

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「ディープラーニングの概要」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの概要」の内容。
その中でも「ディープラーニングを実現するには」「活性化関数」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
今回はディープラーニングの概要ということもあって、ディープラーニングの基礎的な内容。
ここを理解していないと、ディープラーニングがどういうものかを理解できません。
ここから先の学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
今回はディープラーニングの主な枠組みや、基本的な用語を押さえていきたいと思います。
今までの記事で、見たことある単語も出てくるとは思いますが、復習の意味も兼ねて触れていきますね。
CPU
CPUとは、パソコンの脳みそ的な部分。
Central Processing Unitの略で、別名プロセッサーとも呼ばれます。
メモリ・HD・周辺機器から情報を受け、制御・演算を行う、パソコンの中心的な部分ですね。
パソコンは基本的に裏で、膨大な量の計算・演算を行っているので、CPUがないとそもそもパソコンとして機能しません。
この辺はパソコンの基本知識なので「知ってるよ」という方も多いかもしれませんね。
AI・ディープラーニングはパソコンがあって初めてできることなので、パソコンの内部構造の基本も押さえておきたいところでしょう。
TPU(Tensor Processing Unit)
TPUとは、googleの自社開発プロセッサのこと。
機械学習に向いているプロセッサというところが特徴になります。
ディープラーニング向けに最適化されているので、通常のGPUなどよりも高速に計算ができます。
GPU
GPUとは画像処理に特化した、パソコンの脳みそ的な部分のこと。
Graphics Processing Unitの略です。
リアルタイム画像処理に特化した演算装置、プロセッサーでCPUと役割は似ているかと。
GPUを使用すると、画面に映し出される映像が、きれいに(高画質に)なります。
ゲーム用のパソコンとかを見てみると、よくGPUが使われていますね。
GPGPU
GPGPUとは、GPUを汎用的プログラミングに用いるための技術のこと。
General-Purpose computing on GPUの略で、GPGPUです。
CPUには一つ一つの演算を行うのが早く(直列処理)、GPUには複数の演算を同時に行う(並列処理)のが早いという特徴があります。
この並列処理が早い、というのはディープラーニングを行う上で、早く計算結果を出すために重要なこと。
「元々並列処理が早いんだったら、機械学習に応用したら、もっと早く計算処理終わるでしょう」と考えられたのが、GPGPUですね。
ディープラーニングのデータ量
ディープラーニングのデータ量は得たい結果の精度にもよりますが、大量の情報が必要です。
実際に様々なサイトを見てみると、画像分類だけでも1クラス(1種類)の画像につき100~200枚のものから、5000枚以上のものまで様々あります。
1クラスにつき、なので50種類の画像ともなれば、1クラスにつき200枚でも1万枚の画像が必要になりますよね。
自分が分析したい結果や、計算に使えるリソース(CPU・GPU・現実的に集められる情報量)を考えることが大切になってきます。
あとは実際に精度などを出してみて、足りなければデータを足していくことも考えると良いでしょう。
活性化関数
活性化関数は、ディープラーニングのそれぞれのノードに用いられる関数のこと。
ノードに入力された値を、活性化関数に代入することで、結果を出力します。
例えば「入力値が0以上なら1、入力値が0未満なら0」を出力する活性化関数を見てみましょう。
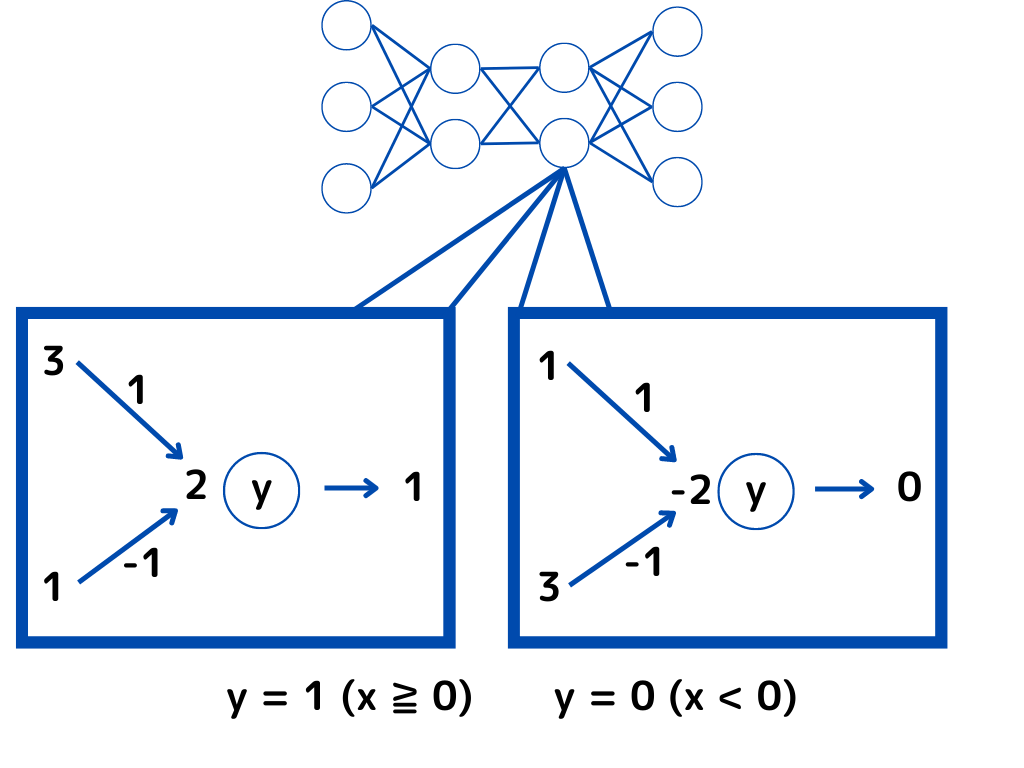
一番左の値から、右の出力の値までの計算過程はイメージできるでしょうか。
矢印の近くに書いてある数字が「重み」です。
まずは一番左の「入力値」と「重み」を掛け算して、足し合わせます。
(図の左の例を見ると「3×1+3×(-1) = 2」)
この計算結果「2」を活性化関数のxとして、入力します。
(今回の活性化関数(y)は一番の式で、条件から0以上であるため、1が出力)
活性化関数には、たくさんの種類があり、今回は以下のものを取り上げます。
・シグモイド関数
・tanh関数
・ソフトマックス関数
・ReLu関数
・Leaky ReLu関数
それぞれ見ていきましょう。

シグモイド関数
シグモイド関数とは以下の式で表される活性化関数のこと。

この式をグラフにしてみると以下のようになります。
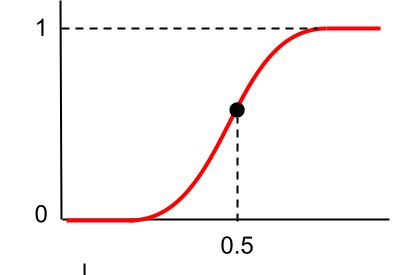
縦軸の範囲としては0~1であり、座標(0,0.5)で点対称なグラフですね。
よく二値の分類問題で使用されます。
しかし、微分すると0以下になってしまうことから、勾配消失問題が生じてしまうことが問題でした。
tanh関数
tanh(ハイパボリック タンジェント)関数とは、以下の式で表せる関数のこと。
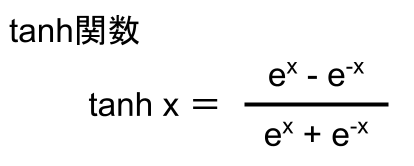
この式をグラフにしてみると以下のようになります。
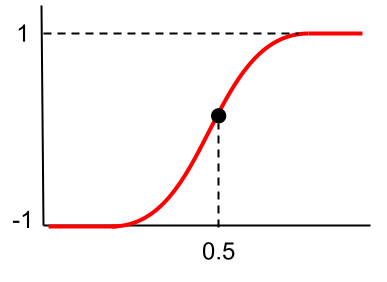
tanh関数はシグモイド関数と形が似ていますが、縦軸の範囲が違いますね。
-1~1までの範囲となっており、シグモイド関数より広範囲になっています。
なので、微分した際にも値が小さくなりにくく、シグモイド関数よりも勾配消失問題が起きにくいです。
ただし起きにくいだけであって、解消されるわけではないのでご注意を。
ソフトマックス関数
ソフトマックス関数とは、以下で表せる活性化関数の一つ。
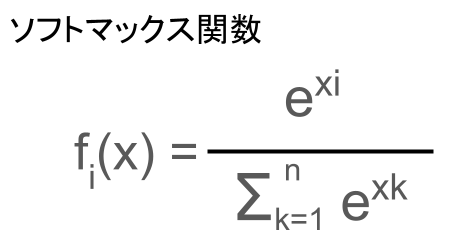
n個の入力データがあったときに、それぞれの出力(eのx乗)の合計が1になるように調整されています。
この式をグラフにしてみると以下のような感じに。
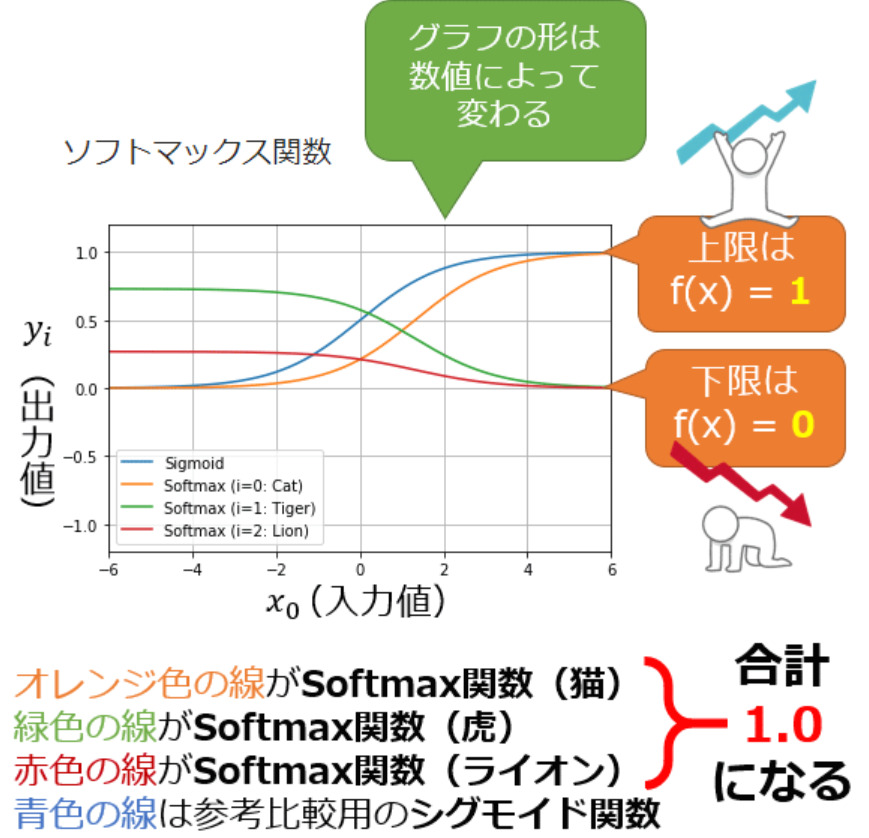
ソフトマックス関数は、多値の分類問題で使用されます。
特徴は入力によってグラフの形が変わり、すべてのグラフを足し合わせると1になること。
シグモイド関数に似たグラフが、たくさんあるようなイメージですね。
ReLu関数
ReLu関数とは、以下の式で表せる活性化関数のこと。

ちなみにx=0での微分はできません。
この式をグラフにしてみると以下のようになります。
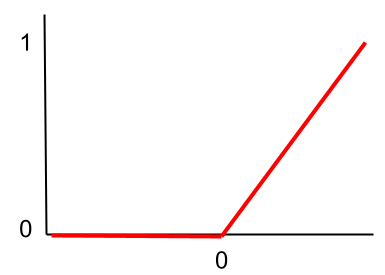
今まで見てきた関数とは、大分形が違いますね。
ReLu関数は、微分しても結果が1となります。
0以下にならないため、掛け算を繰り返しても1×1=1ですよね。
つまりこれまで紹介してきたシグモイド関数などと違って、勾配消失問題が起きない関数になります。
こんなに単純な関数で勾配消失問題が回避できたので、研究者たちにとっては衝撃だったようですね。
Leaky ReLu関数
Leaky ReLu関数とは、以下の式で表される活性化関数の一つ。
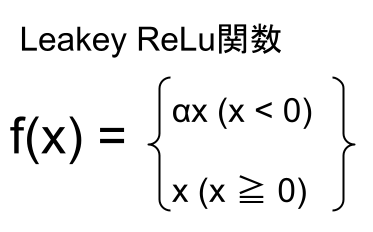
αはハイパーパラメータで、x=0での微分はできません。
この式をグラフにしてみると以下のようになります。
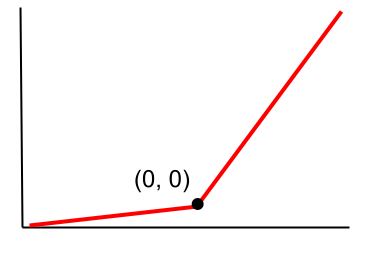
ReLu関数との違いは、x=0以下の部分ですよね。
x=0以下でも、若干の傾きがあることが分かります。
前述の通り、微分は関数の傾きなので、x=0以下でも値が発生することに。
つまりx=0以下の値が出現する場合でも、ディープラーニングを行えるよう関数となっています。
まとめ
今回は大項目「ディープラーニングの概要」の中の一つ「ディープラーニングを実現するには」と「活性化関数」についての解説でした。
本記事をまとめると以下の3つ。
・CPU
・TPU
・GPU
・GPGPU
・シグモイド関数
・tanh関数
・ソフトマックス関数
・ReLu関数
・Leaky ReLu関数
以上が大項目「ディープラーニングの概要」の中の一つ「ディープラーニングを実現するには」と「活性化関数」の内容でした。
ディープラーニングに関しても、細かく学習しようとするとキリがありませんし、専門的過ぎて難しくなってきます。
そこで、強化学習と同じように「そこそこ」で理解し、あとは「そういうのもあるのね」くらいで理解するのがいいでしょう。
そこで以下のようなことが重要になってくるのではないかと。
・ディープラーニングの特徴(それぞれの手法はどんな特徴があるのか)
・それぞれの手法のアルゴリズム(数式を覚えるのではなく、何が行われているか)
・何に使用されているのか(有名なもののみ)
ディープラーニングは様々な手法があるので、この三つだけでも非常に大変です。
しかし、学習を進めていると有名なものは、何度も出てくるので覚えられるようになります。
後は、新しい技術を知っているかどうかになりますが、シラバスに載っているものを押さえておけば問題ないかと。
次回は「ディープラーニングの概要」の「学習の最適化」に触れていきたいと思います。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント