

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「機械学習の具体的な手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「機械学習の具体的な手法」の内容。
その中でも「強化学習」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
本記事の範囲は、合格に向けては必須の基礎知識になります。
これから先の機械学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
強化学習に関する内容が多くなってしまったので、記事を複数回に分割してお届けしようと思いますね。
強化学習の概要
強化学習とは、ある環境下で目的を達成するために、一連の行動結果の報酬を最大化するように学習する機械学習の手法こと。
具体的な手順としては以下の通り。
1.現在の「環境」から「状態」を観測する
2.「状態」から「方策」に基づいて、「行動」する
3.「行動」により変わった次の「状態」と「報酬」を付与する。
4.1に戻る
このように「教師あり学習」「教師なし学習」とは異なる、三種類目の機械学習手法です。
「方策」とは簡単に言うと、エージェント(ロボットなど学習主体)の行動選択のルールのこと。
「方策」に関しては、「方策反復法」のところで詳しく解説します。
イメージとしては以下の様な感じ。
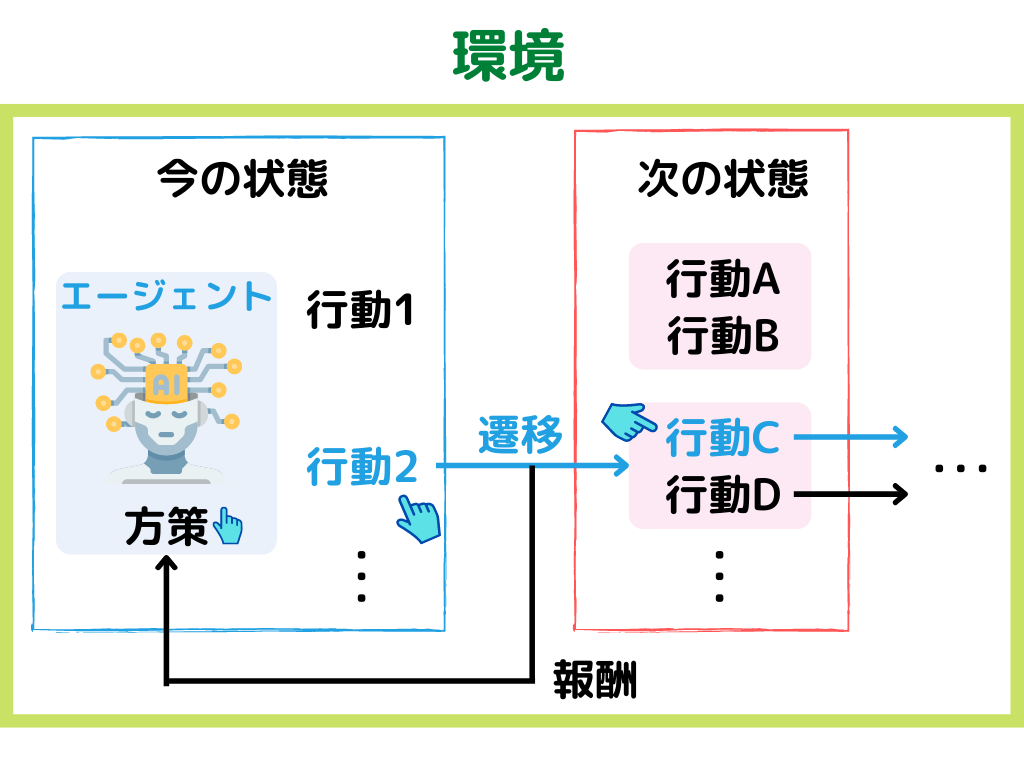
上の例では、「方策」で行動2を選んだ後、行動Cを選ぶ、という例です。
強化学習には以下の三種類の方法に分かれます。
・モデルベース手法
・価値関数ベース手法
・方策ベース手法
今回は「価値関数ベース手法」「方策ベース手法」それぞれ見ていきましょう。
価値関数ベース手法
価値関数ベース手法とは、強化学習の手法の1つ。
特に「価値関数ベース手法」と後述する「方策ベース手法」は、「モデルフリー手法」と言われることもあるようです。
モデルベース手法は、環境に対する情報(ある状態への遷移確率と報酬全て)が、完全である場合に適用できましたね。
しかし、現実世界で「どの状態において、どんな行動を取るか」を全て分かっている状況なんてまずないでしょう。
そこで用いられるのが「モデルフリー手法」。
環境に対する情報(ある状態への遷移確率と報酬全て)が、完全でなくても使用できます。
その中でも「価値関数ベース手法」は、
報酬の期待値を状態や行動の価値計算に反映し、高い価値の行動を選択するようにしています。
これは「報酬」は期待値によって、「環境に対する情報」は「報酬の期待値」で計算するんです。
なので、環境に対する情報(ある状態への遷移確率と報酬全て)が、完全でなくても適用できます。
価値関数ベース手法で使用する関数は、以下の2つ。
・状態価値関数
・行動価値関数
名前がややこしいですが、それぞれ見ていきましょう。

状態価値関数
状態価値関数とは、直近の報酬に1ステップ先の価値関数を足したもの。
ただし方策および遷移確率で未来のとりうる値は枝分かれするので、その期待値を取っていますね。
具体的には以下の式で表せます。

具体的な式まで覚える必要はありませんが、以下のことくらいは覚えておいても良いでしょう。
・「状態価値関数」は価値関数ベース手法に用いられる関数の一種
・「状態価値関数」は直近の報酬に1ステップ先の状態価値関数を足したもの
・「今の状態」の価値を表す関数
行動価値関数
行動価値関数とは、直近の報酬に1ステップ先の行動価値関数の期待値を足したもの。
具体的には以下の様な感じ。

具体的な式まで覚える必要はありませんが、以下のことくらいは覚えておいても良いでしょう。
・「行動価値関数」は価値関数ベース手法に用いられる関数の一種
・「行動価値関数」は直近の報酬に1ステップ先の行動価値関数の期待値を足したもの
・「今の行動」の価値を表す関数
Q値
Q値とは、以下の式で出てくる値のこと。
見覚えがないでしょうか?
直前の章で出てきた「行動価値関数」と同じ式です。
つまりQ値は、ある「状態」にいるときに今の「行動」にどれくらいの価値があるか、分かる値になります。
このQ値の最大化が、「価値関数ベース手法」の目的ですね
割引率
先ほどの式の中で、「時間割引率」というものが何かを説明していませんでしたね。
割引率とは、将来の価値をどれだけ割り引いて考えるかのパラメータのこと。
割引率の基本的な考え方としては、「将来に行くほど、報酬は小さくなる」というものです。
Q学習
Q学習とは、Q値学習アルゴリズム・強化学習の手法の一つ。
次の状態の価値の見積もりを、現在推定されている最大値で計算することですね。
先ほどまでで出てきた「状態価値関数」と「行動価値関数」を使って、価値の計算を行っていきます。
どちらの関数も、「現在の価値」を計算するために「次の状態の価値」を使用していましたよね。
この「次の状態の価値」の最大値を使用する方法が、Q学習です。
さらにQ学習にディープラーニングを組み合わせたアルゴリズムをDQN(Deep Q-Network)といいます。
これについては、後の記事で書きますね。
TD誤差学習
TD誤差学習とは強化学習の手法の一つであり、自身の評価を行って更新していく手法。
評価値の更新にTD誤差を用い、0に近づけていきます。
TD誤差というものを用いているため、TD誤差学習と言われるようですね。
シラバスには載っていないので、これくらいに留めておきます。
Actor-Critic
Actor-CriticとはTD誤差学習の一つであり、行動選択に最小限の計算量しかいらず、確率的な行動選択を学習する手法。
応用では、ロボットの制御などロボット工学などでも活用が進んでいるようです。
「行動を選択するActor」と、「Q関数(行動価値関数)を計算することで行動を評価するCritic」を交互に学習。
そうすることで、精度の向上を図っていくようです。
方策ベース手法
方策ベース手法とは強化学習の1手法であり、モデルフリー手法の1つ。
「モデルフリー手法」とは、環境に対する情報(ある状態への遷移確率と報酬全て)が、完全でなくても使用できるものでした。
具体的な手順としては、以下の2ステップ。
1.現在の方策での報酬の期待値と方策を見比べる。
2.どのように方策を変化させれば、報酬の期待値が大きくなるかを直接計算する。
「方策」とは、
今の「状態」の時に、次はどう「行動」するのが良いのか、を表す確率分布の事でしたね。
そして、ここで言う「報酬」とはQ値のことです。
「方策」を変えるということは、どの行動を取る確率を増やすか、ということになります。
方針は「報酬(Q値)の期待値が大きくなるように」です。
価値関数ベース手法では、あくまで「状態」と「行動」の価値関数を状態ごとに毎回計算することで、どう行動するのかを決めていました。
方策ベース手法では、どの行動を取る確率を増やすかという「方策」を、一連の行動を行った後に直接計算する方法になります。
方策勾配法
方策勾配法とは、方策ベース手法でもちいる手法。
具体的な手順は以下の通り。
1.まず初期方策を定義する。
2.初期方策で一連の行動をする。
3.行動の結果から、初期方策を評価。
4.評価値と方策から「方策勾配定理」を用いて、方策を更新
5.もう一度、一連の行動をする
6.3から繰り返し
方策を更新するときには、評価値が最大化するように、更新していきます。
「方策勾配定理」に関しては詳しい式を覚えるのではなく、「方策勾配に用いられる定理」くらいの理解で大丈夫かと。
方策ベース手法の基本的な考え方なので、抑えておきたいところですね。
REINFORCE
REINFORCEとは方策勾配法の一種で、一連の行動によって得られた報酬の平均をQ値とする方法。
方策勾配法では「方策を評価する」事が重要です。
評価して評価値が出ないと、方策が更新できませんからね。
評価に用いられるのが、「価値関数ベース手法」でも出てきたQ値です。
価値関数ベース手法では、Q値(Q関数)を行動毎に更新してたと思います。
しかし行動の選択が多すぎると、計算が膨大になり、適切な価値関数を定めることは難しそうですよね。
そこでREINFORCEは、全ての行動を終えてから得られる報酬の平均で、方策を評価しようというもの。
これにより方策を評価し、直接方策を改善していきます。
まとめ
今回は大項目「機械学習の具体的な手法」の中の一つ強化学習についての解説、第二弾でした。
本記事の重要キーワードは以下。
・価値関数ベース手法
・状態価値関数
・行動価値関数
・Q値
・割引率
・Q学習
・Actor-Critic
・方策ベース手法
・方策勾配法
・REINFORCE
以上が大項目「機械学習の具体的な手法」の中の一つ強化学習の内容でした。
今回は結構情報量が多くなってしまいましたね。
強化学習は深く理解しようと思うと超難しいので、G検定合格においては以下のことが大事かと。(りけーこっとんも、まだよく分かってません)
・学習の特徴(他の手法と比べて何が違うのか)
・学習の内部で行われていること(アルゴリズム) ※詳しい数式まで覚える必要はなし
・使用されている具体例(どの強化学習手法に用いられているか・現実問題にどう活かしているのか)
次回は「強化学習」最後の章です。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント