこっとんは、よく目的関数と目的変数がごっちゃになります。
これから示す方法は全て、「変換器・モデル表現」の中の話です。
では、一つずつ見ていきましょう。
ニューラルネットワーク
ニューラルネットワークとは、人間の脳の情報処理機構を真似た学習モデルのこと全般を指します。
モデル表現の一つですね。
人間の神経回路の構造を真似た、単純パーセプトロンが基本の考え方です。
人間の神経回路の構造?単純パーセプトロン?と思った方は埋め込みリンク、または以下の記事で詳しく述べてるので、是非見てみてください。
この単純パーセプトロンの層を増やしたものを、多層パーセプトロンといいます。
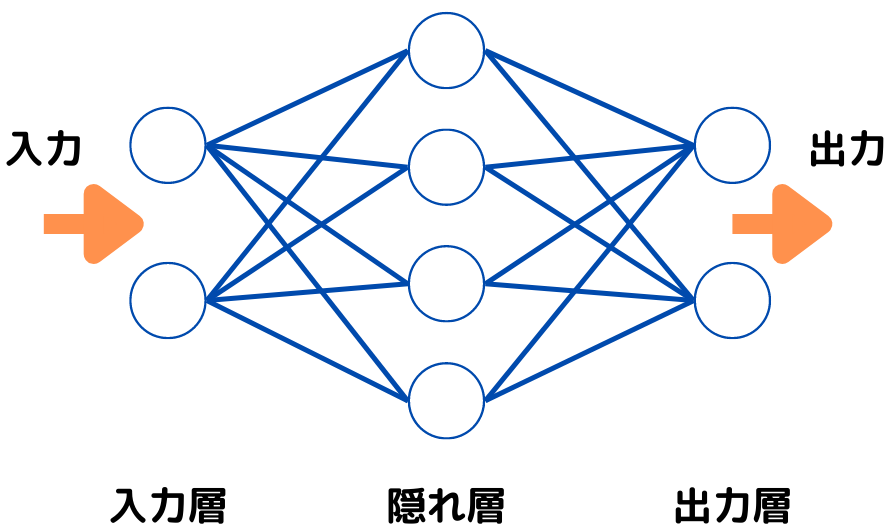
このように隠れ層が増えていますよね。
隠れ層を一つだけでなく、たくさんに増やしたものをディープラーニングといいます。
このような単純パーセプトロン、多層パーセプトロン、ディープラーニング全ては人間の神経回路の構造を参考にしていますよね。
そのため、これらを総称して「ニューラルネットワーク」と言うんです。
ロジスティック回帰
ロジスティック回帰とは、二値の分類問題で用いられる、回帰分析の一つ。
線形回帰の拡張版でニューラルネットワーク手法の一つに使われることもあるため、ここで解説します。
線形回帰については以下の記事からどうぞ。
二値の分類問題というのは「病気を発症するかしないか」「商品を購入するかしないか」といった、結果が2パターンのみで表せる問題のことです。
2パターン(二値)しかないので、データを線形回帰しようとすると以下のようになります。
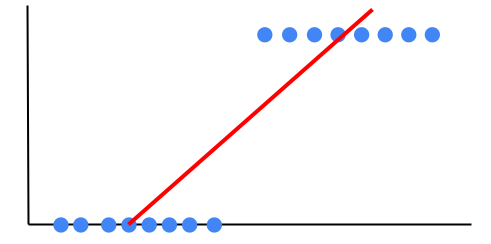
データに対して、上手く線を引けてるようには見えませんよね。
そこで、シグモイド関数という関数を入れてみます。
すると、
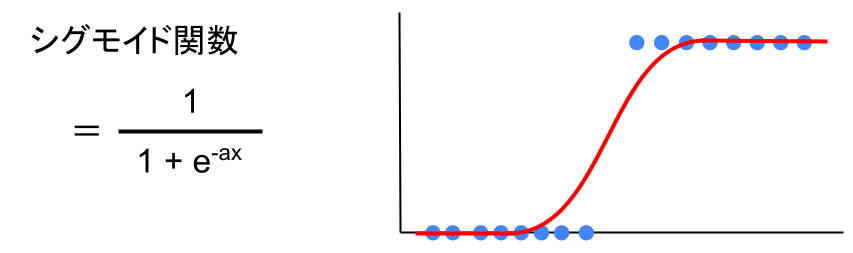
この関数だと、上手く説明できそうです。
このようにデータの傾向を見る式が、線形の式(y = ax + b)ではなく、シグモイド関数を使ったものをロジスティック回帰といいます。
ニューラルネットワークのメリット・デメリット
ニューラルネットワークを使用するメリットとしては以下の通り。
・モデルの表現力が高い、性能が高い
・SGDを用いることが多く、差分更新も可
SGDとは確率的勾配降下法といい、後の「ディープラーニング」の章で出てくることになります。
ニューラルネットワークを使用するデメリットとしては以下の通り。

ニューラルネットワークの使いどころ
ニューラルネットワークの使いどころとしては、以下の通り。
・精度重視の時
・画像処理、自然言語処理
まさに現在、流行中の分野に適用されていることが分かります。
プルーニング(枝刈り)
プルーニング(枝刈り)とは、影響の小さいノードを削除することでパラメータ数を削減する方法。
ノードというのは、先ほど出した多層パーセプトロンの図にあります。
隠れ層の○の部分がノードと言われ、活性化関数が入ります。
ノード同士を繋いでいる線は、「重み」や「バイアス」がかかっており、これらを総称してパラメータというようです。
「重み」は大きいほど、その活性化関数の出力が重要という意味。
つまり、隠れ層にあるノードで重みが小さい箇所(影響の小さい)の接続を削除すると、一気に考えなければいけない「重み」「バイアス」が少なくなりますよね。
このようにニューラルネットワークのパラメータ数を削減して、計算速度を上げることをプルーニングといいます。
アンサンブル学習
アンサンブル学習とは複数の弱学習器で1つの強学習器を作り、汎化性能を高める方法。
汎化性能というのは、未知のデータが入力され、学習したモデルで予測するときの正解する精度のことです。
弱学習器とは名前の通り、汎化性能があまり良くないモデルのこと。
この弱学習器をたくさん作って、予測精度の高い強学習器を作ろう、というイメージですね。
主な手法には以下の3つがあります。
・バギング
・ブースティング
・スタッキング
それぞれ見ていきましょう。
バギング
バギングとは、複数作ったモデル(弱学習器)を並列で一気に処理して、性能を高めること。
弱学習器に入れる学習データは、重複ありでサンプリングします。
イメージは以下のような感じ。
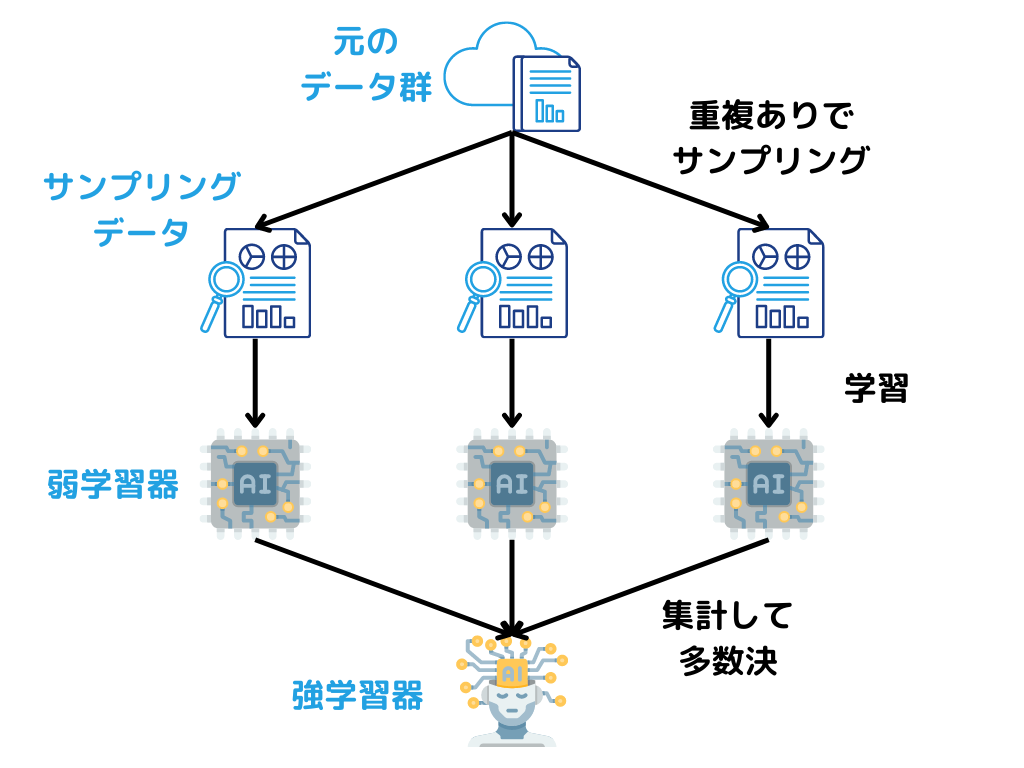
ランダムフォレスト
ランダムフォレストとはバギングの1手法のことです。
具体的な手順としては次の通り。
1.学習データに対して複数の決定木を作る
2.それぞれの木で並列に学習する
3.予測する際は出力結果の多数決で出力する
バギングの学習器に決定木を用いているイメージですね。
ブートストラップサンプリング
ブートストラップサンプリングとは、ランダムフォレストのやり方の一種。
学習データの中から重複を許してランダムに抽出し、複数の「決定木」を作る方法のことです。
弱学習器に入れるデータのサンプリングの仕方、といっても良いでしょう。
ランダムフォレストのメリット・デメリット
メリットとしては以下の通り。
・予測精度が高い
・スケールの影響を受けない
・カテゴリ変数、連続値共に特徴量として使える
デメリットとしては以下の通り。
・ハイパーパラメータが多く、調整が面倒
・特徴量が予測性能にどんな関係があるか理解しにくい
ランダムフォレストの使いどころ
使いどころとしては、以下のような場面があるでしょう。
・予測モデル最有力候補
・特徴量選択の道具として使う
・予測性能が高い、解釈可能性は低い
ブースティング
ブースティングとは前段階までに作成したモデルと学習データを照らし合わせて、新たな弱学習器を用いて逐次的に修正を行う手法のこと。
イメージだと以下の図のような感じでしょうか。
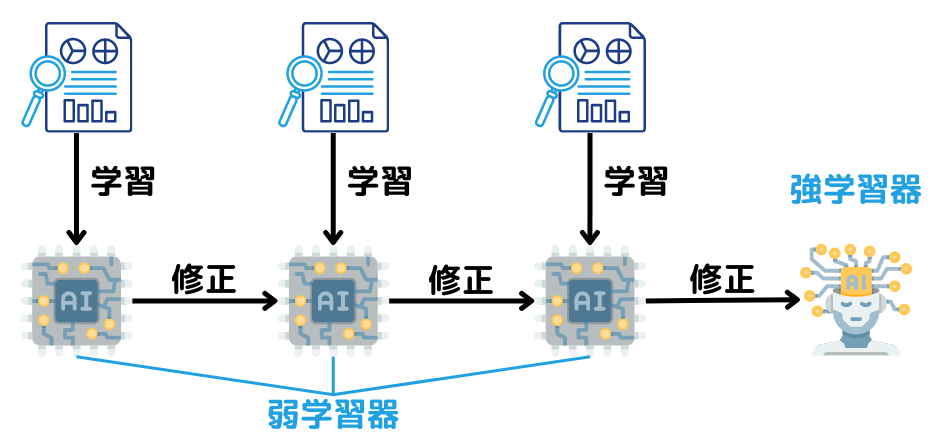
バギングとは違い、1つの学習器を毎回更新していきます。
ブースティングの代表的な手法は以下の2つ。
・勾配ブースティング
・Ada Boost
勾配ブースティング
勾配ブースティングとは前の学習器の予測とデータの違いを用いて、次の学習器を作成すること。
学習器には線形回帰、決定木など様々なモデルを使用できます。
特に決定木を用いると、勾配ブースティング木ともいうようですね。
Ada Boost
Ada Boostもブースティング手法の1つ。
手順は以下の通りです。
1.学習器を大量に作る
2.重み値を更新
3.学習器作り直し
4.2と3を繰り返す
Ada Boostはランダムフォレストと同等の精度が出るようです。
発展系としてはXgBoostがあるようですね。
興味のある方は調べてみてください。
スタッキング
スタッキングとは、あるモデルによる予測値を新たなモデルの特徴量(メタ特徴量)とする手法のこと。
この手法では、以下のようなで順で進みます。
1.データ1で学習したモデルAでデータ2を予測する
2.データ2の予測値を新たなモデルBの特徴量とする
3.モデルBでデータ3を予測する
このようにして、強学習器を作成していくようです。
イメージとしては以下の図のような感じ。
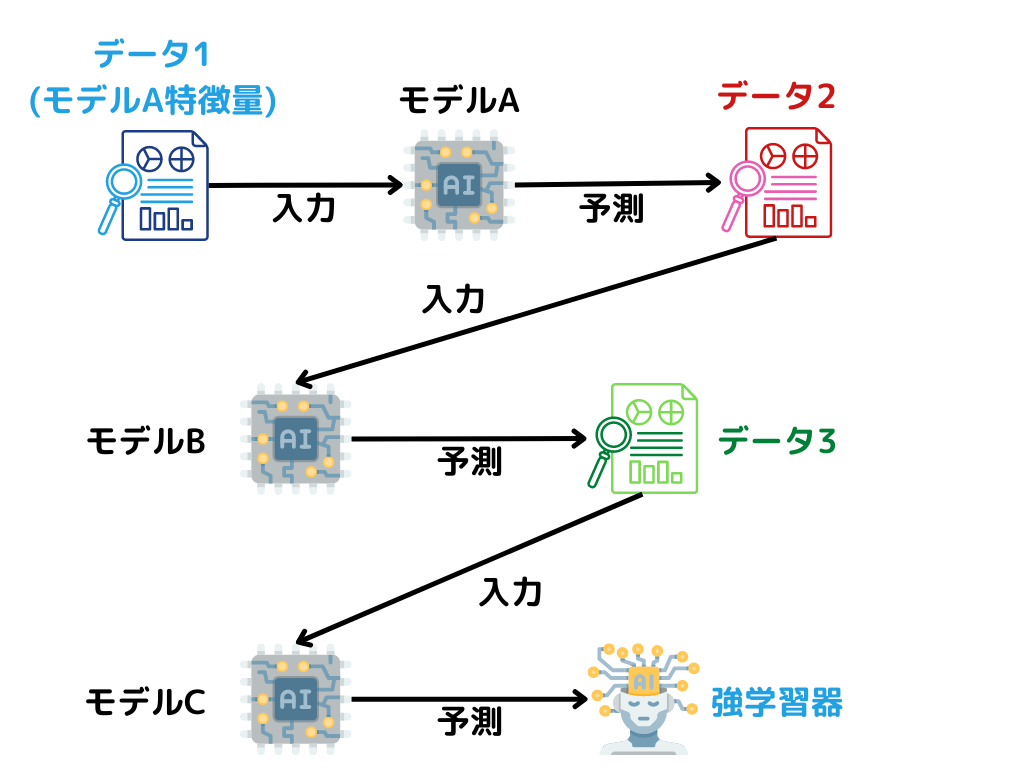
注意したいのは、既に学習に使ったデータセットを、そのまま二度使ってしまうこと。
一度使った時点で正解を知っているため、異常に過学習を起こしてしまいます。
それぞれの弱学習器のモデルには、様々なモデルが使用されるようですね。
まとめ
今回は大項目「機械学習の具体的手法」の中の一つ教師あり学習についての解説、第三弾でした。
本記事の覚えておきたいキーワードは以下。
・ニューラルネットワーク
・ロジスティック回帰
・バギング
・ランダムフォレスト
・ブースティング
・スタッキング
以上が大項目「機械学習の具体的手法」の中の一つ教師あり学習の内容でした。
今回で教師あり学習は、終了です。
そこで、次回は「機械学習の具体的手法」の中の一つ教師なし学習。
思ったより記事が長くなってしまってすみません。
それだけ押さえておきたいところが多いということ。
覚える内容が多いですが、りけーこっとんも頑張ります!一緒に頑張っていきましょう!
ではまた~
続きは以下のページからどうぞ!





