

※本記事はアフィリエイト広告を含んでいます
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/214d380e.96fa3830.214d380f.9c4125c0/?me_id=1213310&item_id=20632239&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F8326%2F9784297128326_1_2.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")


どーも、りけーこっとんです。
DS検定の勉強をしよう!と思ったは良いものの、こんな悩みはありませんか?
DS検定ってどうやって勉強すればいいの?
DS検定の勉強の仕方が分からない…
本で勉強するのは分かるけど、高いなぁ…
無料で単語解説されているサイトとかないかな?
DS検定は、始まったばかりの試験だから、対策法とか分からないよね。
じゃあ、このサイトで出題範囲の内容を押さえていこう~
DS検定の解説をすぐ見たいよ!という方は、以下から最初の解説に飛べます。

今回はスキルチェックリスト
「DS136:データの性質理解には可視化が重要だと理解している」から
「DS145:サンプリング等で適量にデータを減らせる」を解説していくよ~
本サイトでは超重要項目、重要項目、覚えておきたい項目と表記を分けますので、勉強時の参考にしてみてください。
DS検定って、そもそもどんな資格?という方は以下の記事をご覧くださいね。

試験範囲は以下の二つから出題されます。
・スキルチェックリスト
・数理、データサイエンス、AI(リテラシーレベル)モデルカリキュラム
本内容は以下の書籍を参考に作成しております。
なお、本サイトはDS検定の合格を保証するわけではありませんので、ご了承ください。
では早速、内容に入っていきましょう!
※「DS○○:」項目の文章は独自に短縮して表現しております
DS136:データの性質理解には可視化が重要だと理解している
この項目は、なかなか抽象的で分かりにくいかなと思います。
そこで、DS検定においては「データを可視化して、何が言えるかを考えることが重要」と理解すればいいかと。
DS検定にはグラフを読み解いたり、「この場合はどんなグラフを使うのが適切か」みたいな問題が出題されます。
今回から次回に渡って、様々なデータ可視化のポイントを解説していきます。
それらを理解しながら、「どんな可視化が適切か」「その可視化からどんなことが言えるのか」を考えられるようになりましょう。
DS137:可視化の目的の広がりについて概略を説明できる
データ可視化とは、データから事象を解釈することを補助する役割を持ちます。
そこでデータ可視化の代表的な目的には、以下の三つがあります。
・探索目的
・検証目的
・伝達目的
探索目的
探索目的
データ分析の初期段階で、課題や仮説を立てる際に利用する目的でデータ可視化を行うこと。
例えば、商品のマーケティング戦略で広告を出すことは効果があるかどうかを確かめたいとしましょう。
