

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「ディープラーニングの概要」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの概要」の内容。
その中でも「ディープラーニングのアプローチ」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
今回はディープラーニングの概要ということもあって、ディープラーニングの基礎的な内容。
ここを理解していないと、ディープラーニングがどういうものかを理解できません。
ここから先の学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
今回はディープラーニングの主な枠組みや、基本的な用語を押さえていきたいと思います。
今までの記事で、見たことある単語も出てくるとは思いますが、復習の意味も兼ねて触れていきますね。
オートエンコーダ
オートエンコーダとは、ニューラルネットワークを用いた次元削減の基本的な構造。
ディープラーニングなどモデルに適用する前の事前学習の一つですね。
入力層、隠れ層、出力層の3層で構成され、入出力の形が同じになるようになっています。
隠れ層は、入力層に対して「次元数が少なくなるように」調整。
こうすることで隠れ層は、元のデータの特徴をなるべく損なうことなく、より少ない次元で表現できることになりますよね。
調整した隠れ層を、モデルの入力層とすることで「次元が削減された(エンコード)」データを扱えて、計算量が減らせます。
オートエンコーダのイメージ図は以下のような感じ。
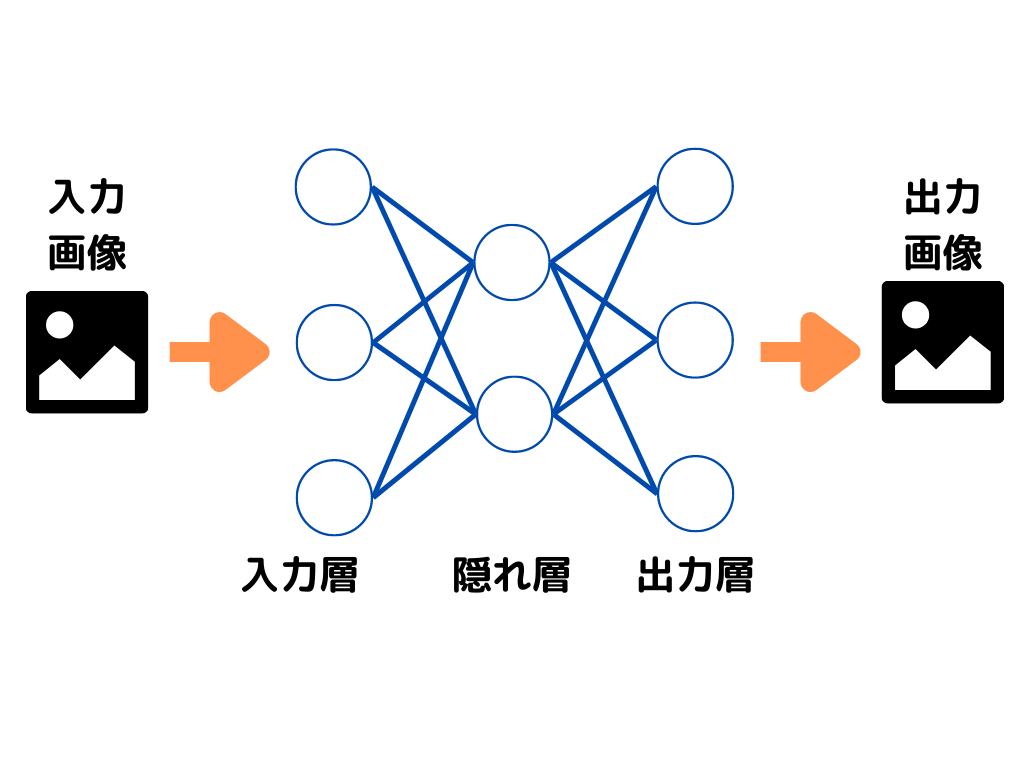
特に画像のように、データ量が膨大になってくると、計算に時間がかかってしまいます。
なので、こういった次元削減が重要ということですね。
ちなみに「教師なし学習」でできることの代表例としても「次元削減」があったと思います。
覚えているでしょうか?
忘れてしまった方はリンクから復習してみてください。
積層オートエンコーダ
積層オートエンコーダとは、オートエンコーダを多層にしたもの。
つまりオートエンコーダの「隠れ層」が増えたもの、ということになりますね。
こちらも事前学習の一つになります。
積層オートエンコーダの学習過程イメージは以下の通り。
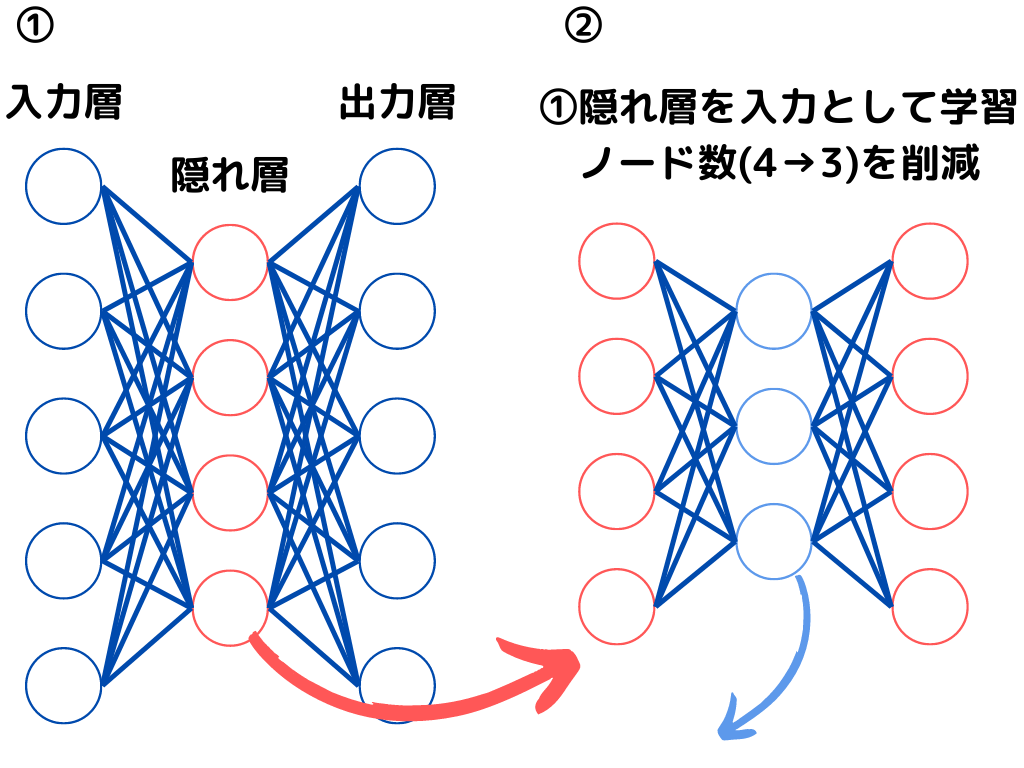
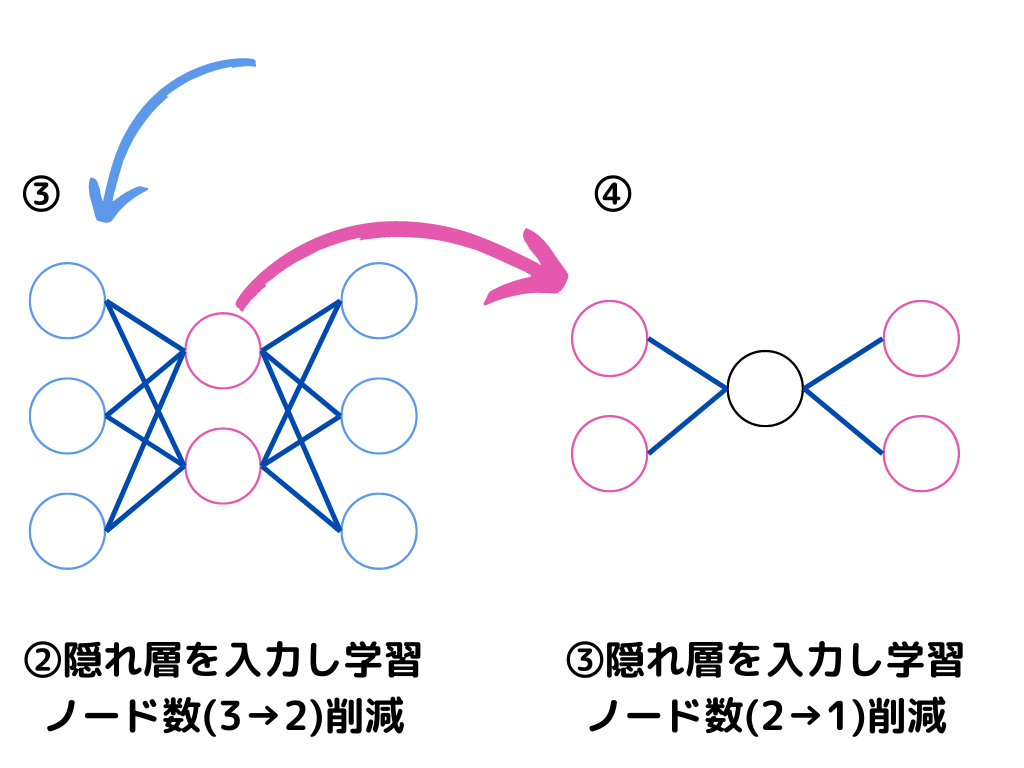
このように、入力層に近い層から順に逐次的に学習行います。
しかし、あくまで事前学習なので「隠れ層の学習」しかできていません。
実際に使用する際には、以下の図のように出力層を付け加えてモデルが完成します。
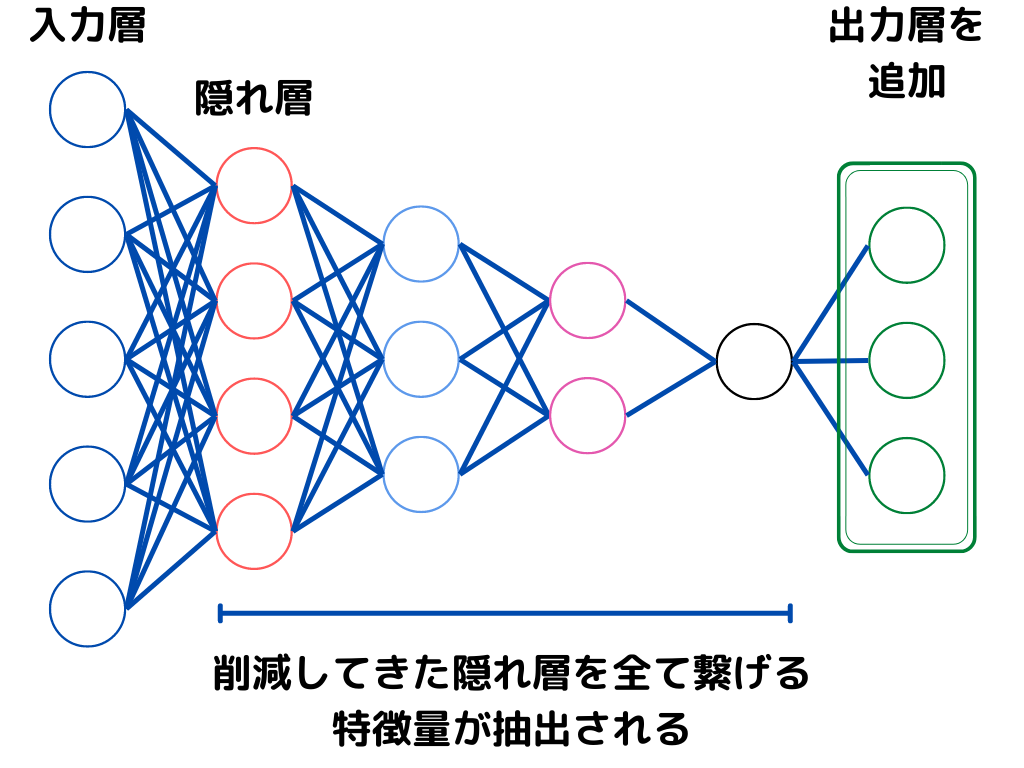

転移学習
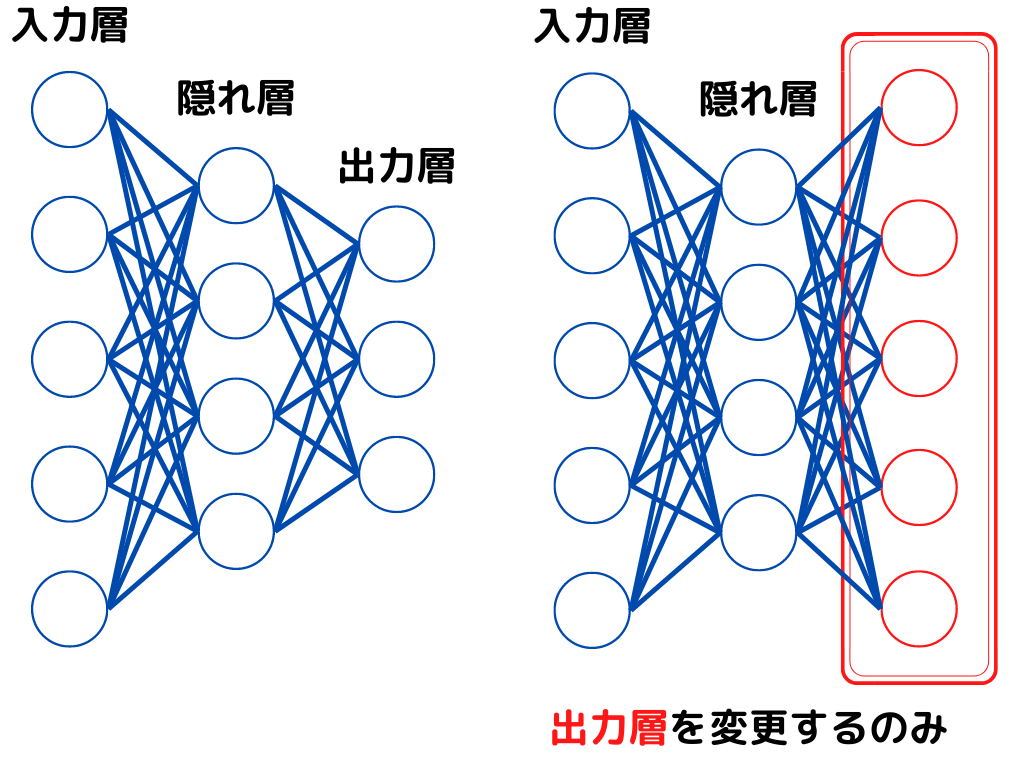
転移学習とは、学習済みモデルを使用して別の出力に利用する学習方法。
すでに学習は終了しているため、学習が早く進みます。
転移学習と似た方法に「ファインチューニング」と「蒸留」があるので、二つとの違いを押さえましょう。
転移学習は最終出力層を入れ替えるのみで、重みの更新は行いません。
転移学習のイメージは以下の通り。
次はファインチューニングについて触れたいと思います。
ファインチューニング
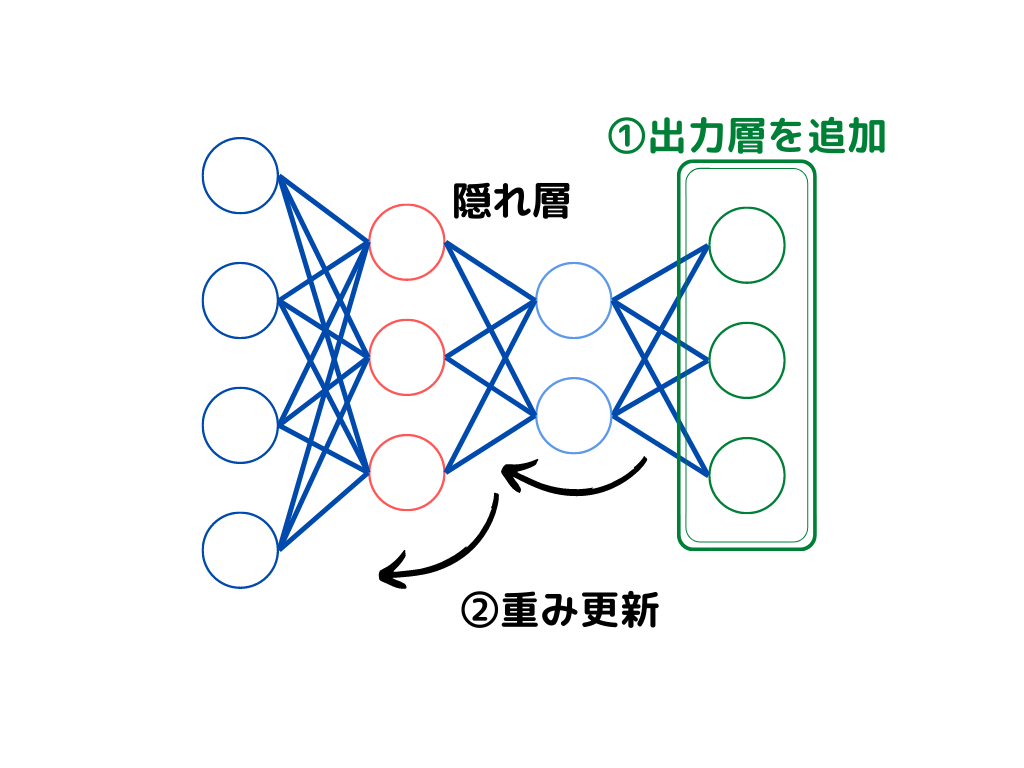
ファインチューニングとは最終出力層の追加学習と、ニューラルネットワークの重み更新を行う学習方法。
転移学習では最終出力層を入れ替えるだけでしたが、ファインチューニングはそこに「重み更新」が加わります。
ファインチューニングの学習イメージは以下の通り。
蒸留
蒸留とは、すでに学習してあるモデルを使用し、より軽量なモデルを生み出すこと。
転移学習やファインチューニングのように、「すでに学習してあるモデル」を使用することは同じです。
しかし「より軽量な」モデルを作成することに目的を置いてますよね。
似たモデルで、出力を別のものに転用したい「転移学習」「ファインチューニング」とは目的が異なりそうです。
これまでに説明した「転移学習」「ファインチューニング」「蒸留」は混同しがちなので、違いも含めて覚えておくといいでしょう。
深層信念ネットワーク
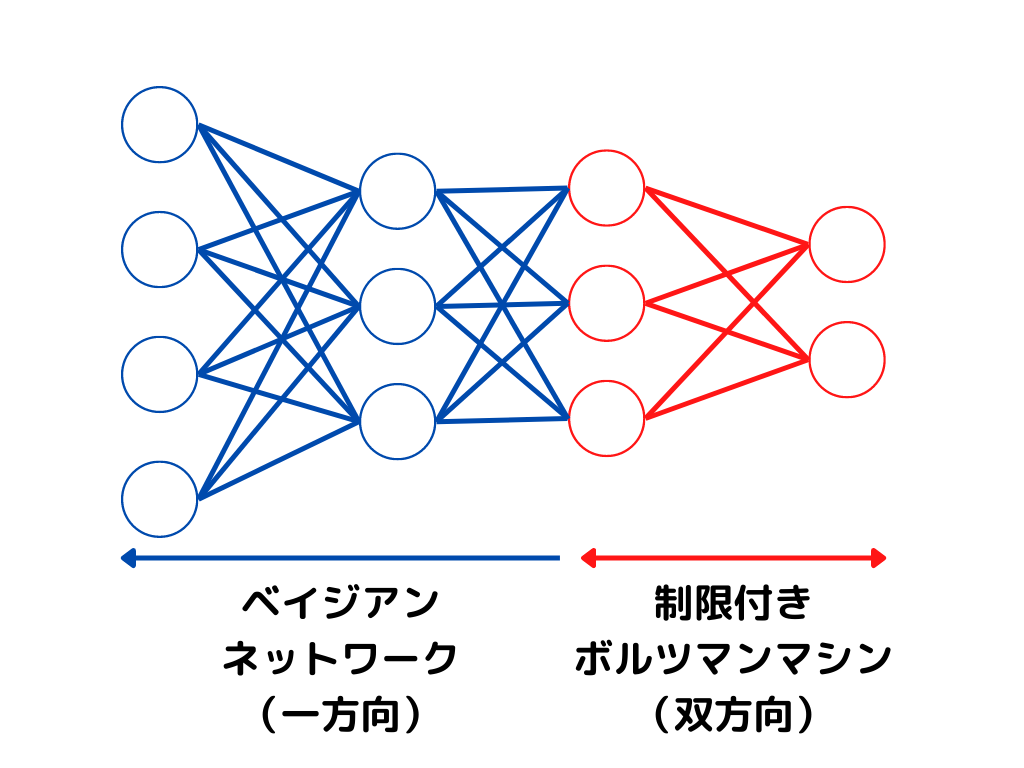
深層信念ネットワークとはニューラルネットワークの一種で、隠れ層の出力は0か1しか取らないもののこと。
深層ボルツマンマシンの最深層のみを制限付きボルツマンマシンにしたものです。
イメージ的には以下の図のような感じ。(何を言っているのかわからない人もいると思うので、後の章で解説します。)
ベイジアンネットワークとは、”「原因」と「結果」が互いに影響を及ぼしながら発生する現象をネットワーク図と確率という形で表した”ものです。(参考:https://www.hitachi-hri.com/keyword/k052.html)
G検定のシラバスには載っていなかったので、詳しく知りたい方は参考先のリンクを見てみてください。(イメージとしては上の図がネットワーク図で、後は確率を計算したもの)
教師なし学習に用いられるようですね。
このように深層ボルツマンマシンと、制限付きボルツマンマシンの考え方が使用されています。
ボルツマンマシンについては以下で詳しく述べたいと思います。
ボルツマンマシン
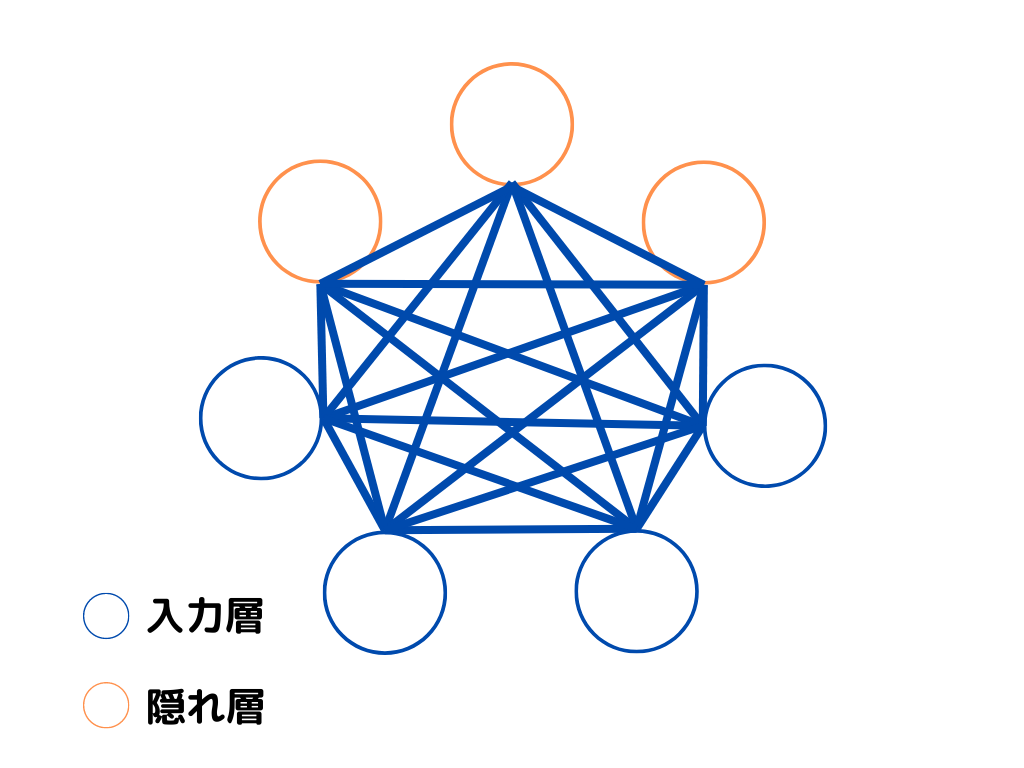
ボルツマンマシンとは、1985年ジェフリー・ヒントンらによって提案されたニューラルネットワークの一種。
入力層と隠れ層の二つのみからなり、入力を伝えるか否かを確率的に行います。
さらに異なる層だけでなく、同じ層内でも情報を双方向に交換し合うので、複雑な組み合わせ問題を解くことができたようです。
イメージは以下のような感じ。
隠れ層に入力層の特徴が抽出されます。
制限付きボルツマンマシン
制限付きボルツマンマシンとは、隠れ層内でノード同士でのやりとりがないボルツマンマシンのこと。
イメージは以下のような感じです。
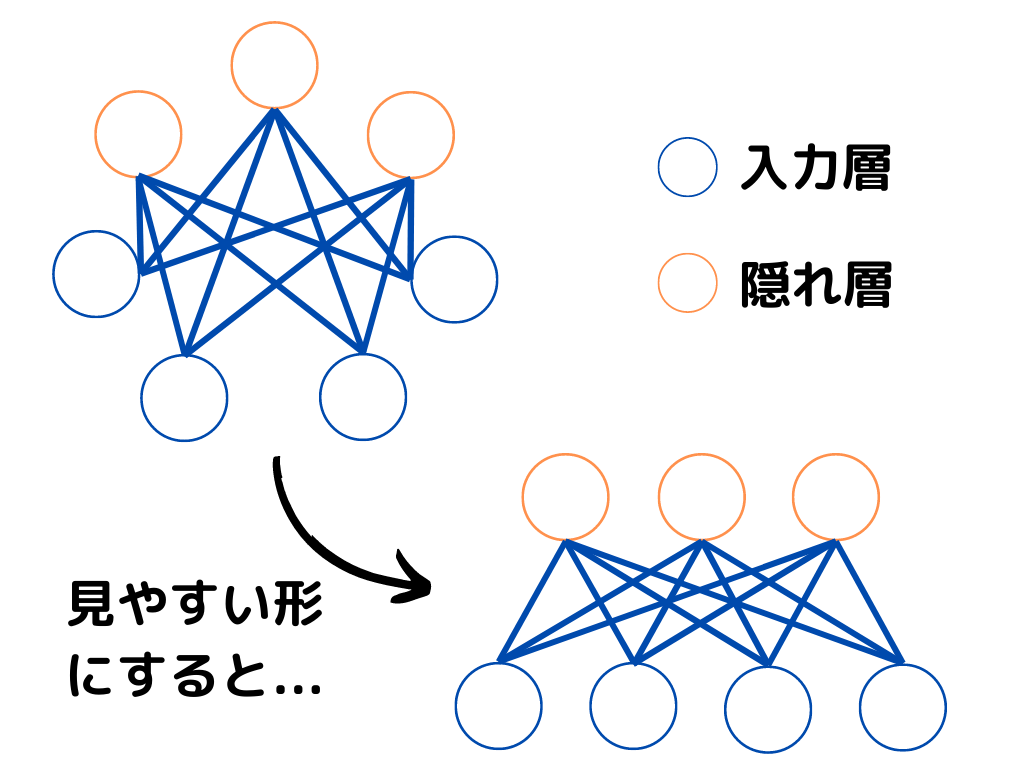
双方向に情報がやり取りできるのは変わらないですが、同じ層同士の結合がなくなりました。
深層ボルツマンマシン
深層ボルツマンマシンとは、制限付きボルツマンマシンを何層にも重ね合わせたもの。
イメージ図としては以下のような感じです。
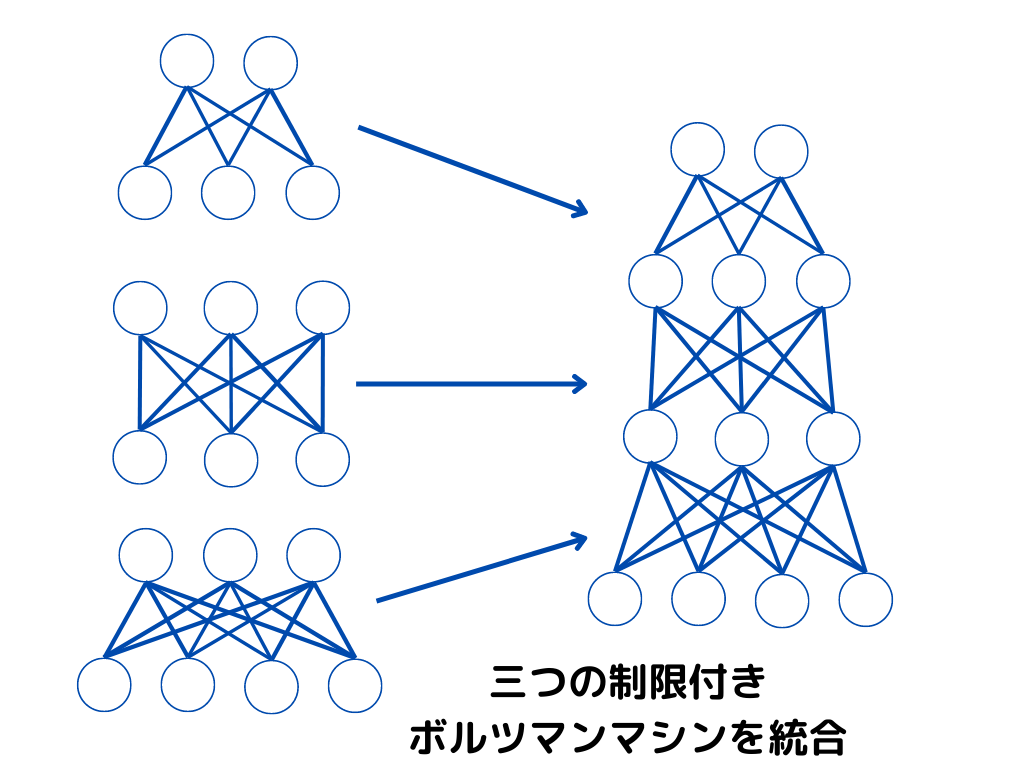
この深層ボルツマンマシンの最深層の部分以外を、ベイジアンネットワークにすると、一番最初に示した「深層信念ネットワーク」の構造になることがお分かり頂けるでしょうか?
まとめ
今回は大項目「ディープラーニングの概要」の中の一つディープラーニングのアプローチについての解説でした。
本記事をまとめると以下の3つ。
・オートエンコーダ
・積層オートエンコーダ
・転移学習
・ファインチューニング
・蒸留
・深層信念ネットワーク
・ボルツマンマシン
以上が大項目「ディープラーニングの概要」の中の一つディープラーニングのアプローチの内容でした。
ディープラーニングに関しても、細かく学習しようとするとキリがありませんし、専門的過ぎて難しくなってきます。
そこで、強化学習と同じように「そこそこ」で理解し、あとは「そういうのもあるのね」くらいで理解するのがいいでしょう。
そこで以下のようなことが重要になってくるのではないかと。
・ディープラーニングの特徴(それぞれの手法はどんな特徴があるのか)
・それぞれの手法のアルゴリズム(数式を覚えるのではなく、何が行われているか)
・何に使用されているのか(有名なもののみ)
ディープラーニングは様々な手法があるので、この三つだけでも非常に大変です。
しかし、学習を進めていると有名なものは、何度も出てくるので覚えられるようになります。
後は、新しい技術を知っているかどうかになりますが、シラバスに載っているものを押さえておけば問題ないかと。
次回は「ディープラーニングの概要」の「ディープラーニングを実装するには」「活性化関数」に触れていきたいと思います。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント