

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「機械学習の具体的な手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「機械学習の具体的な手法」の内容。
その中でも「モデルの評価」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
本記事の範囲は、合格に向けては必須の基礎知識になります。
これから先の機械学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
モデルの評価に関する内容が多くなってしまったので、記事を複数回に分割してお届けしようと思いますね。
モデルの評価というのは「作成したモデルが教師データや未知データに、どれだけ精度良く一致したか」を測るものになります。
つまり教師あり学習に用いられることが多い、というところは押さえておいてください。
精度評価指標はどこで使われるのか?
基本的には教師あり学習で用いられます。
教師あり学習の概要を以下に示しますね。
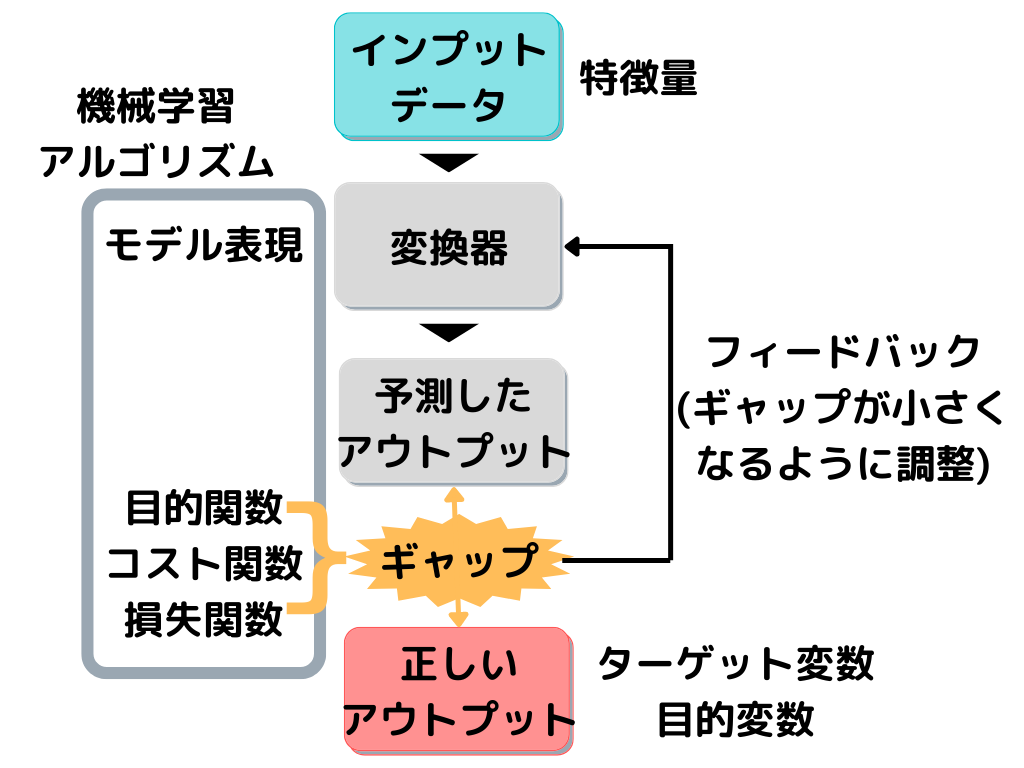
この図の「ギャップ」とある部分に、以下で紹介する精度評価指標が用いられます。
精度評価指標で出た「ギャップ(誤差)」が小さくなるように「変換器」を調整して、もう一回予測。
これを繰り返すことで、精度を高めて(ギャップを小さくして)いきます。
分類問題の精度評価指標
教師あり学習には、解きたい問題によって2種類ありましたよね。
それが
・分類問題
・回帰問題
それぞれの問題によって、評価指標は異なるものを使用します。
結果の値が連続値だったり、飛び飛びの値だったりするので、評価指標も変えていかなければいけません。
まずは、分類問題についての評価指標から見ていきましょう。

混同行列
混同行列とは、分類問題の精度評価指標の一種。
二値の分類問題を評価したいときには以下の様な行列を作成します。
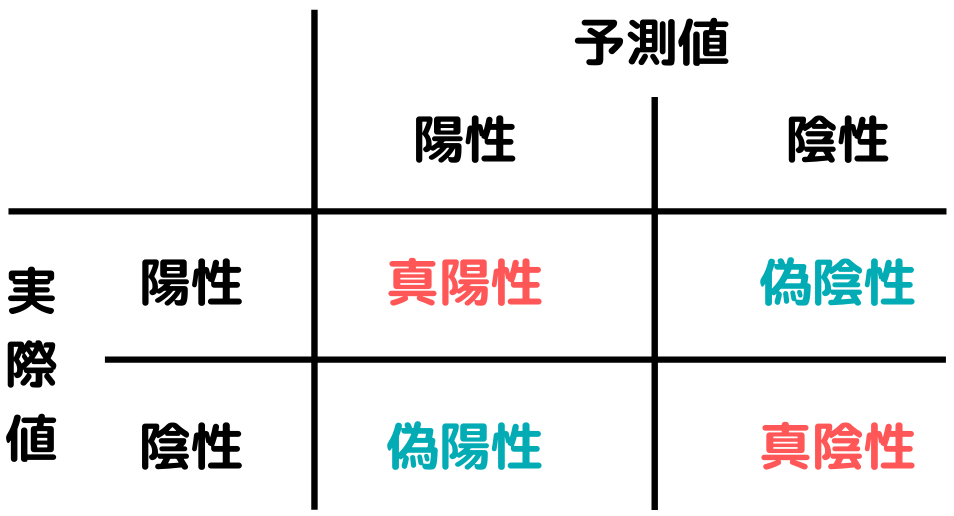
これが混同行列です。
この時に、予測値が実際のデータと一致していれば真陽性・真陰性といいます。
そして予測では陽性といっているのに、実際には陰性であること(混同行列の左下)を偽陽性
予測では陰性といっているのに、実際には陽性であること(混同行列の右上)を偽陰性といいます。
特に偽陽性と偽陰性が、よくごっちゃになるので、しっかり覚えたいですね。
予測値が陽性と出したものには、「陽性」と付きます。
この「陽性」が嘘か本当か、という意味で捉えると、分かりやすくなるのではないでしょうか。
混同行列を作って何をしたいかというと、以下の様な指標を考えるためです。
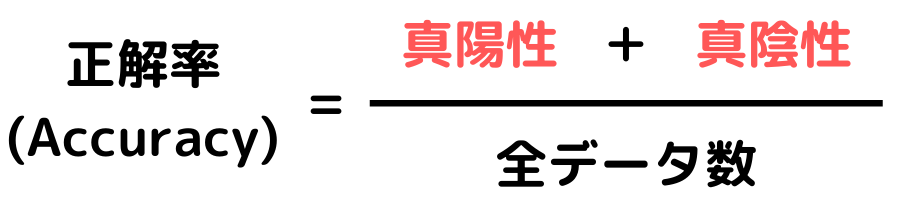
正解率(Accuracy):全データの中で「陽性・陰性」をどれだけ正確に判定できたかの指標
適合率(Precision):モデルの予測で「陽性」と判断した中で、どれだけ当たっていたか

モデルの予測が実際の値にどれだけ「適合」したか、という意味で「適合」率といえるのではないでしょか。
再現率(Recall):実際の値が「陽性」の中で、どれだけ当たっていたいか

実際の値をモデルの予測がどれだけ「再現」できたか、という意味で「再現」率といえるのではないでしょか。
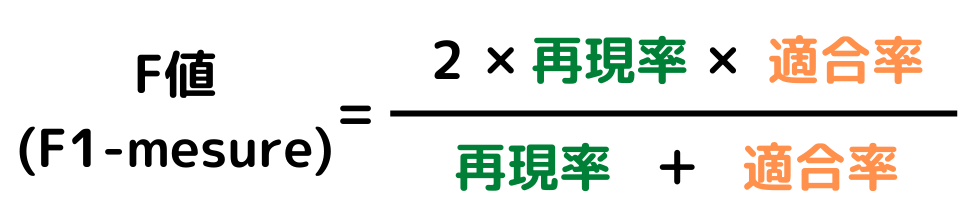
F値:再現率と適合率の調和平均
このそれぞれの指標を見ることで、モデルがどれだけ正確に予測できるのかを見ることができます。
適合率と再現率は間違えがちなので、しっかり覚えたいですね。
ROC曲線とAUC
ROC曲線とAUCを分かりやすくするために、作り方から順に説明します。(ROC曲線とAUCとは何か?については、この章の最後の図参照)
まず、ROC曲線やAUCはどうやって作っていくのか?
そのやり方を以下に書きますね。
1.閾値を決め真陽性率・偽陽性率を計算
2.横軸:偽陽性率、縦軸:感度(真陽性率)のグラフにプロット
3.閾値を変更する
4.1~3を繰り返す
偽陽性率と感度の式に関しては、以下に示します。
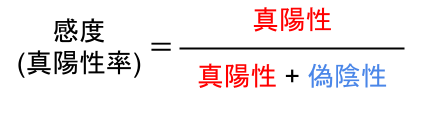
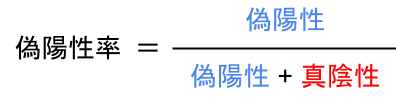
感度(真陽性率)の式、どこかで見たことありませんか?
実は、再現率(Recall)と同じ式なんです。
さらに偽陽性率とは混同行列でいう、「実際の値が”陰性”の中で、どれだけ間違っていたか」を示す指標です。(紛らわしいですよね)
そしてROCとAUCを図示すると、以下の様になります。
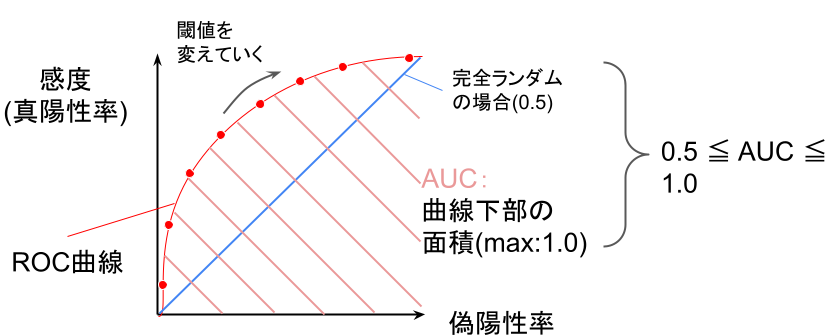
ROC曲線とは、上図の赤い曲線のこと。
AUCとは、上図の赤い斜線で示される面積のこと。
回帰問題の精度評価指標
先ほどまで、分類問題の指標を見てきました。
そして教師あり学習には、もう一つ問題がありました。
それが回帰問題。
結果の値が連続値になるような問題でしたね。
精度評価指標には以下の3つが代表例。
・MSE
・RMSE
・MAE
シラバスには載っていませんが、重要な指標なので、少しだけ解説します。
MSE(Mean Squared Error)
MSEとは、以下の式で表される誤差のこと。
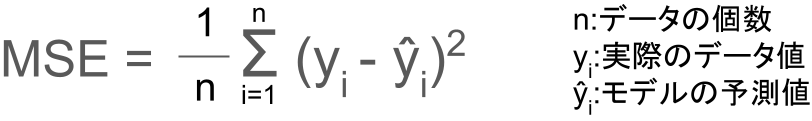
つまりは、残差を二乗したものの平均です。
MSEが小さくなるということは、残差が小さくなるので、より良いモデルと言えそうですよね。
RMSE(Root Mean Squared Error)
RMSEとは、以下の式で表される誤差のこと。
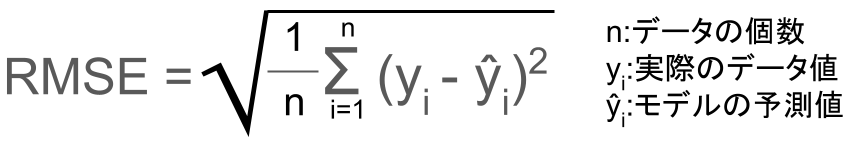
単純にMSEの平方根を求めたものになります。
MSEだと二乗されているので、値が大きくなりがちで、単位も二乗されてしまっています。
元の単位で表したいときなどに使えるようですね。
MAE(Mean Absolute Error)
MAEとは、以下の式で表される誤差のこと。
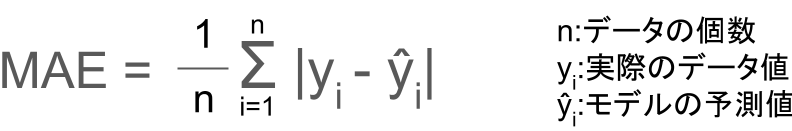
これは残差の絶対値の平均を取っています。
まとめ
今回は大項目「機械学習の具体的な手法」の中の一つモデルの評価についての解説でした。
本記事の重要キーワードは以下。
・混同行列
・正解率
・適合率
・再現率
・F値
・ROC曲線
・AUC
・MSE, RMSE, MAE
以上が大項目「機械学習の具体的な手法」の中の一つモデルの評価の内容でした。
MSE, RMSE, MAEに関しては、なぜかシラバスに載っていませんでしたが、重要だと思ったので取り上げさせてもらいました。
「正解率・適合率・再現率」は「どれがどれだっけ?」となりがちなので、しっかり覚えたいですね。
次回からは、大項目「機械学習の具体的な手法」の中の一つ「モデルの評価」の解説第二弾!
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント