

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
試験日は2022年7月2日。(記事の更新は間に合いませんでした)
残り一か月強で、知識0から合格できるかはわかりませんが、頑張りたいと思います。
皆さんも一緒に頑張りましょう!
※この記事は合格を保証するものではありません


大項目「ディープラーニングの社会実装に向けて」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの社会実装に向けて」の内容。
その中でも「AIと社会」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
AIの扱い方というのは、社会全体で「どう扱おうか?」と悩んでいる最中です。
いろんな法律・ルールがあったりしますし、新しいルールが出現したりすることも。
このルールを侵害してしまうと、罰則や信頼低下に繋がってしまいます。
さらにG検定合格にも、この章が肝になってくるようですね。
機械学習やディープラーニングはバッチリなのに法律関連が全然できなくて落ちた、という話も聞きます。
油断せずに行きましょう。
※今回取り上げた法律が変わることもあるということに注意してくださいね。
基本的なところは今回の記事で押さえて、最新版のシラバスを参考に調べることが大切!
今回はAI業務に関する契約・連携や、データの性質を押さえていきたいと思います。
個別の契約
G検定における個別の契約とは、AIプロジェクトの際に外部委託する場合の契約の仕方のこと。
一般的なプロジェクトも同様ですが、進め方には「自社のみで進める」「外部の力も利用する」の二つがあります。
●自社のみで進める場合
メリット
・ノウハウが自社に蓄積できる
・外部に委託する場合よりも情報漏洩のリスクは小さい
デメリット
・プロジェクトに必要なリソース(人材、機材、データ等)を揃えなければいけない
・揃っていない場合、すぐにプロジェクトを開始できない
ではプロジェクトに必要なリソースが揃っていない場合、どうすればいいのでしょうか。
そこで「外部の力も利用する」必要が出てきます。
この場合を「外部委託」「業務委託」と言ったりします。
外部委託の種類は以下の通り。
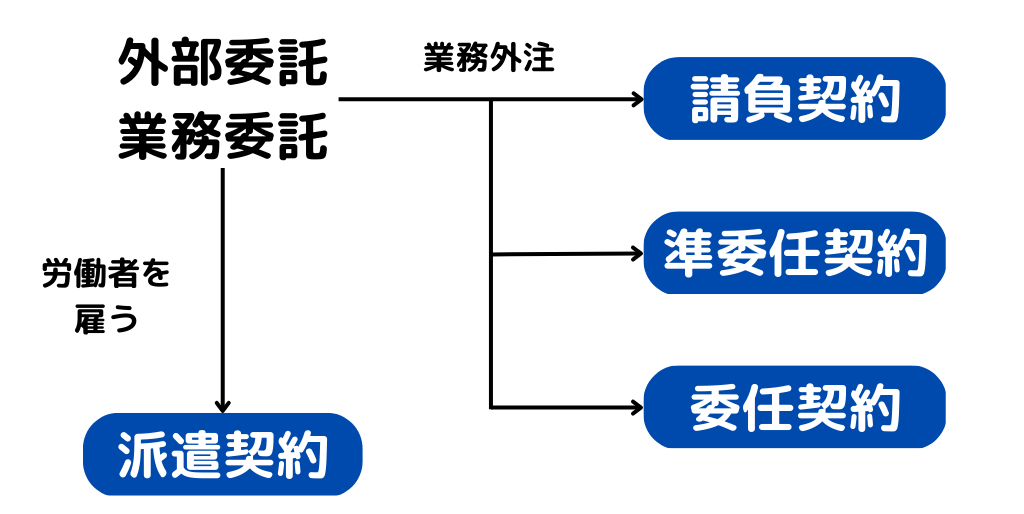
この中で、特にAIプロジェクトで重要なのは「請負契約」と「準委任契約」。
簡単にまとめると以下のような感じ。
・請負契約
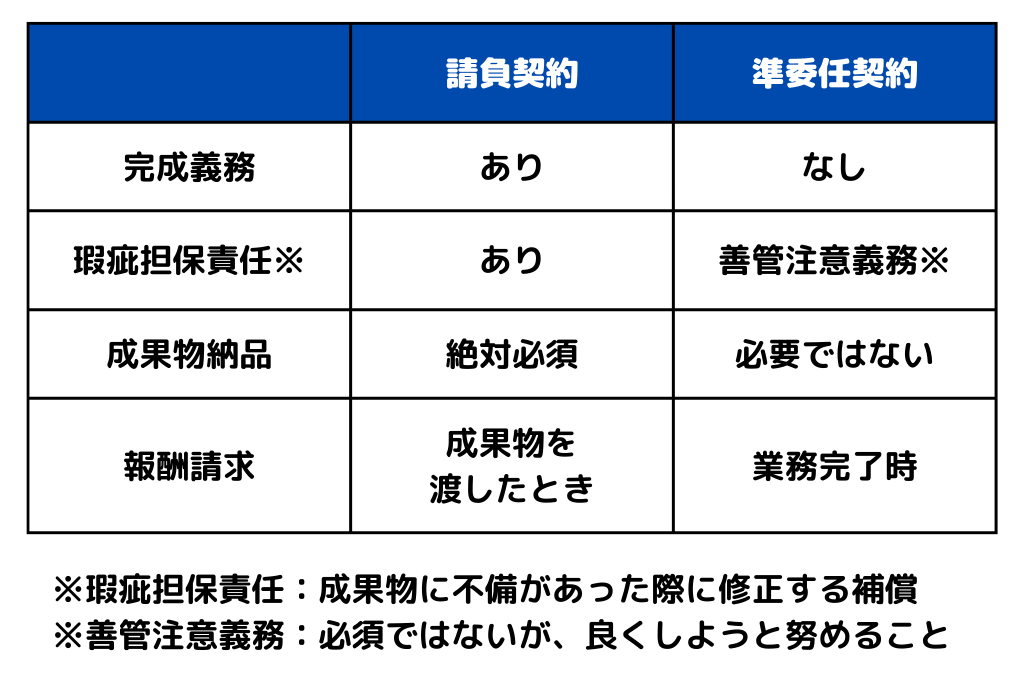
成果物の納品を保証する契約の種類。成果物の納品が必須。
・準委任契約
成果物は保証せず、技術提供(業務を行うこと)のみの契約。指揮権は依頼側にある。
違いを表にまとめると以下のようになります。
データの網羅性(完全性)
データの網羅性(完全性)とは、全てのデータを漏れなく提示されていること。
データ収集の際に、重要な事項ですね。
データ分析などを行う際には、大量のデータが必要になります。
収集データの品質は、データ分析プロジェクトの成功が左右されるといってもいいくらい重要。
そこで政府CIOポータルでは、データの品質評価を15項目にわたって定義しているようです。
その中でも一部を抜粋すると以下の通り。
・網羅性(完全性)
利用、分析するために必要なデータ項目は潜在的なものも含めて100%網羅しているか
・最新性
データに対しての更新サイクルが適切か、更新日が明示されているか
・機密性
アクセス限定、暗号化、ハッキング対策など行っているか
・理解性
利用者がデータの内容を理解しやすいか
・正確性
誤字脱字、書式などデータに誤りがないか
・一貫性
データセット内やデータセット間にデータの矛盾がないか
参考: データ品質管理ガイドブック https://cio.go.jp/guides
他合わせて15項目があり、データ品質についての定義がなされています。

転移学習
転移学習とは、学習済みモデルを使用して、最終出力層の入れ替えを行い他の学習に転用すること。
以前の記事でも説明したことがありますね。

既に学習したモデルを使っているので、学習が早く進みます。
最終出力層を入れ替えるのみで、重みの更新は行いません。
さらに、よく似た手法として「ファインチューニング」「蒸留」もありました。
この機会に、以下のリンクから復習しておきましょう。
サンプリング・バイアス
サンプリング・バイアスとは、標本抽出時にデータに誤った偏りが出てしまうこと。
一般的にデータ分析の際、調べたい対象すべてのデータを取ってくるのは大体不可能です。
「日本人男性の平均身長」を調べたい時に、全日本人男性の身長データ(母集団)を取得することはできないですよね。
そこで、標本抽出(サンプリング)という操作を行います。
日本人男性の中から何人かの身長データを取ってきて、そのデータから平均身長を考えるんです。
この際に、サンプリングの仕方には注意が必要。
例えば日本人男性といっても、60代以降のデータが多かったら低めに出てしまう可能性があるでしょう。
地域によって違いが出てしまうこともあるかもしれません。
このように、なるべく偏り(バイアス)がないようにデータを取得することが重要です。
他企業や他業種との連携
他企業や他業種との連携は、人工知能を利用したプロジェクトを進めるうえで重要になるもの。
AIは様々な業界・企業に渡って利活用が期待されているものです。
1社のみでAI利活用を進めることも重要ですが、他企業・他業種との連携を強めれば、より大きな価値を生み出せるでしょう。
そこで複数社、時には他業種の企業も交えてプロジェクトを進める場合があります。
このように、AIやデータの利活用を進め、社会に大きな価値を提供することが重要なのです。
官公庁では「官民データ活用推進基本法」というものも定められています。
国・地方自治体はオープンデータに取り組む義務がある、という法律ですね。
1社のみで完結させるのではなく、連携を図っていくことが重要です。
産学連携
産学連携とは、大学などの教育・研究機関と民間企業が連携して、新技術や新事業を創造すること。
新技術や新事業創造において、もはや企業のみでは難しいということもあります。
その場合に重要なのが「産学連携」。
民間企業には「豊富な資金力・社会実装力」、
大学には「高度な専門知識や技術・豊富な研究開発設備」がありますよね。
これらのリソースをうまく活用することで、新技術や新事業の創出が可能になります。
産学連携に便利なサービスとしては以下のようなものがあるかと。
・Coursera
スタンフォード関係者設立の教育技術団体。
AIを含めた様々な分野の講義をオンライン提供している
・aiXiv
数学・統計学などの論文が保存・公開されているwebサイト。
コーネル大学提供。ディープラーニングの最新技術を追うのに便利。
上記のサービスを利用することで、産学連携が推進されます。
主に大学の技術知識・論文などを、無料で提供してくれているようですね。
またAI関連の産学連携プロジェクトは、以下の通り。
・ライフ インテリジェンス コンソーシアム(LINC)
「創薬AI」の開発プロジェクト。製薬メーカー、ヘルスケアやIT企業、研究組織が参加
・早稲田・DMM AIラボ
早稲田大学理工学術院と、DMMの共同研究室。
・大阪大学とダイキン工業
AI人材の育成・AI共同研究などをで連携する契約を締結。
オープンイノベーション
オープンイノベーションとは、自社以外の技術や知識も積極的に取り入れることでイノベーションを起こすこと。
日本企業は「自前主義」の考え方が強いといわれています。
・自前主義
自社の研究所で研究を行い、製品開発・製造を行うことで、自社のみで完結させること。
しかし現時点でAI人材の不足などによる影響で、自社のみでプロジェクトを完結させることは難しくなっています。
そこで自社以外のリソースも有効活用することが重要。
他の組織や機関などが持つ知識や技術を取り込んで、自前主義からの脱却を図ることが日本の競争力を高めるためにも重要なのではないでしょうか。
AI・データの利用に関する契約ガイドライン
AI・データの利用に関する契約ガイドラインとは、データの利活用やAIに関する契約について経済産業省が発行したもの。
2018年6月に策定されました。
主に以下の二つが整理されています。
・データの利用等に関する契約
・AI技術を利用するソフトウェアの開発・利用に関する契約の主な課題や論点、契約条項例、条項作成時の考慮要素等
引用:https://www.meti.go.jp/press/2019/12/20191209001/20191209001.html
本ガイドラインの中でも、G検定の問題集等で見かけた言葉が「秘密保持義務」。
少しだけ解説しましょう。
秘密保持義務
秘密保持義務とは、社員が職務中・企業において知った秘密を他社に漏洩してはならない義務。
守秘義務とも呼ばれます。
営業秘密等の情報を扱う従業員などには、契約段階で秘密保持義務を課すのが重要です。
例えばデータに関しては、アクセス制限をした上で、アクセスできる人には秘密保持の誓約書を出させるなどが有効なようですね。
まとめ
今回は大項目「ディープラーニングの社会実装に向けて」の中の一つ「データの収集」についての解説第二弾でした。
本記事をまとめると以下の通り。
・個別の契約
・データの網羅性(完全性)
・転移学習
・サンプリング・バイアス
・他企業や他業種との連携
・産学連携
・オープンイノベーション
・AI・データの利用に関する契約ガイドライン
以上が大項目「ディープラーニングの社会実装に向けて」の中の一つ「データの収集」の内容でした。
G検定では「機械学習」「ディープラーニング」で覚える内容が多いので、どうしてもそちらに注力しがちです。
しかし、G検定合格において落とし穴になるのが本章「ディープラーニングの社会実装に向けて」。
出題率としても高めに設定されていると思うので、全問不正解だと合格は厳しいです。
最低限の重要キーワードだけでも覚えておくことが重要でしょう。
次回は「ディープラーニングの社会実装に向けて」の「データの加工・分析・学習」に触れていきたいと思います。
G検定の勉強完了までもう少し!
頑張りましょう!
ではまた~
続きは以下のページからどうぞ!




コメント