

※本記事はアフィリエイト広告を含んでいます
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/214d380e.96fa3830.214d380f.9c4125c0/?me_id=1213310&item_id=20632239&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F8326%2F9784297128326_1_2.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")



どーも、りけーこっとんです。
DS検定の勉強をしよう!と思ったは良いものの、こんな悩みはありませんか?
DS検定ってどうやって勉強すればいいの?
DS検定の勉強の仕方が分からない…
本で勉強するのは分かるけど、高いなぁ…
無料で単語解説されているサイトとかないかな?
DS検定は、始まったばかりの試験だから、対策法とか分からないよね。
じゃあ、このサイトで出題範囲の内容を押さえていこう~
DS検定の解説をすぐ見たいよ!という方は、以下から最初の解説に飛べます。

今回はスキルチェックリスト
「DS60:線形回帰、ロジスティック回帰を説明できる」と
「DS71:混同行列から、モデル精度を評価できる」を解説していくよ~
本サイトでは超重要項目、重要項目、覚えておきたい項目と表記を分けますので、勉強時の参考にしてみてください。
DS検定って、そもそもどんな資格?という方は以下の記事をご覧くださいね。

試験範囲は以下の二つから出題されます。
・スキルチェックリスト
・数理、データサイエンス、AI(リテラシーレベル)モデルカリキュラム
本内容は以下の書籍を参考に作成しております。
なお、本サイトはDS検定の合格を保証するわけではありませんので、ご了承ください。
では早速、内容に入っていきましょう!
※「DS○○:」項目の文章は独自に短縮して表現しております
DS60:線形回帰、ロジスティック回帰を説明できる
この項目は、線形回帰・ロジスティック回帰が説明できなければなりません。
そこで線形回帰⇒ロジスティック回帰の順に分かりやすく解説していきます。
線形回帰
線形回帰
1つの目的変数に対して1つの説明変数で関係を記述すること。単回帰分析ともいわれる。
以下のように直線で表せる関係になるため、目的変数が量的な場合に用いられる手法。
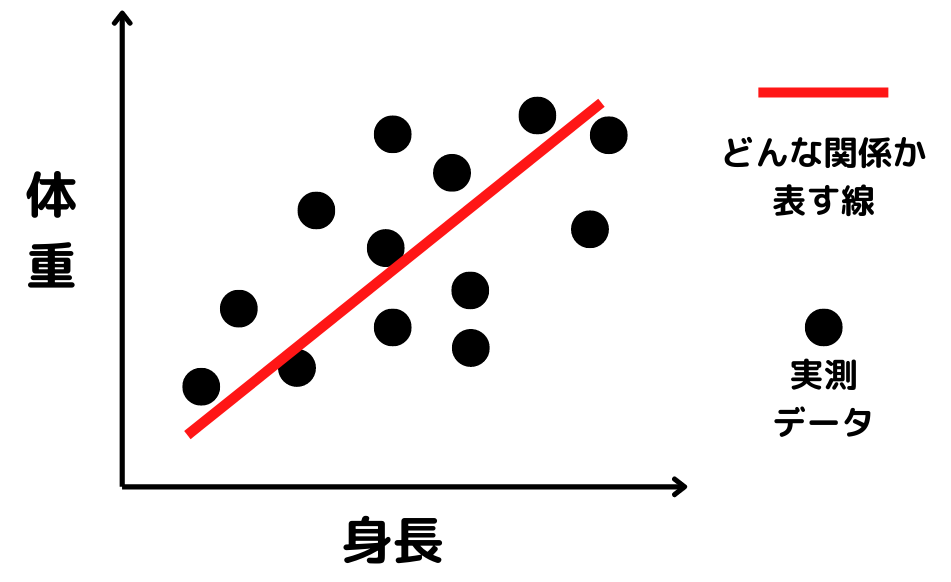
例)
・「身長(説明変数)」から「体重(目的変数)」を予測する
・「気温(説明変数)」から「アイスの売り上げ(目的変数)」を予測する など
「目的変数が量的な場合に」を強調したのには意味があります。
それは「量的変数を予測したい」場合もあれば「質的変数を予測したい」場合もあるということ。
そこで用いられるのが「ロジスティック回帰」です。
ロジスティック回帰
ロジスティック回帰
説明変数に対して目的変数が0or1の二値のみを取る場合に用いられる。
0or1とはアイスを購入する / しないの分類問題のようなイメージ。
量的な変数を予測する場合は線形回帰で問題ありません。
しかし0or1のような二値しか取らない場合は、線形回帰を行おうとすると以下のようになってしまいます。
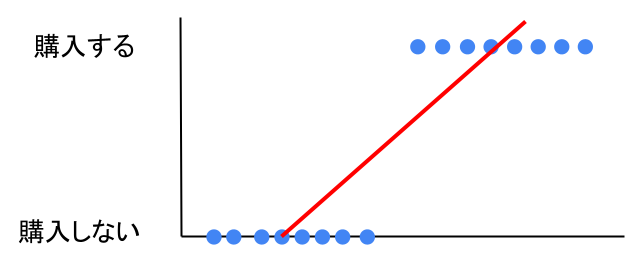
アイスを購入する / しないの予測が全くできている気がしませんよね。
つまり、線形回帰は二値分類問題に対応できないことになってしまいます。
そこでロジスティック回帰を用いると、以下のような線(関数)になります。
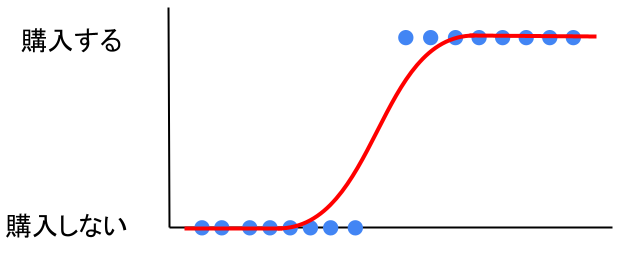
この関数をシグモイド関数とも言い、以下の式で表されます。
\(\displaystyle p(x)=\frac{1}{1+e^{-ax}}\) ここでp(x)はアイスを購入する確率、aは定数、xは説明変数このようにシグモイド関数を用いると「0・1の二値しか取らない出力値」から「0~1の連続値を取る出力値」に変わります。
つまり0.25などの出力値があり得るということです。
連続値を取れるというのは機械学習において非常に便利なので、よく使われます。
(なぜかについては資格の範囲を超えますので、割愛します)
また、起こる確率(上記の例だと購入する確率)をp(x)について、
\(\displaystyle オッズ比 = \frac{p(x)}{1-p(x)}\)でオッズ比と言われる統計量を表すことも可能です。


DS71:混同行列から、モデル精度を評価できる
混同行列とは二値・多値分類問題に用いられる精度評価指標。
そもそも二値・多値分類問題とは以下のようなものです。
二値分類問題
目的変数が離散変数かつ2つしかない分類問題
例)
・アイスを購入する / しない
・画像に猫が写っている / いない
多値分類問題
目的変数が離散変数かつ複数ある分類問題
例)
・画像に「猫」「犬」「車」の何が写っているか判断する
・明日の天気は「晴れ」「曇り」「雨」かを予測する
DS71と70の順序が逆転していますが、混同行列を理解してからROC曲線(DS70)に触れた方が理解しやすいと思います。
混同行列
混同行列
二値・多値分類問題の精度評価指標。二値分類問題の場合、以下のような表が作成される。
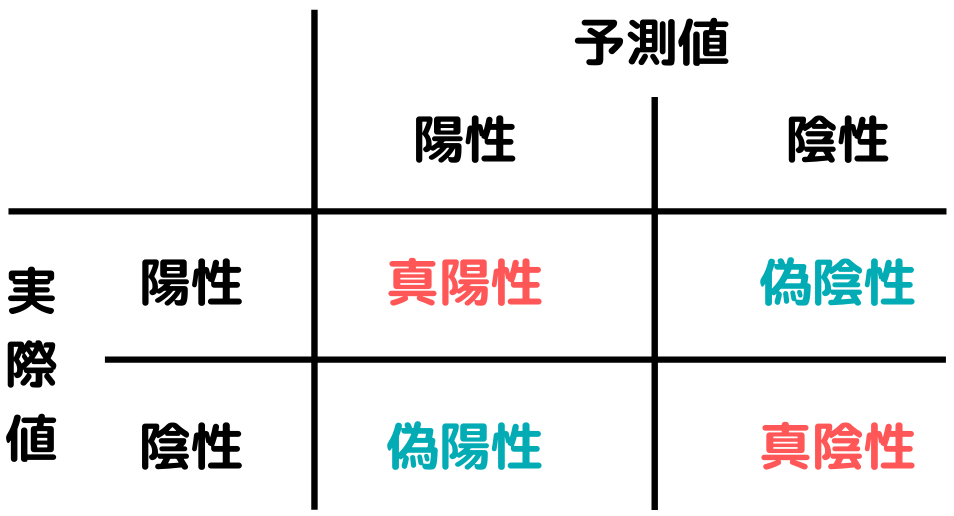
例としてアイスを購入する / しない予測をするモデルを考えます。
「予測値」とは、予測モデル(シグモイド関数)が予測として
・「購入する」と予測すれば「陽性」
・「購入しない」と予測すれば「陰性」
という意味。
「実際値」とは、実際のデータが事実として
・「購入する」なら「陽性」
・「購入しない」なら「陰性」
という意味になっています。
では表の中にある「真陽性」「偽陰性」などはどういう意味なのでしょうか。
真陽性
予測モデルが「陽性(購入する)」と判断し、実際のデータも「陽性(購入する)」のデータ数
偽陽性
予測モデルが「陽性(購入する)」と判断し、実際のデータは「陰性(購入しない)」のデータ数
真陰性
予測モデルが「陰性(購入しない)」と判断し、実際のデータは「陽性(購入する)」のデータ数
偽陰性
予測モデルが「陰性(購入しない)」と判断し、実際のデータも「陰性(購入しない)」のデータ数
特に「偽陰性」と「真陽性」は混同しやすいので注意してください。
この混同行列を使って、予測モデルの精度を評価する際には、以下の4つを使用します。
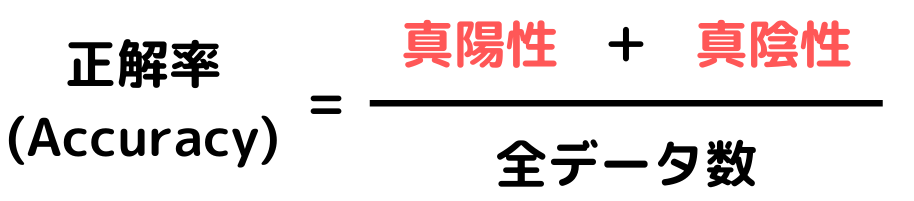
Accuracy(正解率)
予測モデルが正しく判断できたデータ数
Precision(適合率)
モデルの予測で「陽性(購入する)」と判断したとき、どれだけ正解したか。

Recall(再現率)
事実のデータで「陽性(購入する)」のうち、どれだけ予測モデルが陽性と判断したか。

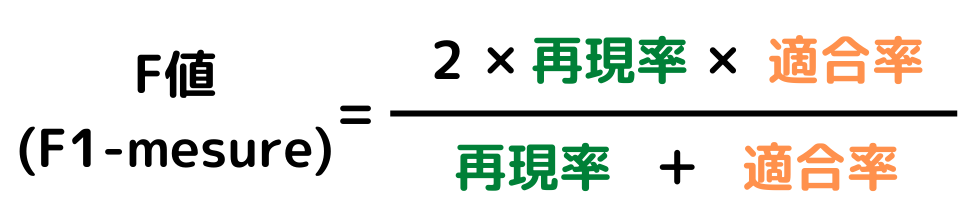
F値
再現率と適合率の調和平均
精度評価指標の中でも、「適合率」と「再現率」は混同しやすいので、注意しましょう。
りけーこっとんの主観ですが覚え方としては
・Precisionは予測モデルの結果の中で正しい判断できた割合
・Recallは事実データの中で正しい判断できた割合
と覚えると覚えやすかったです。
まとめ
今回は「データの予測・評価」などを解説してきました。
以下の項目を説明できるようになっているでしょうか?
・線形回帰
・ロジスティック回帰
・オッズ比
・二値分類問題
・多値分類問題
・混同行列
・Accuracy(正解率)
・Precision(適合率)
・Recall(再現率)
・F値
DS検定は覚える内容が多いです。
一つ一つを細部まで見るというよりは、広く浅く見ていくことが重要かと思います。
DS検定を取得して、データサイエンティストやAI関連の仕事への道を開きましょう!
次回は「予測モデルの評価」などについて解説していきます。
ではまた~
DS検定の続きの解説は以下のページからどうぞ!



コメント