この時、まずは一通り集めたデータを眺めて見なければ、何の根拠もない仮説を立てることになってしまいますね。
「広告を出した前後で売上は変わったのか」
「広告を出す媒体によってアクセス数はどうなのか」
「広告媒体と売上の相関はどうなのか」
など、様々な観点でデータを眺めます。
そもそも売上が落ちてしまったのなら広告自体が悪いのかもしれませんよね。
Youtubeのアクセス数と売上に正の相関がありそうなら、Youtubeが効果的なのかもしれません。
このように仮説や課題を立てるときにデータ可視化があると、事象を理解しやすくなったり、課題を立てやすくなったりします。
検証目的
検証目的
立てた仮説を検証することに使ったり、精度・成果評価をすることが目的でデータ可視化を行うこと。
上述の商品のマーケティング戦略で広告を出すことは効果があるかどうかを確かめたい、という例を用いましょう。
「売上が変わらず、広告を出す媒体が悪いのかもしれない」という仮説が立ったとします。
すると、広告媒体ごとのアクセス数のデータが欲しくなりますね。
そこで実際に広告を出す媒体を変えてみて検証し、データを取り直します。
この検証結果を考える時に、データ可視化が役に立つんです。
適切に可視化することで、広告を出す媒体を変えて売上が変わったかどうかが一目で分かるようになります。
伝達目的
伝達目的
分析結果などを上司・社員・顧客などに説明する目的でデータ可視化を行うこと。
こちらは一番想像しやすい目的ではないでしょうか。
分析結果を伝える時には、相手が分かりやすい形になっていることが重要です。
プレゼン資料などにも数字だけが載っているよりも、適切な表やグラフがあったほうが直感的に理解しやすいですよね。
このように「データ可視化」といっても、様々な目的があります。
DS140:散布図などの軸出しで縦軸・横軸の適切な候補を洗い出せる
一般的にデータ分析において、変数はたくさんあるもの。
その中から適切な変数を選んで可視化することは、非常に重要です。
散布図やクロス集計表などの可視化方法は、2変数の関連を可視化できます。
そこで特に散布図では、縦軸と横軸に何の変数を取るか、が重要になってくるんですね。
散布図では、目的変数がある場合とない場合で軸の取り方が異なります。
目的変数がある場合
目的変数がある場合、というのは何か一つの変数の原因を知りたい時などのことです。
例えば「アイスの売上がなぜ上昇したのかを知りたい」場合を考えてみましょう。
原因を知りたい変数(目的変数)は「アイスの売上」ですね。
散布図の場合、目的変数「アイスの売上」を縦軸に取ります。
その上で、「アイスの売上」の原因になりそうな変数(説明変数)「気温」「湿度」などは横軸に取ります。
このように目的変数がある場合には、目的変数を縦軸・説明変数を横軸に取るんですね。
縦軸は「アイスの売上」に固定したうえで、横軸を「気温」「湿度」を変更した散布図を2つ作成すれば、それぞれの説明変数がアイスの売上にどれだけ影響してるかが分かります。
こちらは以前の散布図の説明でもした、相関を見るという使い方ですね。
しかし散布図にはもう一つの使い方があります。
目的変数がない場合
散布図のもう一つの使い方が「目的変数がない場合」。
目的変数がない場合、というのは2つの評価軸でデータ分類したい時などのことです。
例えば「自社商品を買う顧客を分類したい」場合を考えてみましょう。
評価軸は「一回の買い物の金額」と「月平均購入回数」とします。
この場合は縦軸に「一回の買い物の金額」、横軸に「月平均購入回数」を取れますね。
実際に散布図を描いてみると以下の通り。
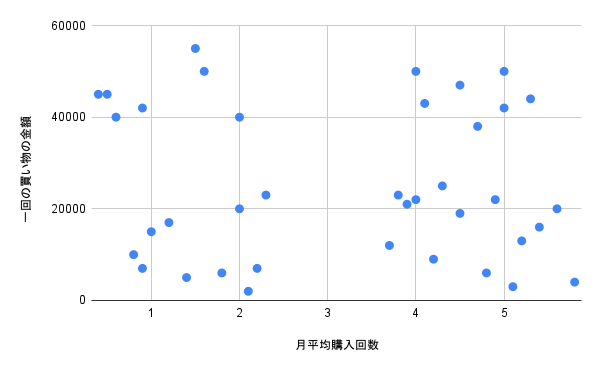
この図からは以下のようなことが分かります。
- 「一回の買い物の金額」も「月平均購入回数」も多い場合(右上)
頻繁に買いに来てくれていて、1回の買い物でもたくさん買ってくれている常連客になります - 「一回の買い物の金額」は多く「月平均購入回数」は少ない場合(左上)
何かセールなどのイベントの際に買いに来てくれる顧客になります。 - 「一回の買い物の金額」は少なく「月平均購入回数」が多い場合(右下)
必要最低限なものを定期的に買ってくれている顧客になります。 - 「一回の買い物の金額」も「月平均購入回数」も少ない場合(左下)
そもそも買いに来ていない潜在顧客になります。
このように散布図はデータ分類としても使えるんです。
DS141:積み上げ縦棒グラフで属性の選択など、適切な層化(比較)候補を出せる
積み上げ縦棒グラフなどでは層化が重要になります。
層化
データ可視化の際に比較したいものを分類別に分けること。
例)
地域別、時間帯別、商品別など
層化は適切に行うと、比較対象の差を見比べやすくなるんですね。
また、層化の候補を考える時には「種類の観点」と「粒度の観点」があります。
「コンビニ店舗ごとのアイスの売上を分析したい場合」を例に、層化について考えていきましょう。
種類の観点
今回の場合、層化の候補には地域別、時間帯別、商品別などがあります。
積み上げ縦棒グラフを作成するならば、今回知りたいのはコンビニ店舗ごとのアイスの売上です。
つまり縦軸は売上、横軸は店舗名になります。
その上で地域別の積み上げ縦棒グラフを作成すると以下のようになります。
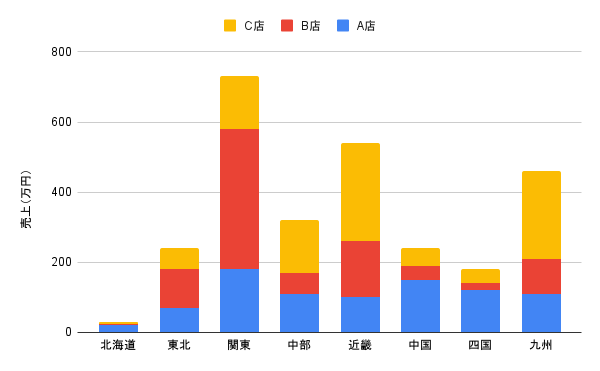
層化は、グラフの色が異なっている部分の属性を考えることですね。
層化の候補の洗い出しには地域別、時間帯別、商品別といった「種類の観点」ともう一つあります。
粒度の観点
もう一つの観点が「粒度の観点」です。
これは地域別、時間帯別といった「種類の観点」で考えた後に、さらに深堀りする観点になります。
上記の種類の観点では「地域別」といった時に、何も考えずに「東北地方、関東地方など地方での分類」としました。
しかし「地域別」といっても「都道府県別」や「国別」といった属性が考えられますよね。
また「時間帯別」といっても「月単位」「日単位」「時間単位」というものもあります。
これが「粒度の観点」です。
例えば「都道府県別」で属性を取り直すと、全く違ったグラフが出来上がります。
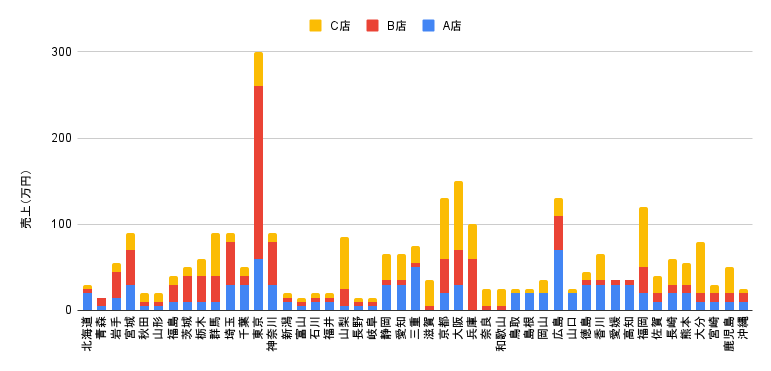
このように比較を考える際には「種類の観点」「粒度の観点」両方が大切です。
DS145:サンプリング等で適量にデータを減らせる
データの可視化時には、可視化するデータ量というのも重要になります。
そのまま全データを可視化すると、むしろ分かりにくくなる可能性もあるんです。
そこで、適切に可視化するデータ件数を減らして表示することが大切。
データ件数を減らす方法として、「サンプリング」と「平均」を見ていきます。
データ件数削減方法1:サンプリングする
まずはサンプリングしてデータを減らすという方法です。
サンプリングにもランダムサンプリングや層別サンプリングなど様々な種類があったかと。
元データ(母集団)の特性を失わないように、適切なサンプリング手法を用いることが大切です。
例えば年代ごとの年収のデータがあったとしても、可視化の目的によってはサンプリングの方法が変わります。
年代別で見たいなら、年代での層別サンプリングが必要。
日本全体のデータを見たいならランダムサンプリングが必要ですよね。
このように扱うデータや目的によって変わるので、データの特性・サンプリングの種類ごとの特性を理解することが重要です。
データ件数削減方法2:平均を取る
つぎに平均を取ってデータ件数を削減する方法です。
ここでは平均の種類として「時間平均」と「アンサンブル平均」を取り上げます。
時間平均は、時間で変化する値の時間軸での平均のこと。
アンサンブル平均は、時間・条件などが同じデータの平均です。
例えば以下のようなデータがあったとしましょう。
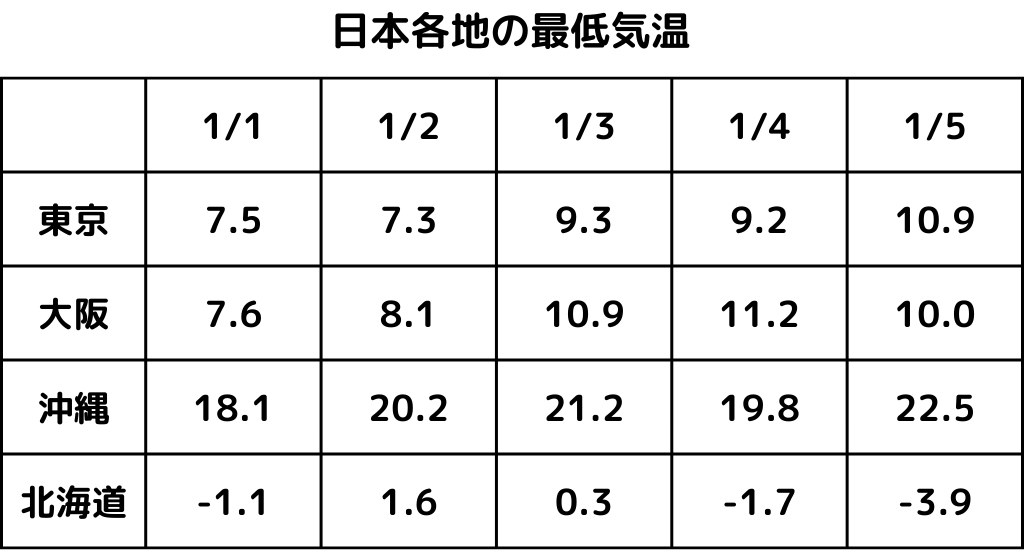
ここでの時間平均とは、東京のデータを1/1~1/5の日付で平均したものになります。
つまり、
$$東京の平均最低気温 = \frac{7.5+7.3+9.3+9.2+10.9}{5} = 6.86$$アンサンブル平均とは、1/1時点での全国平均を表します。
上記のデータを使うと
$$1/1の平均最低気温 = \frac{7.5+7.6+18.1+(-1.1)}{4} = 8.025$$このように平均化することで、データを削減できますね。
今回のデータの場合、時間平均なら5データが1データに、アンサンブル平均なら4データが1データになります。
まとめ
今回は「可視化の目的・アンサンブル平均」などを解説してきました。
以下の項目を説明できるようになっているでしょうか?
・探索目的
・検証目的
・伝達目的
・散布図の軸の取り方
・層化
・時間平均
・アンサンブル平均
DS検定は覚える内容が多いです。
一つ一つを細部まで見るというよりは、広く浅く見ていくことが重要かと思います。
DS検定を取得して、データサイエンティストやAI関連の仕事への道を開きましょう!
次回は「尺度の種類」「相関係数」「確率分布」などについて解説していきます。
ではまた~



DS検定の続きの解説は以下のページからどうぞ!



コメント