

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「機械学習の具体的な手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「機械学習の具体的な手法」の内容。
その中でも「半教師あり学習」「強化学習」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
本記事の範囲は、合格に向けては必須の基礎知識になります。
これから先の機械学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
半教師あり学習・強化学習に関する内容が多くなってしまったので、記事を複数回に分割してお届けしようと思いますね。
半教師あり学習の概要
半教師あり学習とは、一部のみ教師データを用いてラベルなしデータの正解ラベルを予測する手法。
名前から予想できるとおり、教師あり・なし学習の間、といった感じでしょうか。
学習の進め方的には、教師あり学習
「一部のデータに教師ラベルがない」という意味では教師なし学習ですね。
全データの教師データが用意できなかった場合などに、使えます。
教師あり学習のイメージ図だけ、もう一度載せておきますね。
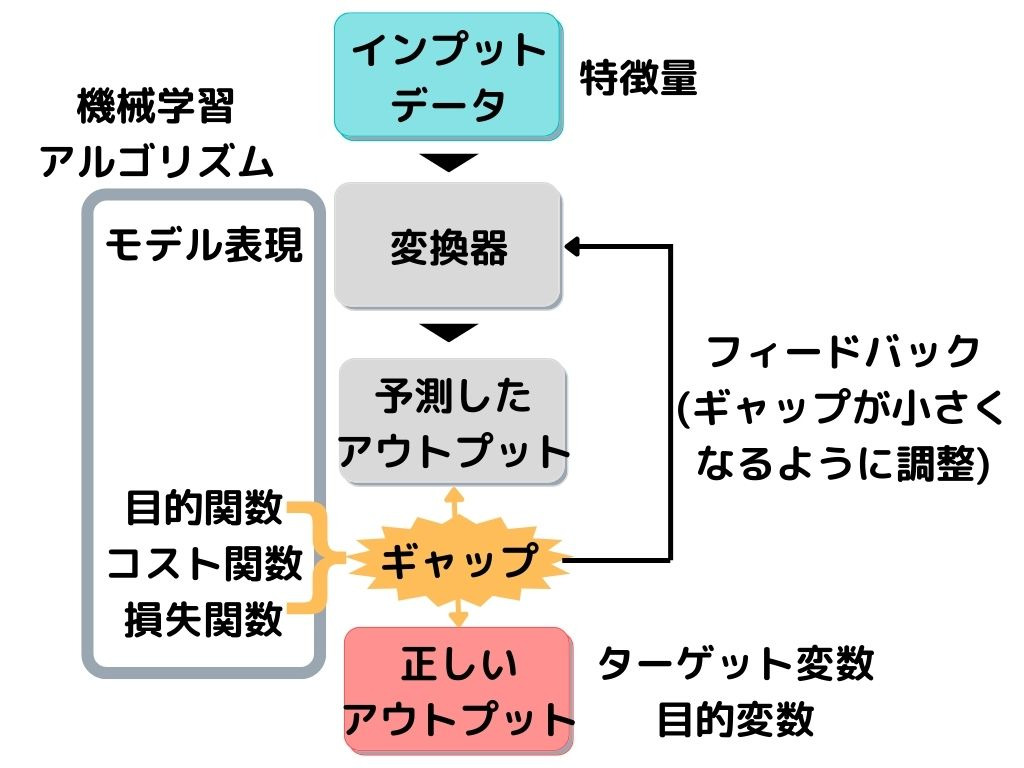
具体的な手順は以下の通り。
1.教師データがある訓練データで、教師あり学習を行い、モデル構築(一部には教師データがない)
2.できたモデルから、教師データが無いデータの教師データを予測
3.予測した教師データも含めて、モデルを学習し直す
このようにトレーニングデータの規模を大きくすることで、より良いモデルが構築できるようです。
強化学習の概要
強化学習とは、ある環境下で目的を達成するために、一連の行動結果の報酬を最大化するように学習する機械学習の手法こと。
具体的な手順としては以下の通り。
1.現在の「環境」から「状態」を観測する
2.「状態」から「方策」に基づいて、「行動」する
3.「行動」により変わった次の「状態」と「報酬」を付与する。
4.1に戻る
このように「教師あり学習」「教師なし学習」とは異なる、三種類目の機械学習手法です。
「方策」とは簡単に言うと、エージェント(ロボットなど学習主体)の行動選択のルールのこと。
「方策」に関しては、「方策反復法」のところで詳しく解説します。
イメージとしては以下の様な感じ。
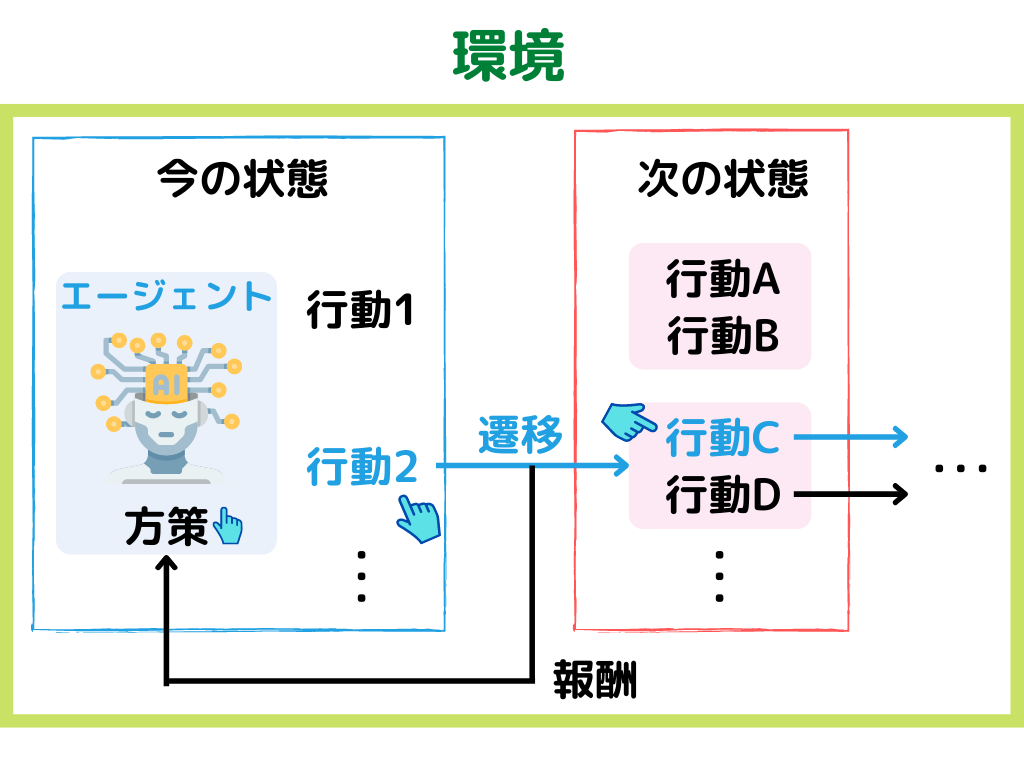
上の例では、「方策」で行動2を選んだ後、行動Cを選ぶ、という例です。
強化学習には以下の三種類の方法に分かれます。
・モデルベース手法
・価値関数ベース手法
・方策ベース手法
それぞれ見ていきましょう。

モデルベース手法
モデルベース手法は強化学習の1手法。
環境に対する情報(ある状態への遷移確率と報酬全て)が、完全である場合に適用できます。
つまり環境に対する情報というのは
この「行動」を取ったときに、どれくらいの「報酬」がもらえるか、つぎはどんな「状態」になるのか
これが、目的達成までの過程で全て分かっていることです。
オセロ・囲碁・将棋など、ボードゲームで使いやすいようですね。
モデルベースの具体的な手法としては
・方策反復法
・モンテカルロ木探索
があります。
方策反復法
方策反復法は、設定した「方策」に従った場合の全状態の価値を計算し方策を改善する手法のこと。
この改善がされなくなるまで行います。
価値は最大になるように、改善していきます。
「方策」とは、
こんな「状態」の時に、次はどう「行動」するのが良いのか、を表す確率分布の事です。
例えば迷路でロボットが前、右、左に分岐する道にたどり着いたとしますね。
この時「状態」は、分岐にたどり着いたロボットの位置、ということになります。
その時に「方策」は
・方策1は「前:33% 右:33% 左:33%」の確率で進む道を選ぶ
・方策2は「前:50% 右:25% 左:25%」の確率で進む道を選ぶ
と言ったようなイメージです。
ここで方策2に従った方が、方策1よりも迷路が解けるのであれば、以下のことが言えますね。
・方策2を使ったとき、今回の分岐にいること(状態)の価値は高い。
方策反復法は、ひたすら色んな種類の方策を試して「今分岐にいること」の価値が一番高い方策を、最適解とするイメージでしょうか。
モンテカルロ木探索
モンテカルロ木探索とは、「方策反復法」とは異なるモデルベース手法。
まずは、ある状態から行動選択を繰り返し複数回、報酬和を計算します。
先ほどの「迷路でロボットが前、右、左に分岐する道にたどり着いた」例だと、以下の様なことを行います。
・前に進む「行動」を20回繰り返して、一回の行動毎に「報酬」を計算する
・右に進む「行動」を10回繰り返して、一回の行動毎に「報酬」を計算する
・左に進む「行動」を15回繰り返して、一回の行動毎に「報酬」を計算する
そして行動の報酬値の平均を計算。
最も高い「報酬」がもらえる行動を取って、次の分岐(状態)へ…
と言うことを繰り返していきます。
この報酬和の平均値を、ある状態の価値とする方策推定方法がモンテカルロ木探索です。
報酬の平均が高い「方策」ほど、「今の分岐にいること」の価値が高い、ということですね。
まとめ
今回は大項目「機械学習の具体的な手法」の中の一つ強化学習についての解説でした。
本記事の重要キーワードは以下。
・半教師あり学習
・強化学習
・モデルベース手法
・価値関数ベース手法
・方策ベース手法
以上が大項目「機械学習の具体的な手法」の中の一つ強化学習の内容でした。
強化学習を深く理解しようとすると、高度な数学の知識が必要になってくるので「どこまでの理解をしておくか」を考えることが非常に重要です。
・学習の特徴(他の手法と比べて何が違うのか)
・学習の内部で行われていること(アルゴリズム) ※詳しい数式まで覚える必要はなし
・使用されている具体例(どの強化学習手法に用いられているか・現実問題にどう活かしているのか)
これらのことを覚えておくと、良いのではないでしょうか。
次回は、今回触れられなかった「価値関数ベース手法」と「方策ベース手法」の解説に移っていきたいと思います。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント