

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「ディープラーニングの手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの手法」の内容。
その中でも「音声処理と自然言語処理分野」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
今回はディープラーニングの手法ということもあって、G検定のメインとなる内容。
ここを理解していないと、G検定合格は難しいでしょう。
ここから先の学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
今回は自然言語処理の中でも、文章・単語をどう扱うかを押さえていきたいと思います。
音声処理は自然言語処理の一分野ですが、重要キーワードが多いので、後の記事で詳しく解説しますね。
今までの記事で、見たことある単語も出てくるとは思いますが、復習の意味も兼ねて触れていきます。
言語モデル
言語モデルとは、文の品詞や統語構造、単語と単語、文書と文書などの関係性について定式化したもののこと。
自然言語処理の分野で、幅広く用いられているようです。
多くの場合は統計学的な観点から数式などを用いて、確率的に定めて式にしていきます。
最も可能性の高い組み合わせを文章化できるようですね。
代表例は以下の通り。
構文解析
Nグラムモデル
隠れマルコフモデル
最大エントロピーモデル
形態要素(形態素)解析
形態要素解析とは、文章を形態素の形に分割し、それぞれの形態素の品詞などを判別すること。
形態素というのは、日本語における「単語」と思ってもらえればOKです。
例えば「これはペンです」という文があったとしましょう。
これを「これ / は / ペン / です」という風に分けた、一つ一つが形態素と呼ばれます。
形態要素解析では上記のように分ける際、「辞書」と呼ばれる単語の品詞等の情報に基づいて分割するんですね。
分割したら、それぞれの形態素の品詞等を判別することで、後に様々なことが可能になります。
構文解析
構文解析といっても、プログラミングとしての意味と自然言語としての意味で若干違うようです。
ここでは自然言語における構文解析の意味を解説しますね。
構文解析とは形態素に切分け、さらにその間の関連を明確にすること。
形態素解析に、単語同士の関連性を見ることを加えたようなイメージでしょうか。
形態素というのはさっき説明した通りですね。
形態素同士の関連というのは、「主語-述語」「修飾-被修飾」などの関係です。
これらを図式化するなどして、明確にしていきます。
単語埋め込み
ちなみに「埋め込み」というのは数学の様々な分野でも用いられる言葉のようです。
それぞれの定義が異なったり、難しいことがよくあるので、自然言語処理における「埋め込み」を解説しますね。
単語埋め込みとは、単語を低次元(200次元程度)の実数ベクトルで表現する技術のこと。
機械は人間が見ている「文字」のような形で認識できないので、「01051180」のように数字で表す必要があります。
この数字で表した表現が、「ベクトルで表現する」といわれるんですね。
「単語を埋め込む」ということは
「単語をニューラルネットワークを使って、いくつかの数字(ベクトル)で表す」という意味。
数字で扱えるようになるので、以下のようなことができます。
1.近い意味の単語を近いベクトルに対応させられる
2.ベクトルの足し引きで意味のある結果が得られる
機械で単語を扱う上で、重要なことですね
ベクトル空間モデル
ベクトル空間モデルとは、文章の意味をベクトルで表現すること。
これによって、文章全体を一つのベクトルで表すことができます。
先ほどまでは単語をベクトル化(いくつかの数字にすること)していましたが、今回は文章全体の話ですね。
文章全体をベクトル化することで、単語のベクトル化と同じようなメリットが受けられます。
つまり、文章同士の意味が似ているかどうか(類似度)を判別できるということです。
局所表現
局所表現は、一つの単語・文章を一つの表現(1:1)で対応させること。
より一般的な言い方をすると「ある概念を他の概念から完全に独立したものとして表現すること」となります。
難しいですよね。
すぐに説明する「ワンホットベクトル」が理解できると、分かりやすいと思います。
局所表現は言ってしまえば「単語・文章をワンホットベクトルで表すこと」だからです。
ワンホットベクトル
ワンホットベクトル(one hot vector)とは、1つの成分が1で、他が0のベクトルのこと。
単語が出現した箇所のみを1とし、それ以外を0とすることで表せます。
イメージは以下のような感じ。
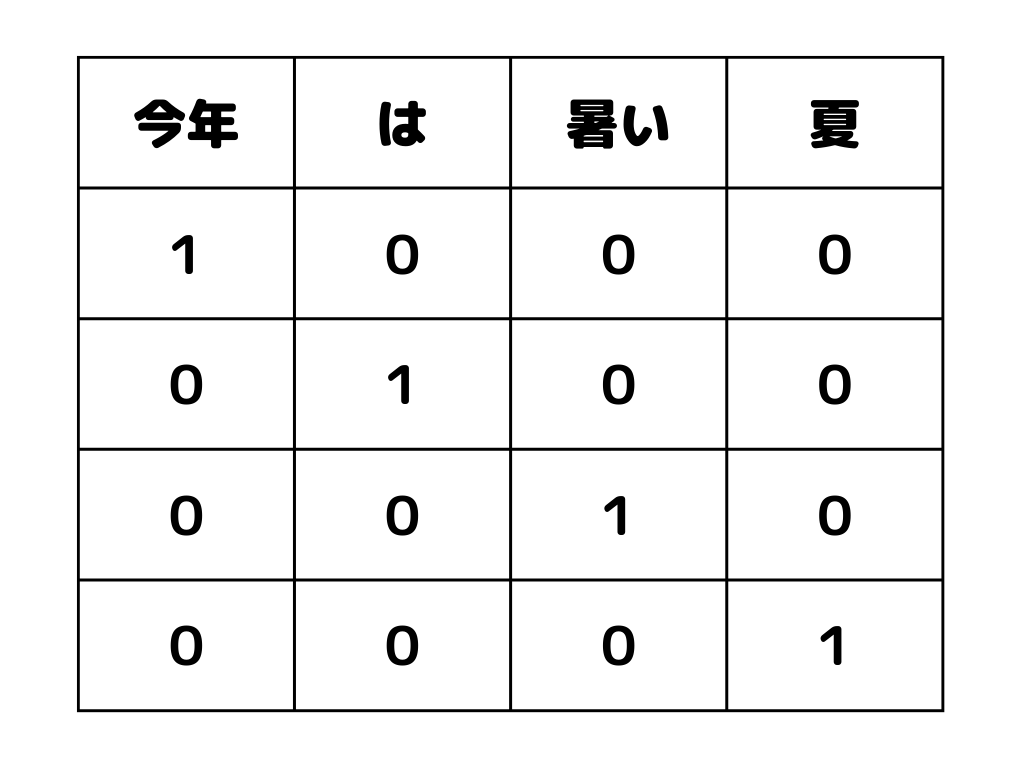
全ての単語を平等に扱いたいときに用いるようです。
しかし「1単語を独立したもの」として表現しているため、「単語同士の関連」が分かりません。
つまり、以下のようなデメリットがありました。
・「同じ単語かどうか」の判別くらいしかできず、それ以外は難しい
・世の中の単語を表現しようとすると、0が非常に多いベクトルになる

分散表現
局所表現では、できることが限られていたため、それを解決しようとしたのが分散表現。
分散表現は、一つの単語・文章を他の単語・文章に関連付けてベクトル化した表現。
つまりベクトル化したときに、似た意味の単語同士は近くになる、ということです。
単語の分散表現のイメージは以下の通り。
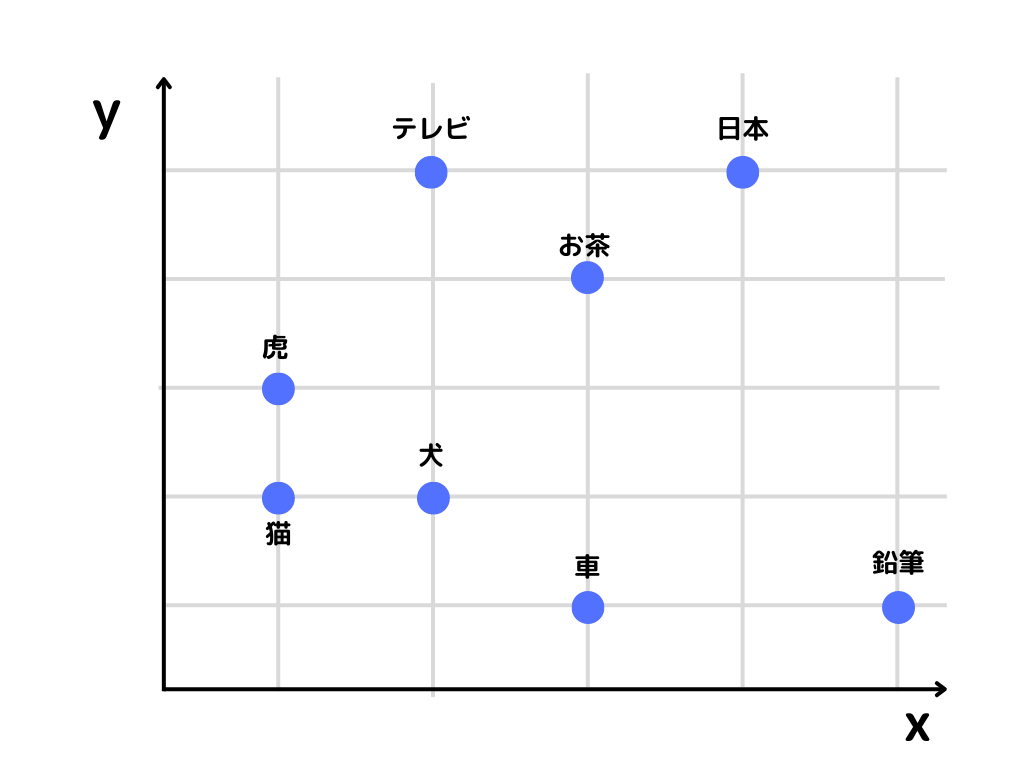
例えば「猫」という単語の位置は(x, y)という表し方をすると(1, 1)となり、単語を2つの数字で表せていますね。
単語をベクトル化できています。
さらに「猫と虎」「猫と犬」など、動物という意味で近い単語同士は上記の座標上で、近い位置にありますよね。
「単語埋め込み」とは、この分散表現をさすこともあるようです。
単語のベクトル表現
単語のベクトル表現とは、機械に単語を認識させるために重要な表現のこと。
「単語の埋め込み」の章でも話したように、機械は単語を判別できないので数字に直す必要があります。
この数字での表し方にはたくさんの種類があります。
・word2vec
・BoW (Bag-of-Words)
・TF-IDF
・fastText
・ELMo
それぞれについて、以下で詳しく見ていきましょう。
word2vec
word2vecとは、単語をベクトル化する技術。
word to vector(単語をベクトルへ)と覚えるといいでしょう。
名前の通り上記で色々と触れてきた、「単語の埋め込み」「ベクトル表現」の代表例ともいえるかと。
この手法には以下の二つがあります。
・スキップグラム
・CBOW
それぞれ簡単に見ていきましょう。
スキップグラム
スキップグラムとは中心の単語から、その周辺の単語を予測する手法のこと。
ニューラルネットワークに1単語を入力し、出力は周辺の単語となるようです。
CBOW
CBOWとは、周辺の単語から、その中心にある単語を予測する手法のこと。
スキップグラムとは逆で、入力が周辺の単語、出力が中心の単語となるようです。
BoW (Bag-of-Words)
BoW (Bag-of-Words)とは、カウントベースの単語をベクトルに直す手法のこと。
カウントベースというのは、単純に単語が出てきた回数を数えるという意味ですね。
手順は以下のような感じ。
1.文書内にその単語が出てきた回数だけ数える
2.行に文書、列に単語を並べた行列を作成することでベクトル化する
作成した行列のイメージは以下のような感じです。
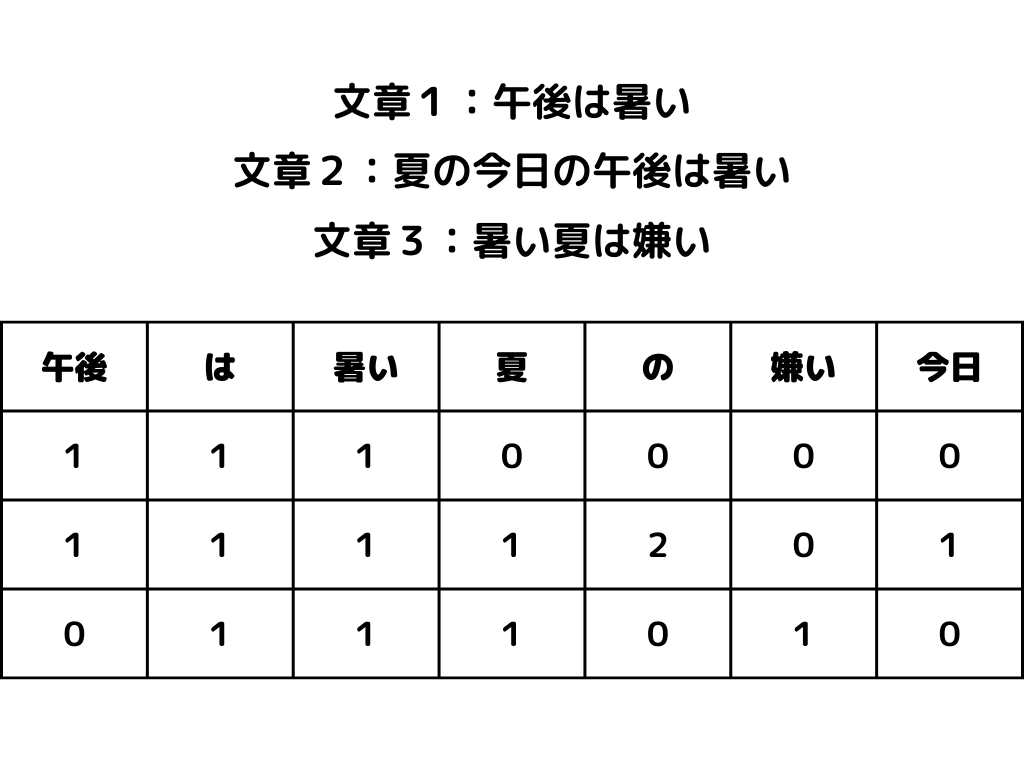
この方法のメリット・デメリットは次の通り。
メリット
シンプルで分かりやすいアルゴリズム
デメリット
単語の順番が考慮されない
文書が長いほど、どの単語も出現しやすくなる
特徴的な単語の影響が弱くなってしまう
TF-IDF
TF-IDFとは、文章内に含まれる単語が「文章内で」どれくらい重要かを表すための手法のこと。
この手法は文章が何種類かあって、その中でどの単語の重要性が高いのかを見たい時に使うものですね。
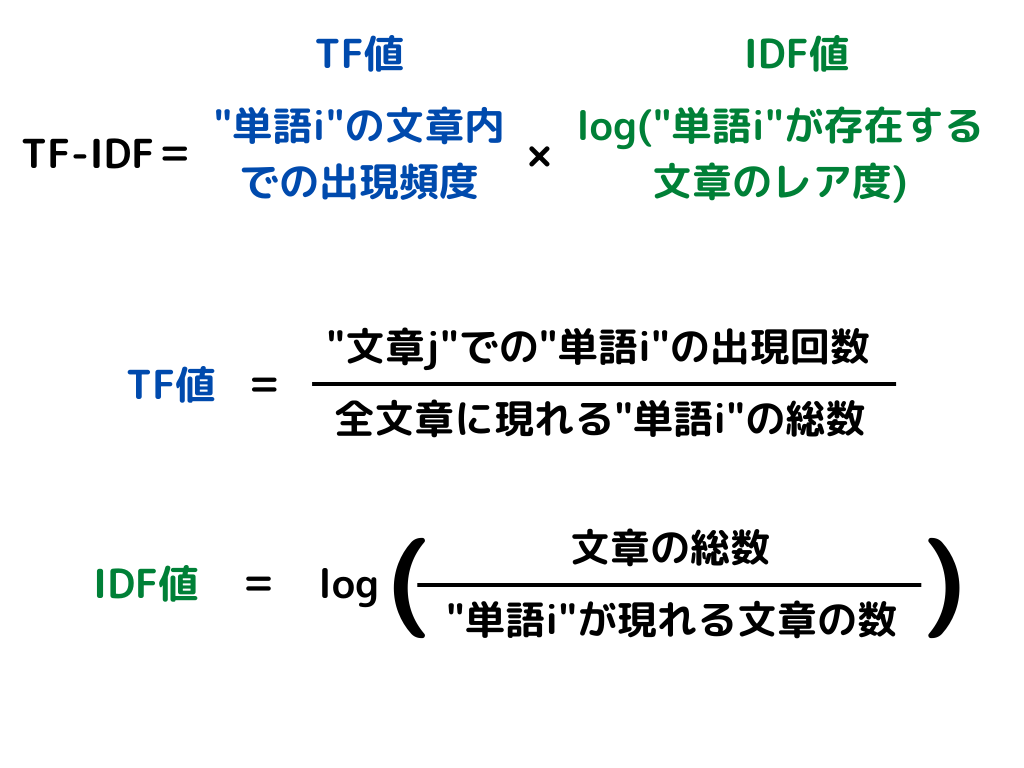
「単語の文章内での出現頻度」と「その単語が存在する文章のレア度の対数」の掛け算で表せます。
「単語の文章内での出現頻度」は、その単語が1つの文章内でどれだけ出てくるか
「その単語が存在する文章のレア度」は、単語がある文章がどれくらい出てきにくいか
を表しています。
式は次の通り。
bag of wordsと同じ例で計算してみると
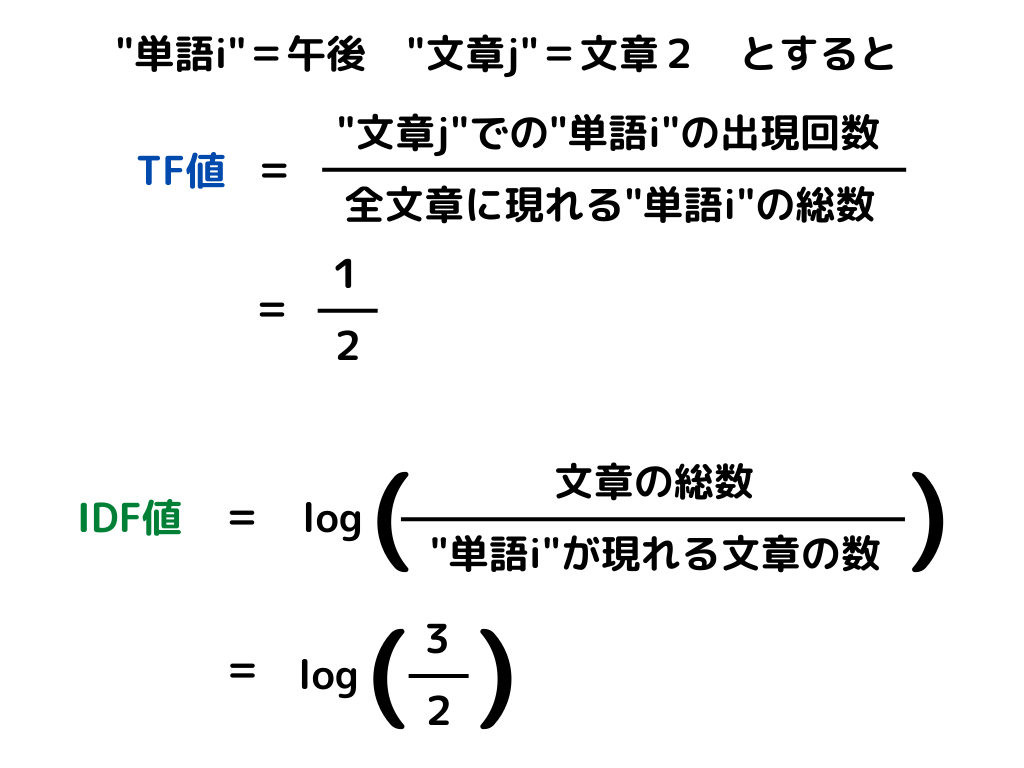
bag of words に比べレアな単語に注目できる、というのが特徴です。
fastText
fastTextとは、単語の埋め込みとテキスト分類を学習するためのライブラリのこと。
facebookのAI reserchラボによって作成されました。
ライブラリというのは機械学習モデルを、既に構築してまとめたもののことです。
0からプログラムしなくても、簡単に自然言語処理が行えます。
Word2Vec を元に作成されたようですね。
個々の単語を高速でベクトルに変換しテキスト分類を行うモデルです。
ELMo
ELMoとは、文脈に応じて単語の意味を表すことができるモデルのこと。
今までの方法では、単語ごとに固定の埋め込みを行っていました。
しかしELMoでは、文章の全体を見てから文章内の単語ごとの埋め込みを与えます。
この埋め込みを生成するには、特定のタスクに学習させた双方向LSTMを使用。
これによって、文脈に沿った単語の意味が理解できるようになったようです。
まとめ
今回は大項目「ディープラーニングの手法」の中の一つ「音声処理と自然言語処理」についての解説。第二弾でした。
本記事をまとめると以下の通り。
・言語モデル
・形態要素(形態素)解析
・構文解析
・単語埋め込み
・ベクトル空間モデル
・局所表現
・ワンホットベクトル
・分散表現
・単語のベクトル表現
・word2vec
・BoW (Bag-of-Words)
・TF-IDF
・fastText
・ELMo
ディープラーニングに関しても、細かく学習しようとするとキリがありませんし、専門的過ぎて難しくなってきます。
そこで、強化学習と同じように「そこそこ」で理解し、あとは「そういうのもあるのね」くらいで理解するのがいいでしょう。
そこで以下のようなことが重要になってくるのではないかと。
・ディープラーニングの特徴(それぞれの手法はどんな特徴があるのか)
・それぞれの手法のアルゴリズム(数式を覚えるのではなく、何が行われているか)
・何に使用されているのか(有名なもののみ)
ディープラーニングは様々な手法があるので、この三つだけでも非常に大変です。
しかし、学習を進めていると有名なものは、何度も出てくるので覚えられるようになります。
後は、新しい技術を知っているかどうかになりますが、シラバスに載っているものを押さえておけば問題ないかと。
次回は「ディープラーニングの手法」の「自然言語処理」の解説第三弾。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント