

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「ディープラーニングの手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの手法」の内容。
その中でも「深層強化学習」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
今回はディープラーニングの手法ということもあって、G検定のメインとなる内容。
ここを理解していないと、G検定合格は難しいでしょう。
ここから先の学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
今回は最も基本的なDQNを押さえていきたいと思います。
今までの記事で、見たことある単語も出てくるとは思いますが、復習の意味も兼ねて触れていきますね。
マルチタスク学習
画像認識でも、自然言語処理でも同じキーワードが出てきたこと、覚えているでしょうか?
マルチタスク学習とは、単一のモデルで複数の課題を解くこと。
強化学習では本課題と共に補助課題を解かせることで、学習速度や精度の向上を果たします。
例えば、ロボットが自立して歩く例を考えましょう。
本課題は「倒れないように歩く」ですね。
補助課題は「ロボットの重心の位置」「関節の位置」「周辺環境」など、様々です。
このように本来の課題を解くために、補助課題も一緒に解くことで学習精度を上げていきます。
DQN
DQNとは、Q学習にニューラルネットワークを用いた手法。
Q学習ってなんだっけ?
という方は、以下の記事を参考までに。

次の「行動」を列挙して、全ての価値計算を行い、価値が最大の「行動」を取っていく。
この計算を行うには次の条件が必要です。
・次の「状態」が離散的である
・次の「状態」が有限個である
でないと、行動が列挙できないですし、全ての価値計算ができませんね。
しかし現実問題「状態」の数はめちゃくちゃ多い。
そこで、ニューラルネットワークを使えばもっと楽に計算できるのでは?というのがDQNです。
ニューラルネットワークの入力は「状態」。
出力層の各ノードは「各行動の価値関数」です。
教師ラベルは「次の状態の即時報酬+各行動後の状態の最大価値関数」。
つまり「次の状態の即時報酬+各行動後の状態の最大価値関数」と「各行動の価値関数」の差を近づけていくように学習します。
この差のことをTD誤差とも言い、強化学習の記事でも少し触れていたかと。
※TD誤差はシラバスに載っていないが、強化学習を理解する上で重要なキーワード
このネットワークを学習することで、機械が勝手に価値関数を計算してくれるということです。
次に、DQNの工夫方法について述べていきますね。
Experience replay
Experience replayとは、学習を安定させるための方法の一つ。
Q学習には「重みの更新は状態遷移に強い影響を受けるため学習が安定しない」という問題がありました。
Q学習は時間を1ステップ進めて、価値関数を更新して…の繰り返しでしたよね。
なので、時間ステップが隣り合っていると似た結果になってしまいます。
つまり時間の相関が高くなって、学習が安定しづらくなってしまうんですね。
そこで、Experience replayの登場です。
時間的に順番じゃなくて、ランダムに入力しようという考え方。
そのために「状態・行動」と「報酬」の組を記録しておきます。
記録した中から、ランダムサンプリングして重みを更新することで、学習の安定化を図りました。

ダブルDQN
ダブルDQNとは、Q関数は誤差の+方向に影響を受けやすい問題に対処する手法。
Q学習では、次の価値の最大値を用いて学習していました。
最大値を使っているので、たまたま「ある状態」で高い価値が出てしまった場合、間違った学習をし続けてしまうことになります。
そこでダブルDQNを用いて、解消しようとしたんですね。
元々普通のDQNは行動選択・価値(Q関数)評価どちらも同じネットワークで行っていました。
一つのネットワークを二つにすることで、誤差の+方向を軽減させようというやり方。
使う二つのネットワークは
・Q関数の更新を行うネットワーク:普通のDQNと同じネットワーク
・次の行動を決めるネットワーク:普通のDQNとは別のネットワーク
カテゴリカルDQN
カテゴリカルDQNとは、分布を予測することで行動価値関数の近似をより精度よく学べる手法。
行動価値関数ってなんだっけ?という方は以下の記事をご覧ください。
元々、行動価値関数は期待値を計算することで「行動の価値」を表していました。
カテゴリカルDQNでは「期待値」ではなく「離散確率分布」を計算します。
こうすることで学習の安定や、期待値の分布・分散が分かり、より良いよねという考えです。
ちなみに使用するネットワークはダブルDQN(直前の章)と同じです。
Reward clipping
Reward clippingとは、DQNの学習を安定化させる手法の一つ。
DQNは価値関数をニューラルネットワークで学習するものでしたね。
価値関数には報酬の値が入っているので、ネットワークの重みに影響を与えます。
報酬設定の仕方が学習に悪影響を与えることもあるようです。
そこで、報酬の値にある程度制限をかけます。
例えば1,-1,0のみに限定したり、-1~1の間で限定するなど。
これによりニューラルネットワーク学習の安定化を図る手法のようです。
デュエリングネットワーク
デュエリングネットワークとは、DQNの学習を効率的に進めるためにネットワーク構造を変化させたもの。
「状態」によっては、どんな行動をとっても価値が変わらないものが存在します。
例えば囲碁や将棋などの「詰み」の状態など。
(どんな行動をとっても負け or 勝ちですよね)
しかし普通のDQNでは入力を「状態」、出力を「行動価値関数」としていました。
これは「状態」と「行動価値関数」の全組み合わせを計算しているようなものです。
効率が悪そうですよね?
そこでネットワークを途中で以下の二つに分岐させます。
・状態のみから計算できる部分
・行動のみから計算できる部分
分けることで「価値が変わらない状態」を考慮して、計算の効率を上げようという考え方です。
どんな行動をとっても価値が変わらない「状態」の学習精度が上がるようですね。
ノイジーネットワーク
ノイジーネットワークとは、より長期的で広範囲に行動探索を進める手法。
イメージとしては、ε-greedy法の発展版のような感じです。
ε-greedy法の詳しい話は以下をご覧ください。

ε-greedy法も、行動選択の範囲を広げたいという目的で作られたものでした。
ではネットワーク自体に外乱(ノイズ)を与えて、それも含めて学習すれば良いのでは?
というのがノイジーネットワーク。
ε-greedy法より長期的で広範囲に探索を進めることが期待できます。
Rainbow
Rainbowとは、それまで報告されてきたDQN改良手法をすべて搭載したDQNの総まとめ手法。
具体的にはオリジナルのDQNに、6つの手法を全部盛りして当時のSotAを更新しました。
用いられた改良トリックは以下の通り。
・Double Q-learning
・Noisy-network
・Prioritized Experience Replay,
・Categorical DQN
・Dueling-network
・Multi-step learning
実際の論文の図を見てみると以下のようなグラフがあります。
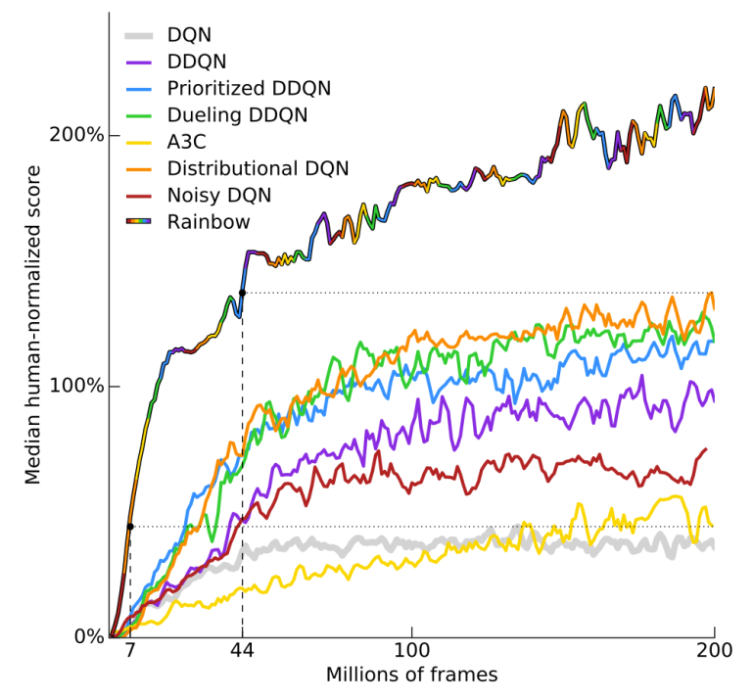
一番上の曲線が「rainbow」です。
それまでの手法よりも、格段に性能が良くなっていることが分かりますね。
SAC(Soft Actor-Critic)
SAC(Soft Actor-Critic)とは、連続値制御の深層強化学習モデルのこと。
Q学習に工夫をすることで「報酬の最大化」と「探索」を目的としました。
「探索」というのは「最適とは言えないけど取りあえず新しい行動をとってみる」ことです。
SACは、シラバスには載っていないのでこれくらいに留めておきます。
では、連続値制御とは何なのか?
以下で見ていきましょう。
連続値制御
連続値制御とは、行動表現が連続値を取るもののこと。
ゲームのような行動は、決まった選択肢の中から選ぶということが多いですよね。
例えば簡単な迷路などは、「行動」を「前進」「後退」「右折」「左折」の中から選ぶ感じです。
では、ロボットアームを曲げるとなったらどうでしょうか。
ロボットアームの「行動」は、0°~180°の間の角度で曲げるという表現になりますよね。
この場合極端に言えば、アームの角度は小数点を考慮すれば0°~180°の間で無限の数字を取れてしまいます。
迷路のように4つだけの行動から選ぶということができないんですね。
これが連続値制御です。
まとめ
今回は大項目「ディープラーニングの手法」の中の一つ「深層強化学習」についての解説でした。
本記事をまとめると以下の3つ。
・マルチタスク学習
・DQN
・ダブルDQN
・デュエリングネットワーク
・ノイジーネットワーク
・Rainbow
・連続値制御
以上が大項目「ディープラーニングの手法」の中の一つ「深層強化学習」の内容でした。
ディープラーニングに関しても、細かく学習しようとするとキリがありませんし、専門的過ぎて難しくなってきます。
そこで、強化学習と同じように「そこそこ」で理解し、あとは「そういうのもあるのね」くらいで理解するのがいいでしょう。
そこで以下のようなことが重要になってくるのではないかと。
・ディープラーニングの特徴(それぞれの手法はどんな特徴があるのか)
・それぞれの手法のアルゴリズム(数式を覚えるのではなく、何が行われているか)
・何に使用されているのか(有名なもののみ)
ディープラーニングは様々な手法があるので、この三つだけでも非常に大変です。
しかし、学習を進めていると有名なものは、何度も出てくるので覚えられるようになります。
後は、新しい技術を知っているかどうかになりますが、シラバスに載っているものを押さえておけば問題ないかと。
次回は「ディープラーニングの手法」の「深層強化学習」第二弾。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント