

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「人工知能を巡る動向」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「人工知能を巡る動向」の内容。
その中でも「第三次AIブーム」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
本記事の範囲は問題数としては少ないものの、合格に向けては必須の基礎知識になります。
ここを理解していないと、機械学習やディープラーニングがどういうものかを理解できません。
ここから先の学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
第三次AIブームに関する内容が多くなってしまってので、記事を二つに分割してお届けしようと思いますね。
第三次AIブームとは?
第三次AIブームとは現在において、AIが急速に注目されていることを言います。
きっかけは2012年の画像認識大会。
トロント大学のチームが開発した「AlexNet」という機械が、他を圧倒して優勝したことが衝撃的だったようです。
この「AlexNet」に使われていたのがディープラーニング。
今までもディープラーニングの考えはあったのですが、PCの性能上できていなかったようですね。
しかしPCの精度も今までとは比べものにならないくらいの精度を持ち始めました。
これによりディープラーニングが実現。
現在のAIブームのきっかけを作ったと言われています。
では、そんな第三次AIブームの中でどんなキーワードがあったのでしょうか。
レコメンデーションエンジン
レコメンデーションエンジンとは、その名の通り商品を勧めるシステムのこと。
購入者が購入・閲覧した商品と関連があり、購買意欲をかき立てるような商品を勧めてくれます。
Amazonの「こんな商品を買った人はこんな商品も買っています」が良い例でしょう。
スパムフィルター
スパムフィルターとは、迷惑メール対策のこと。
迷惑メールを自動検出し、自動で削除したり他のファイルに保存したりしてくれます。
Gmailや、DOCOMO・auなどのキャリアメールにも「迷惑メール」というフォルダを見たことはないでしょうか。
「迷惑メール」フォルダにメールを入れる仕組みが、スパムフィルターです。
対訳(コーパス)ベース方式
対訳(コーパス)ベース方式とは、原文とその翻訳を元にして、機械に自然言語処理させる方式のこと。
原文と訳文を辞書のように集めたデータ(コーパス)を元にしています。
従来は本来の辞書のように、単語とその意味のみのデータでした。
この方式のすごいところは、単語だけではなく、文章全体の意味も含めてデータベースにしたところ。
さらに対訳(コーパス)ベース方式は次に二つに分かれます。
・統計的自然言語処理
・ニューラル機械翻訳
それぞれ見ていきましょう。
統計的自然言語処理
統計的自然言語処理とは、人間が日常的に行っている自然言語をコンピュータに処理させること。
ここに使用されている技術(アルゴリズム)は、基本的に上記と変わりません。
文章ベースで訳文をデータベース化し、そのデータを元に機械翻訳をしていくイメージです。
ニューラル機械翻訳
ニューラル機械翻訳とは、統計的自然言語処理の手法にニューラルネットワークを加えた手法のこと。
現在最も使われている機械翻訳のアルゴリズムが、これのようですね。
ニューラルネットワークを用いることで深層学習ができ、未知の文章も「似たような意味の訳」をデータベースから探して、当てはめられるようです。
これにより、最近の機械翻訳は精度が向上したそう。

人間の神経回路
人間の神経回路の主な特徴は以下の通り。
1.結合の強さによって、次のニューロンに伝わる電気量は変わる
2.受け取った電気が閾値を超えると発火する(次のニューロンに伝わる)
人間の脳はニューロンという神経細胞がたくさんあります。
この神経細胞同士の結合の強さによって、伝えられる電気量が変わります。

さらに、ニューロンは全ての電気信号を別のニューロンに伝えるわけではありません。
次のニューロンに伝えるには、ある程度の量(閾値)が必要なのです。
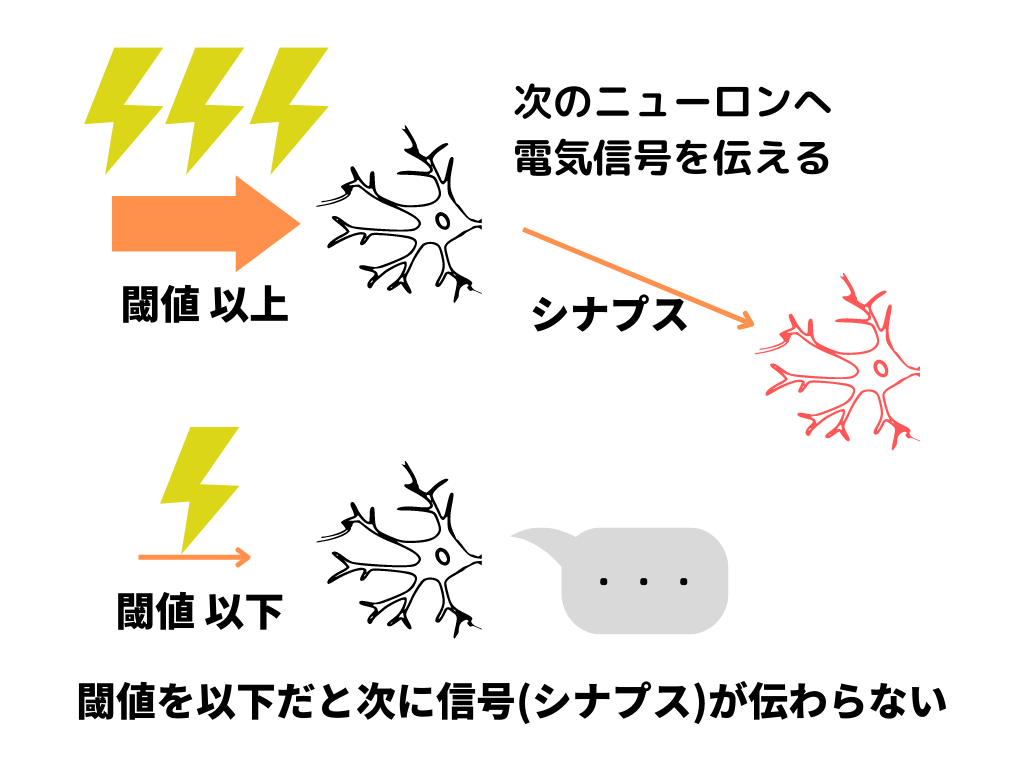
このようにニューロンが日々大量の情報(電気)をやりとりすることで、脳は「考える・判断する」ことができているようです。
最近よく聞く「ニューラルネットワーク」とは、この人間の神経回路を模した、プログラムのことを言っていることが多いですね。
単純パーセプトロン
単純パーセプトロンとは、ニューラルネットワークの一種。
入力層と出力層の二層のみから構成されています。

人の神経回路の入力信号に対応するのが「入力1,2,3」
ニューロンに対応するのが「活性化関数」
出力に対応するのが「シナプス」です。
そして入力から送る信号に、「重み」や「バイアス」をつけて活性化関数に送ります。
この構造が、今後たくさん出てくる「ニューラルネットワーク」「ディープラーニング」の全ての基礎です。
誤差逆伝播法
誤差逆伝播法とは、出力と正解データとの誤差を埋めるための手法のこと。
以下の図はディープラーニングの模式図ですが、これからもまた出てくるので、ここで覚えられなくても大丈夫です。
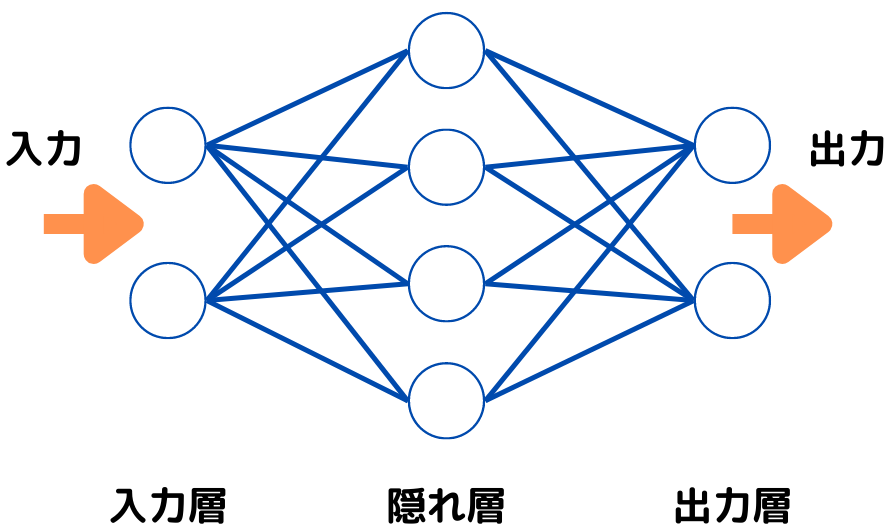
ディープラーニングでは単純パーセプトロンと同様、「重み」や「バイアス」などのパラメータがあります。
単純パーセプトロンの矢印を増やして、「隠れ層」が増えたイメージですね。
このパラメータを出力層に近い層から順に連鎖的に勾配を求めることを、誤差逆伝播法と言います。

①、②と求めていくと、「出力」から「入力」と逆に伝播しているように見えますよね。
これが「誤差逆伝播法」と言われる所以のようです。
まとめ
今回は大項目「人工知能を巡る動向」の中の一つ第三次AIブームについての解説でした。
本記事をまとめると以下の3つ。
・「レコメンデーションエンジン」「スパムフィルター」など身近にAIが用いられている
・ニューラルネットワークは人間の神経回路の構造を模している
・「単純パーセプトロン」「誤差逆伝播法」はニューラルネットワーク、ディープラーニングの基礎
以上が大項目「人工知能を巡る動向」の中の一つ第三次AIブームの内容でした。
いよいよ、現在のAIブームの内容に入ってきましたね。
ここで出てくる具体例は結構、想像が付きやすいものも多いかと思います。
その分、細かい理論までを言い出すとキリが無くなってしまいます。
初心者でも分かるように、そしてG検定合格ラインの知識を得られるような記事を作るように頑張りますね。
次の記事では第三次AIブームについての解説、第二弾。
お楽しみに!
ではまた~
続きは以下のページからどうぞ!




コメント