

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
皆さんも一緒に頑張りましょう!
※この記事は合格を保証するものではありません


大項目「ディープラーニングの手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの手法」の内容。
その中でも「畳み込みニューラルネットワーク」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
ここを理解していないと、G検定に合格も難しいでしょう。
難しく内容も多い部分ですが、しっかり覚えていきたいですね。
今回は畳み込みニューラルネットワークの基本的な用語・応用例を押さえていきたいと思います。
局所結合構造
局所結合構造とは、畳み込みニューラルネットワークの構造のこと。
画像の一部(局所)の特徴が、ニューラルネットワークの次の層と結合している構造のことです。
どういうことかというのは、前回の記事でも参考にさせて頂いた図が分かりやすいかもしれません。
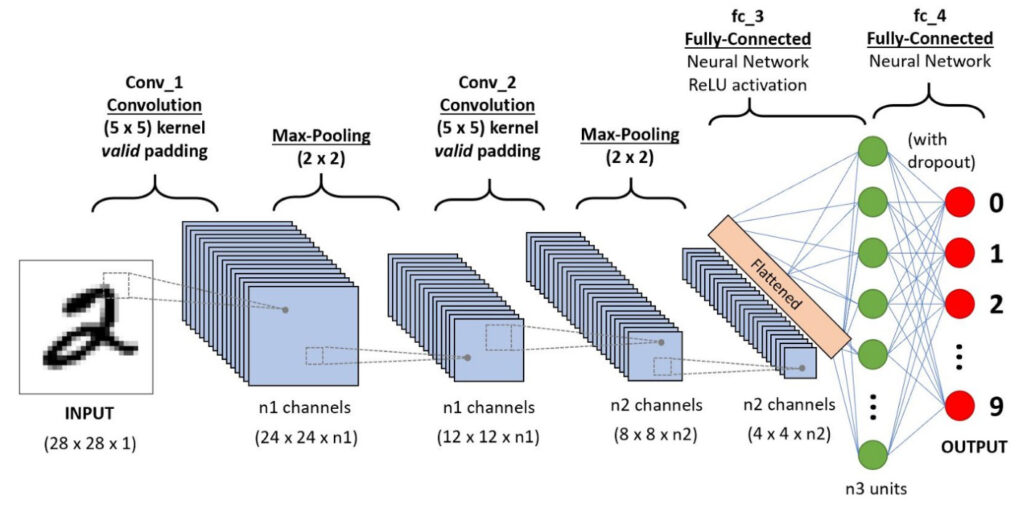
それぞれの画像に「点線の四角で囲まれている部分」があり、それが次の画像に繋がっていますよね。
このように
画像の一部がニューラルネットワークで学習される→特徴が出力→次のニューラルネットワークの入力に繋がる
といった構造を、局所結合構造と呼ぶようです。
ネオコグニトロン
ネオコグニトロンとは、1980年代に福島邦彦によって提唱された畳み込みニューラルネットワークの原型。
人の視覚の神経回路を参考にして作成した畳み込みニューラルネットワークのようです。
人の視覚神経回路には、「S細胞」と「C細胞」の2つがあります。
「S細胞」は目で捉えた画像の一部だったり全体の特徴を抽出する、という働き、
「C細胞」はS細胞で抽出した特徴の位置のズレを吸収する、という働きを持っています。
この「特徴量抽出を行うS細胞層」と「位置ズレを許容するC細胞層」を交互に多層に接続したニューラルネットワークがネオコグニトロン。
前記の記事でも触れた畳み込みニューラルネットワークの基本に非常に似ていますよね。
「畳み込み層→S細胞層」「プーリング層→C細胞層」といった感じでしょうか。
なので、畳み込みニューラルネットワークの元になったようですね。
LeNet
LeNetとは、最初の畳み込みニューラルネットワークのこと。
1989年にヤン・ルカンらが提唱したようです。
「ヤン・ルカン」という方もAI関連で有名な方なので、覚えておくと良いでしょう。
実際の構造としては以下の通り。
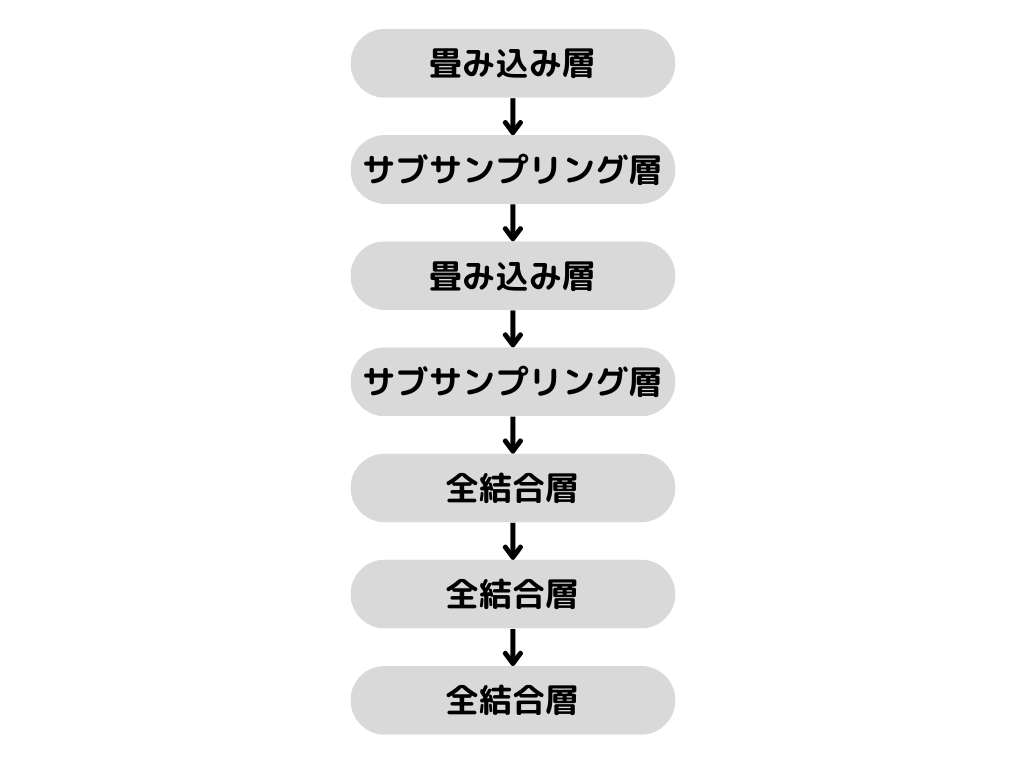
畳み込み→サブサンプリング層→畳み込み→サブサンプリング層→3層の全結合層
まさに、畳み込みニューラルネットワークの基本に沿ったような構造ですね。
ただ、プーリング層ではなく「サブサンプリング層」というものが使われています。
サブサンプリング層
サブサンプリング層とは、プーリング層と同義です。
LeNetに出てくる言葉らしく、ヤン・ルカンらが呼んでいたようですね。
「サブサンプリング層」という言葉は、LeNetでしか出てこないので、基本は「プーリング層」解いて覚えましょう。
さて、次の章からは「既に学習したモデル」を用いた学習の最適化手法を解説していきます。
転移学習
転移学習とは学習済みモデルを使用して、最終出力層の入れ替えを行い、他の学習に転用すること。
既にモデルを学習してあるので、学習が早く進みます。
この後にも似た手法として「ファインチューニング」「蒸留」も出てくるため、それらとの違いを意識しながら覚えましょう。
転移学習を図示するとこんな感じ。
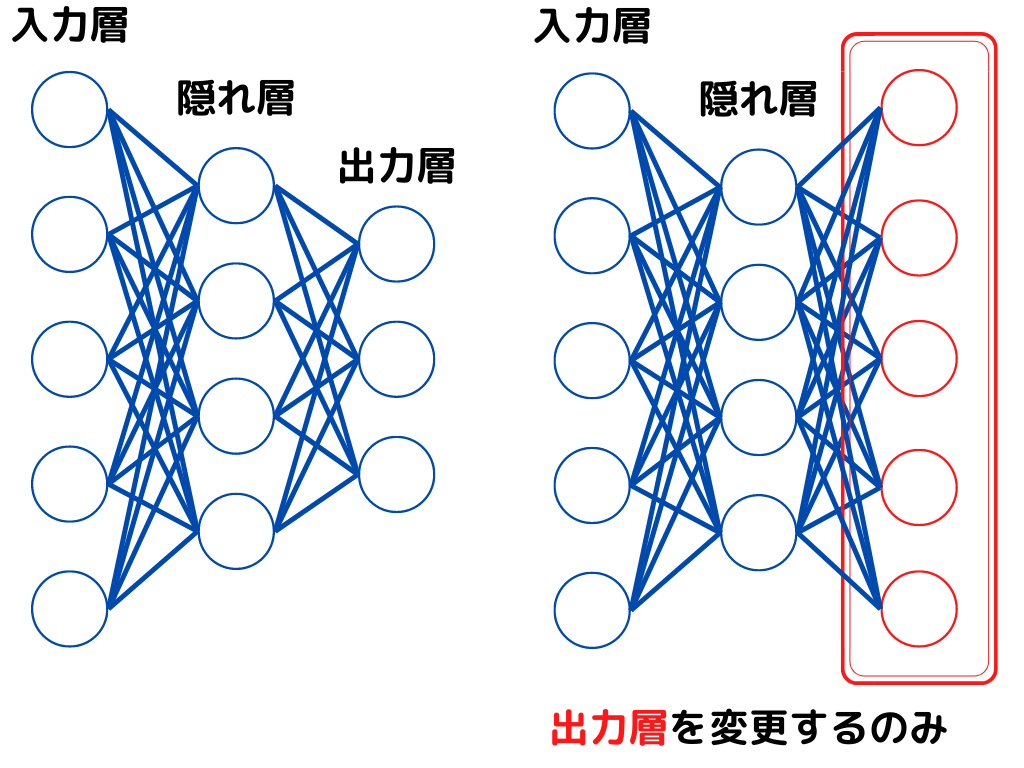
このように最終出力層を入れ替えるのみで、重みの更新は行いません。

ファインチューニング
ファインチューニングも、既に学習済みモデルを使用して、他の学習に転用する手法。
こちらも既に学習は一度済ませてあるので、1から学習するよりも早く学習が進みます。
ファインチューニングを図示すると次の通り。
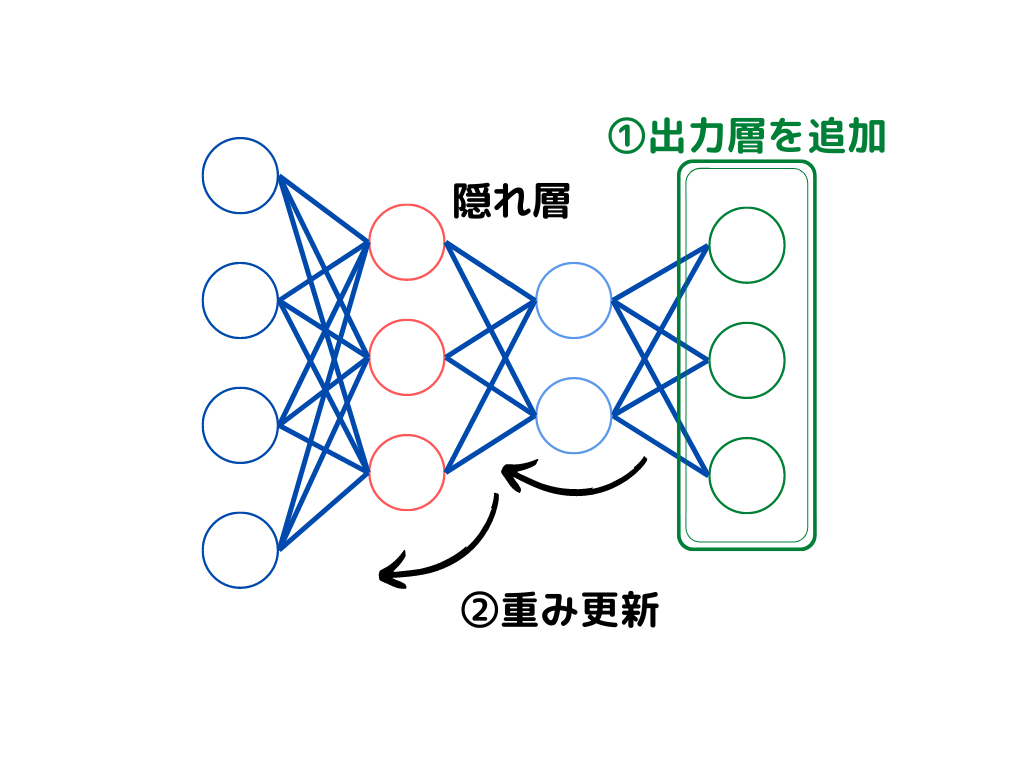
このように最終出力層の追加学習に加え、既存の特徴量抽出の重みを微調整する方法です。
転移学習は「最終出力層」の入れ替えを行うのみ、
ファインチューニングは「最終出力層と重みの更新」まで行います。
転移学習とファインチューニングは混同しやすいので、注意しましょう。
蒸留
蒸留とは、すでに学習してあるモデルを使用し、より軽量なモデルを生み出すこと。
化学の「蒸留」ではないので、気をつけましょう。
(りけーこっとんは化学の方だと思ってました)
高性能なモデルを作れていても、ニューラルネットワークの中身が複雑ずぎると、色んな問題が生じてしまいます。
例えばもしエラーが出たときに、複雑すぎるとどこが原因か分からないですよね。
なので複雑なモデルで使用した入出力を、よりシンプルな構造のニューラルネットワークに学習させます。
こうすることで、よりシンプルな構造のモデルが作成できるようです。
データの拡張方法(水増し)
データの拡張方法は、少ない画像データの中でも様々な種類のデータを作成する手法のこと。
ディープラーニングで十分な精度を出すには、大量のデータが必要になります。
数千、数万枚と必要なことだってあるんです。
しかし、大量の画像データを集めるのはシンプルに大変ですよね。
そこでデータの数が、どうしても十分数に至らないときに使用できるのが「データ拡張(水増し)」。
この手法によって、同じ画像でも複数種類の”違う”画像を作成できます。
主な手法は以下の通り。
・Cutout
・Random Erasing
・Mixup
・Cutmix
それぞれ見ていきましょう。
Cutout
Cutoutとは、画像データの一部をわざと欠損させること。
具体的な図で示すと次のようになります。
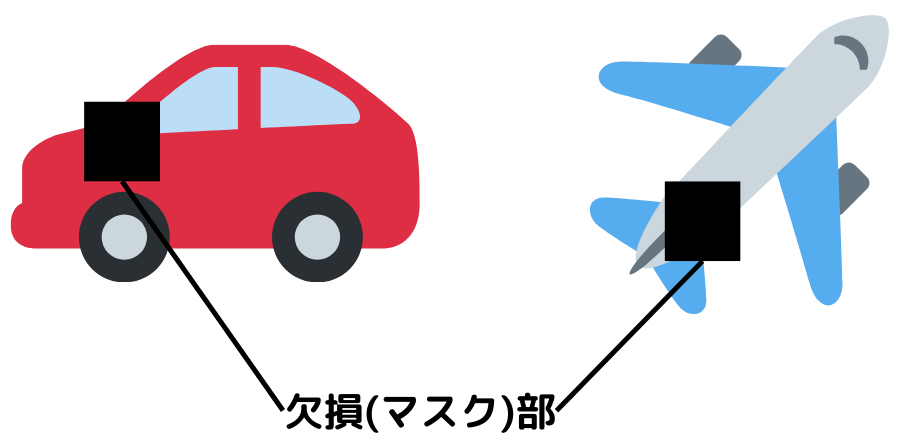
欠損させることを「マスクをかける」ともいうようです。
Random Erasing
Random Erasingとは画像の上から、ランダムな位置・大きさの矩形領域を重ねる手法。
具体的な図で示すと次のようになります。
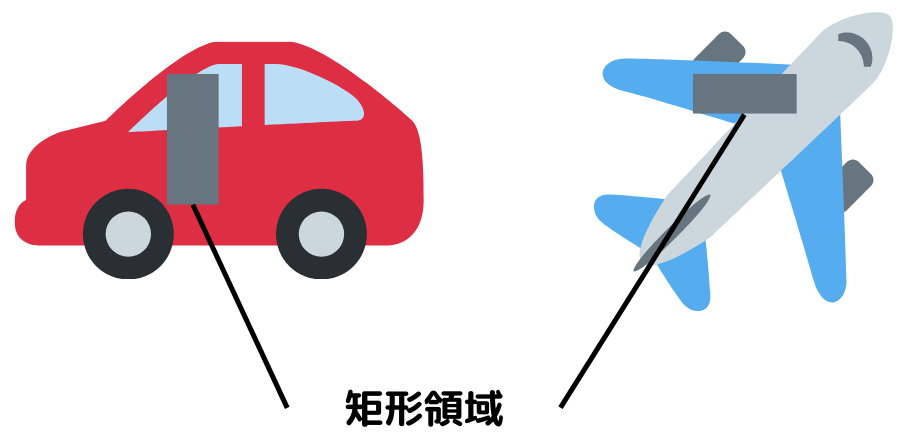
欠損させるのではなく、長方形を重ねているという点でCutoutと異なるのでご注意を。
Mixup
Mixupとは二つの訓練データのペアを混合して、新たな訓練データを生み出して水増しする手法のこと。
具体的な図で示すと次のようになります。
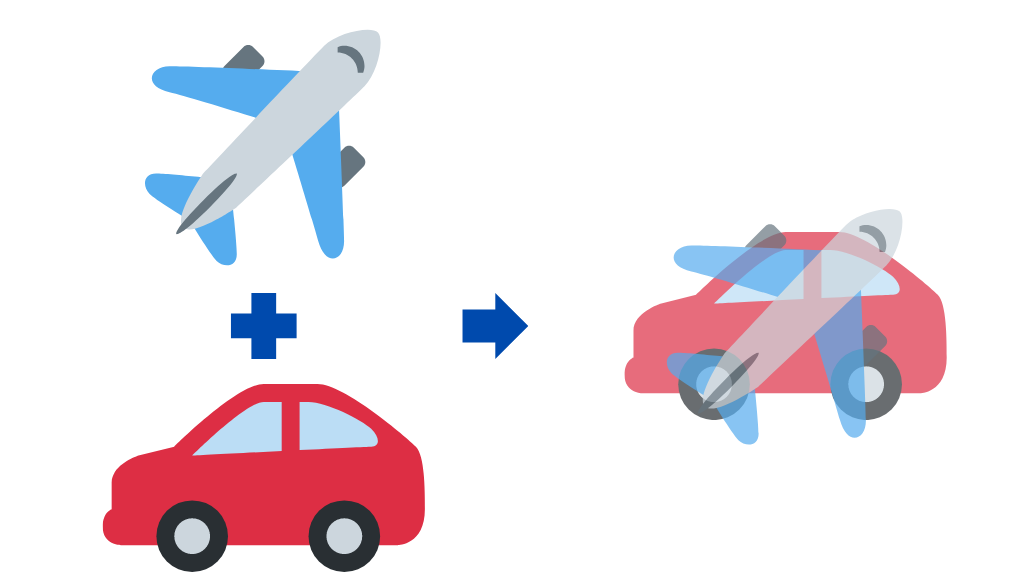
名前の通り2つのデータを混合(mix)して、水増ししてますよね。
CutMix
CutMixとは、CutoutとMixupを合わせたような改良手法。
欠損させた画像の部分に、別の訓練データのペアを当てはめる水増し方法です。
具体的な図で示すと次のようになります。
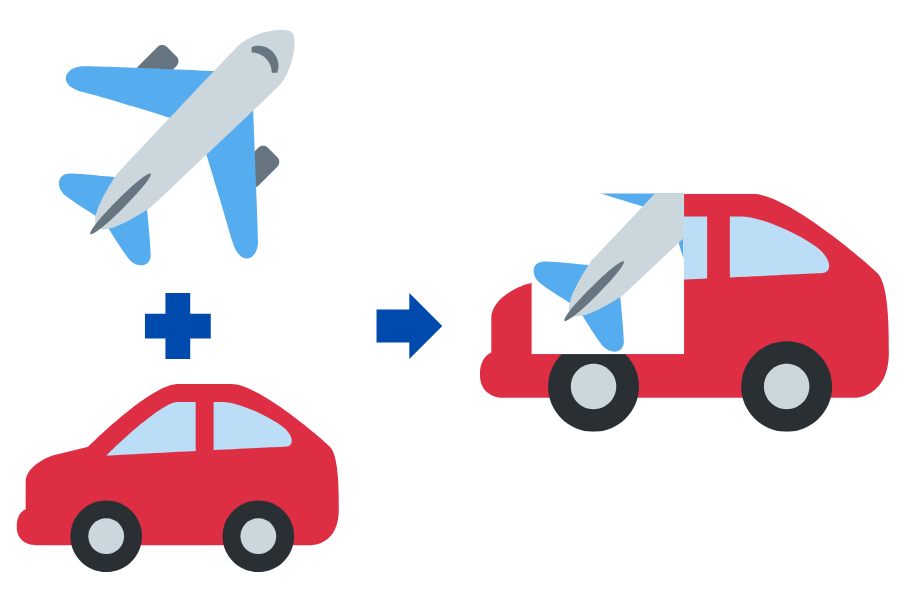
このように様々なデータ拡張を行うことで、ディープラーニングに必要なデータ数を確保します。
MobileNet
MobileNetとは、スマホ等の小型端末にも乗せられる高性能CNN。
小型端末にも載せたいためのニューラルネットワークなので、軽量かつ高性能なCNNです。
Depthwise Separable Convolution(後で解説します)を13段重ね、その後に全結合層をくっつけている構造。
畳み込みの計算をDepthwise Separable Convolutionで分割することで、計算量の減少を行っているようです。
Depthwise Separable Convolution
Depthwise Separable Convolutionとは、MobileNetに用いられる畳み込み層のこと。
通常の畳み込みを「フィルタの画像適用による畳み込み」と「フィルタの種類数による畳み込み」で分けています。
基本の畳み込みニューラルネットワークの構造は以下。
Input画像(28 × 28 × 1)は畳み込み層によって、n1 channelsの(24 × 24 × n1)は(縦×横×奥行き)のサイズになっています。
ここで
「フィルタの画像適用による畳み込み」は画像サイズが(28 × 28)→(24 × 24)に変わっていること
「フィルタの種類数による畳み込み」は奥行き(特徴抽出の枚数)が1→n1に変わっていること。
通常の畳み込みは「フィルタの種類数による畳み込み」と「フィルタの画像適用による畳み込み」を同時に行います。
しかしDepthwise Separable Convolutionは、最初に「フィルタの種類数による畳み込み」を行ってから「フィルタの画像適用による畳み込み」を実行。
平たくいえば、1回で処理していた工程を2つに分けたということになります。
このことによりパラメータ数が削減され、小型端末にも載せられるサイズにできたようです。
NAS(Neural Architecture Search)
NAS(Neural Architecture Search)とは、ニューラルネットワーク最適化の手法。
今までニューラルネットワークのモデルを作成するにはプログラミング技術、手法の知識、最新技術の知識など、様々な能力が求められました。
そうでないと、十分な精度のモデルが得られない可能性があるからです。
つまり、分析者の腕・能力に依存することが大きかったんですね。
しかし、NASでは以下のことを機械がやってくれます。
・ニューラルネットワークの構造最適化
・ハイパーパラメータの最適化
・学習(重み最適化)
これってニューラルネットワークを作るために必要な基本の流れでしたよね。
NASではこれら全てを学習してくれて勝手に最適なニューラルネットワークを決めてくれます。
NASNet
NASNetとは、CNNに限定してアーキテクチャ(モデル構造)を最適化するNAS。
CNNの「畳み込み」や「プーリング」を一つのCNNセルとして、最適化してくれるようです。
最適化したCNNセルは多様なデータセットや用途に利用可能であり、モデル開発効率が上がりますよね。
MNASNet
MNASNetとは、モバイル端末における推論速度を考慮したNAS。
つまりモバイル端末でもNASを使えるようにしたのが、MNASNetです。
Google開発が開発し、物体検出とImageNetでSoTAを獲得したようですね。
SoTA(State-of-the-Art)とは開発時点での科学技術の最先端レベル(=機械学習では正解率などのスコア/精度)、という意味です。
ImageNetは画像認識を争う大会のこと、ということは覚えていたでしょうか。
EfficientNet
EfficientNetとは2019年にgoogleが発表したモデルで、MnasNetの改良版。
既存のモデルより、大幅に少ないパラメータでSoTAを達成しています。
「モデルの深さ」、「広さ」、「入力画像」の大きさをバランス良く調整しているのが特徴です。
まとめ
今回は大項目「ディープラーニングの手法」の中の一つ「畳み込みニューラルネットワーク」についての解説第二弾でした。
本記事をまとめると以下の3つ。
・局所結合構造
・ネオコグニトロン
・LeNet
・サブサンプリング層
・転移学習
・ファインチューニング
・CutOut
・Random Erasing
・Mixup
・CutMix
・Depthwise Separable Convolution
・NAS
・NASNet
・MNASNet
・EfficientNet
以上が大項目「ディープラーニングの手法」の中の一つ「畳み込みニューラルネットワーク」についての内容でした。
ディープラーニングに関しても、細かく学習しようとするとキリがありませんし、専門的過ぎて難しくなってきます。
そこで、強化学習と同じように「そこそこ」で理解し、あとは「そういうのもあるのね」くらいで理解するのがいいでしょう。
そこで以下のようなことが重要になってくるのではないかと。
・ディープラーニングの特徴(それぞれの手法はどんな特徴があるのか)
・それぞれの手法のアルゴリズム(数式を覚えるのではなく、何が行われているか)
・何に使用されているのか(有名なもののみ)
ディープラーニングは様々な手法があるので、この三つだけでも非常に大変です。
しかし、学習を進めていると有名なものは、何度も出てくるので覚えられるようになります。
後は、新しい技術を知っているかどうかになりますが、シラバスに載っているものを押さえておけば問題ないかと。
次回は「ディープラーニングの手法」の「画像認識分野 物体識別」に触れていきたいと思います。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント