

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「ディープラーニングの手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの手法」の内容。
その中でも「画像認識分野」に焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
ここを理解していないと、G検定に合格も難しいでしょう。
難しく内容も多い部分ですが、しっかり覚えていきたいですね。
今回は画像認識分野の中でも「物体識別」について押さえていきたいと思います。
画像認識タスク
画像認識タスクには、以下の3つに大別されます。
・物体識別タスク
・物体検出タスク
・セグメンテーションタスク
それぞれのタスクで、非常にたくさんの手法が開発されています。
そこで本記事では、それぞれのタスク毎に手法を分けて解説していきますね。
本日は物体識別タスクについて触れていきましょう。
物体識別タスク
物体識別タスクとは画像の物体が何か、識別するタスクのこと。
画像認識というと、このイメージを持つ人が多いのではないでしょうか。
画像に写っている物体が、事前に定義されたラベル(車、猫など)のどれに分類されるか識別するタスクです。
あくまでも「事前に定義されたラベル」に無い種類は判別できないということに注意して下さい。
ILSVRC
ILSVRCとは、ImageNet Large Scale Visual Recognition Challengeの略。
前の記事でも触れているのですが、何だったか覚えているでしょうか。
画像認識の分類精度を競う競技会のことですね。
名前が長すぎるので「ImageNet」と呼ぶ人も多いようです。
この大会で優勝すると、そのモデルが話題になるということが何回も起きています。
第三次AIブームの引き金になったのも、この大会で優勝したチームのモデルからですね。
AlexNet
AlexNetとは、2012年ImageNetでトロント大学チームが優勝したモデルのこと。
ディープラーニングモデルで、LeNetの構造を変形したものになります。
LeNetを忘れてしまった人は、リンクから飛んでみて下さい。
GPU上で演算ができるように設計されているようです。
GPU性能自体も、ここ数年で飛躍的に向上している点も、精度が向上した要因の1つですね。
GoogleNet
GoogleNetは、Googleが開発した22層まで深くしたCNN。
22層というのは、「畳み込み層」「プーリング層」「全結合層」の層を22個作った、という意味ですね。
GoogleNetは、2014年のImageNetで1位を獲得しています。
このモデルの特徴は、Inceptionモジュールが使われているということ。
Inceptionモジュールについては、後に説明します。
さらに、GAP(Global Average Pooling)を導入することでパラメータ数を削減し、過学習を抑制しているようです。
Inception モジュール
Inception モジュールは、複数の畳み込み層やプーリング層で構成された小さいネットワークのこと。
GoogleNetに使われていて、たくさんのInceptionモジュールが存在しています。
処理の流れとしては以下の通り。
1つの入力画像に対して、複数の畳み込み層(1×1,3×3,5×5)を並列に適用
→最後にそれぞれの計算結果を連結
Inceptionモジュールも聞かれることがあるので、GoogleNetとセットで覚えておきましょう。

VGGNet
VGGNetは、オックスフォード大学のチームが開発し、16や19層まで深くしたCNN。
16や19層というのは、GoogleNetと同じように「畳み込み層」「プーリング層」「全結合層」の層を22個作った、という意味ですね。
2014年のImageNet、物体の位置検出分野で1位。
画像分類でGoogleNetに継ぐ2位でした。
たまに「●●年のImageNetの優勝モデルは?」みたいなことを聞かれることもあるので、覚えられれば年、順位まで覚えましょう。
2014年のImageNetは重要なモデルが多く、何が優勝したのか、何位だったのかが分からなくなるので注意が必要ですね。
VGG16
VGG16は、16層まで深くしたCNNのこと。
16という数字は、層の数を表しているわけですね。
13層の畳み込み層と3層の全結合層で構成されています。
他にVGG19というものもありますが、数字の通り19層まで深くしたCNNのことです。
VGG19もVGG16も同じ、2014年ImageNetのモデルなのでGoogleNetと合わせて覚えたいですね。
ResNet
ResNetとは、2015年のImageNetで1位を獲得したCNN。
特徴としてはまず、層の数が圧倒的に増えました。
その数なんと152層。
前年までのモデル達とは、桁が違いますね。
さらにもう一つの特徴として、スキップ結合を持っていることが挙げられます。
スキップ結合
スキップ結合とは、層を飛び越えて結合している構造のこと。
skip-connectionと書かれることもあります。
論文から抜粋すると以下のような感じ。
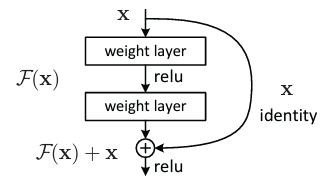
この図で右に大きく出ている矢印(x)がスキップ結合です。
下にある「丸で囲まれた+」は残差ブロックと言われます。
スキップ結合は、weight layerという層を2つ飛び越えていますよね。
さらに左側の縦一直線に並んでいる層(weight layer×2)は一般的なCNNのイメージ。
残差ブロックは「一般的なCNNの結果」と「スキップ結合の結果」を合計したものです。
weight layerが何かということまでは分からなくても良いですが、スキップ結合のイメージは付くようにしておきましょう。
Wide ResNet
Wide ResNetとは、次元数(フィルタ数)を増やしたResNetの改良版。
ResNetも層を深くすれば精度は上がりますが、増えすぎると以下の様な問題が出てくるようです。
・計算量の増加
・数%の精度向上に数百~数千層の追加が必要
では層を深くする代わりに次元数(フィルタ数)を増加させた、というのがWideResNetですね。
どこの次元数を増やしたかというと、先ほどの図、
の左側(一般的なCNNのイメージ)です。
次元数が増えるということは、たくさんの種類の特徴を抽出できることになります。
これで精度が向上したようですね。
次元の広がりがあるので、Wide ResNetと呼ばれるのかと。
DenceNet
DenceNetとは前方の各データ出力を、後方全ての層の入力に利用するResNetの改良版。
何言ってるのか分かりにくいですよね。
論文の図を使いながら、説明していきます。
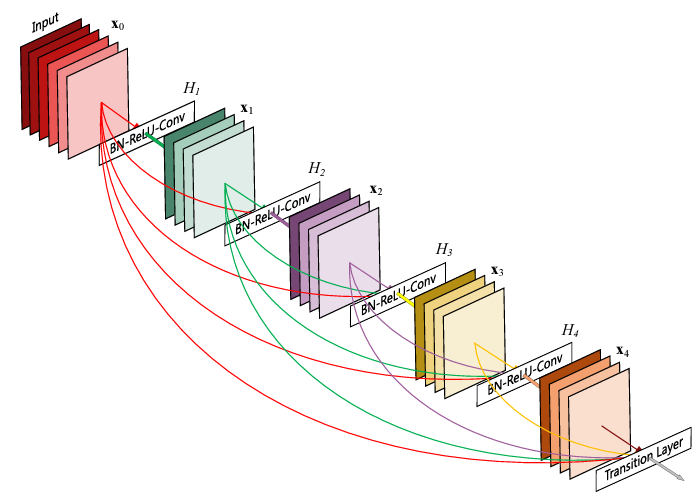
赤・緑で色分けされた四角は、特徴マップです。
H1、H2…で表されている「BN-ReLU-Conv」が、ResNetと同じ構造になっています。
例えば赤い矢印について見てみましょう。
矢印はデータが入力される方向を表しています。
まず「BN-ReLU-Conv」に向かっている矢印はResNetの「一般的なCNN」と同じ。
そして、下に大きく出ている赤い矢印が「スキップ結合」です。
スキップ結合が、同じ所からH2・H3・H4にそれぞれ伸びているのが特徴ですね。
同じように緑・紫…と繰り返していきます。
この構造をDenceBlockとも言うようです。
後ろから前へのスキップ結合はないので注意して下さい。
SENet
SENetとは、畳み込み層の出力に重み付けをしたCNN。
通常のCNNでは、各チャンネル(特徴マップの種類)は均等に出力されます。
チャンネルとは何だったか、覚えていますか?
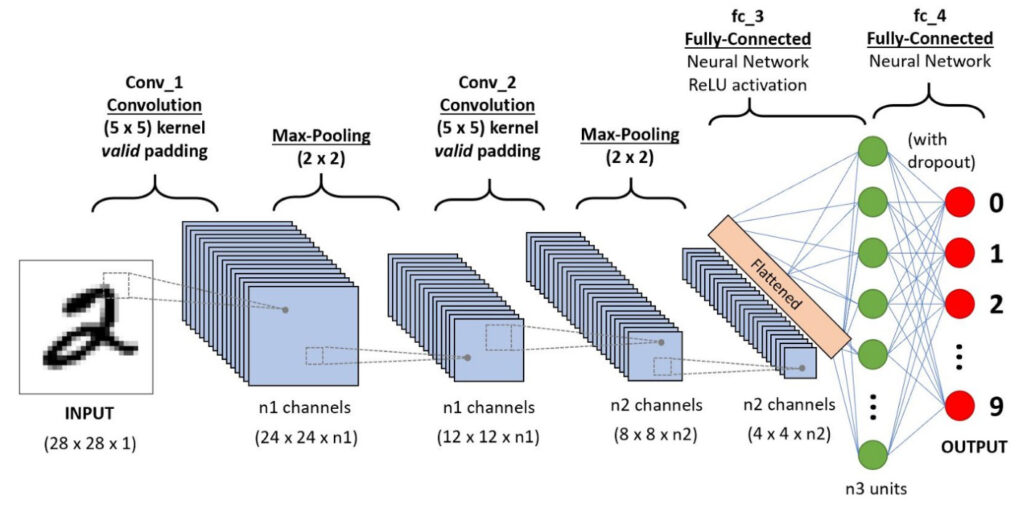
この図のn1やn2に当たる部分ですね。
特徴マップの種類の数とも言うことができます。
では、チャンネルに重み付けをすると何が起こるのか。
情報価値の高い特徴マップを強調して、比較的価値の低いものを抑える
ということができます。
つまり、畳み込み層の出力に重み付けをすることでパラメータ数と次元数を削減し、表現力の
向上を目指したのがSENetですね。
まとめ
今回は大項目「ディープラーニングの手法」の中の一つ「画像認識分野 物体識別」についての解説でした。
本記事をまとめると以下の3つ。
・物体識別タスク
・ILSVRC
・AlexNet
・GoogleNet
・Inceptionモジュール
・VGGNet
・ResNet
・スキップ結合
・Wide ResNet
・DenceNet
・SENet
以上が大項目「ディープラーニングの手法」の「画像認識分野 物体識別」の内容でした。
ディープラーニングに関しても、細かく学習しようとするとキリがありませんし、専門的過ぎて難しくなってきます。
そこで、強化学習と同じように「そこそこ」で理解し、あとは「そういうのもあるのね」くらいで理解するのがいいでしょう。
そこで以下のようなことが重要になってくるのではないかと。
・ディープラーニングの特徴(それぞれの手法はどんな特徴があるのか)
・それぞれの手法のアルゴリズム(数式を覚えるのではなく、何が行われているか)
・何に使用されているのか(有名なもののみ)
ディープラーニングは様々な手法があるので、この三つだけでも非常に大変です。
しかし、学習を進めていると有名なものは、何度も出てくるので覚えられるようになります。
後は、新しい技術を知っているかどうかになりますが、シラバスに載っているものを押さえておけば問題ないかと。
次回は「ディープラーニングの手法」の中の一つ「画像認識分野 物体検出」に触れていきたいと思います。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント