

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「ディープラーニングの概要」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの概要」の内容。
その中でも「学習の最適化」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
今回はディープラーニングの概要ということもあって、ディープラーニングの基礎的な内容。
ここを理解していないと、ディープラーニングがどういうものかを理解できません。
ここから先の学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
今回は学習の最適化に関する用語をまとめた第二弾。
主にディープラーニングのパラメータの更新の仕方について述べています。
局所最適解・大域最適解
局所最適解とは、勾配が一時的に0になるが、最小値にはならない点。
勾配とは曲線の傾きでした。
前回の記事で「勾配が最小になる点が、最小値」という説明をしましたが、そうでないこともあります。
それが「局所最適解」を持つ場合。
どんなグラフかというと、以下の図のようなイメージです。
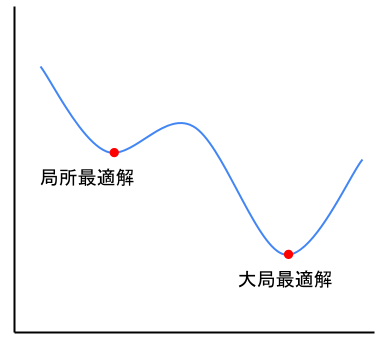
このようなグラフだと、勾配が0になっている点が2つありますね。
上図にもありますが、
大域最適解とは勾配が0であり、かつ最小値を取る値のこと。
上図のような関数の場合、大域最適解を求めることが、勾配降下法の目的になりますね。
このように関数が複雑になっていくほど、局所最適解が出てきてしまう可能性があります。
そこで、局所最適解に陥らないような学習率などのハイパーパラメータの調整が重要です。
鞍点
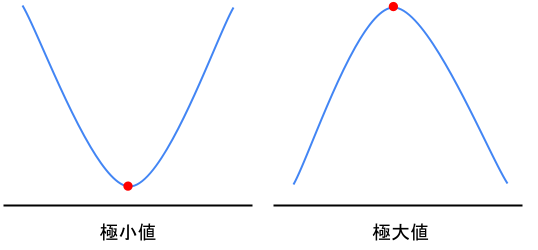
鞍点とはある次元から見れば極大値、別の次元から見ると極小値に見える点のこと。
極大値・極小値とは、先ほどまで出てきていた「勾配が0になる点」のことです。
勾配が0になるといっても、以下の図のような二種類がありますよね。
「局所最適解・大域最適解」のところで出したグラフをもう一度出しますね。
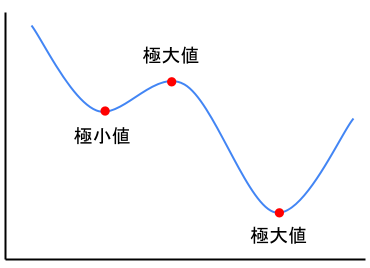
このように極小値と極大値が存在しています。
また極大値も勾配が0になるので、勾配降下法で極大値に陥ることもあるのは注意してください。
曲線状にボールを置いたイメージだと分かりづらいかもしれませんが、頭に入れておきましょう。
鞍点は、ある次元から見れば極大値だが別の次元から見ると極小値に見える点のことでした。
ここの陥ると抜け出すのが難しく、学習が進みにくくなってしまいます。
図にすると以下の様なグラフ。


プラトー
プラトーとは、鞍点などの停留点に達して、学習が進まなくなっている状態のこと。
この状態になってしまうと、いつまでもパラメータの学習が終わらなくなってしまいます。
鞍点や、局所最適解がある関数には起こってしまう可能性がありますね。
ハイパーパラメータ
ハイパーパラメータとは、分析者が自ら決める学習モデルのパラメータのこと。
前回の記事でも触れた学習率などが挙げられます。
学習が早く終わるパラメータを定められるかどうかは、分析者の腕次第、ということになりますね。
とはいえ何も方法がないのでは、汎用性という観点でも微妙です。
そこで以下の様なハイパーパラメータを決める手法が存在します。
・グリッドサーチ
・ランダムサーチ
この手法を使えば、ある程度の精度を出せる可能性が増えます。
グリッドサーチ
グリッドサーチとはパラメータ最適化手法の一つで、ハイパーパラメータをいくつか指定することで最適化を図る方法。
具体的な手順としては以下の通り。
1.それぞれのハイパーパラメータをいくつか(1つのパラメータに付き3つ程度)指定する
2.指定したパラメータの全ての組み合わせを選ぶ
3.選んだ組み合わせ毎にクロスバリデーションを試す
4.最高精度のパラメータを使用する
実際にpythonで使用するときは、1のパラメータを指定するプログラムを書けば後は自動で計算してくれます。
組み合わせの数が多いほど精度の良いパラメータを見つけることができますよね。
しかし組み合わせが多くなりすぎると、計算に時間がかかってしまうため、注意が必要です。
ランダムサーチ
ランダムサーチとはパラメータ最適化手法の一つで、ハイパーパラメータの範囲を指定することで最適化を図る手法のこと。
具体的には以下の通り。
1.それぞれのハイパーパラメータの範囲を指定する
2.指定した範囲内でランダムな組み合わせを選ぶ。
3.ランダムに選んだ組み合わせで、クロスバリデーションを試す。
4.最高精度のものを使用する
グリッドサーチは具体的なパラメータ値を指定したのに対し、ランダムサーチでは範囲を指定します。
範囲から機械がランダムにパラメータを抽出し、最高精度のものを使用するという流れですね。
次の章からは、ハイパーパラメータを学習する際に使用するデータの使い方を解説していきます。
バッチ学習
バッチ学習とは、全ての訓練データを用いてパラメータを更新する方法。
一番単純かつ、手元にあるデータから最も良い精度のモデルを作成できるデータの使い方です。
しかし全てのデータを使うとになると、計算量が膨大になりすぎてしまいます。
最近ブームの画像処理や音声認識などは、その典型ですね。
そこで現実的な計算時間になるように考えられたデータの使い方がミニバッチ学習・オンライン学習です。
ミニバッチ学習
ミニバッチ学習とは、訓練データの一部を使用してパラメータを更新する方法。
どのように一部を利用するかというと、訓練データを小分けにします。
そして小分けにされた一定数サンプルをランダムに抽出して、パラメータを更新。
こうすることで、全訓練データを使わないので計算量も少なく済みます。
ランダムに抽出しているので、訓練データが偏っているという想定もしなくていい、というのがミニバッチ学習。
オンライン学習
オンライン学習は、訓練データをランダムに一件ずつ投入しパラメータを更新する方法。
全データを一気に使うのではなく、一件ずつもしくは小分けしたグループ毎に使用していきます。
まずは、小分けにされたデータを使用して一回目の学習。
学習が終了したら、別の小分けになったデータを使用して二回目の学習を行います。
これを繰り返すことでパラメータを更新し、モデルの精度を挙げていく方法です。
データリーケージ
データリーケージとは、学習時点で本来知らないはずのデータを不当に使ってしまうこと。
時系列データなどを使用する際に、注意したい現象の一つになります。
例えば、前年までの勝率を元にして今年の勝率を予測していたデータがあったとしますね。
すると、データは必ず前年までの勝率が影響しているはずです。
モデルを作成する際に、2012年の勝率を予測するために、2015年のデータを使ってたらデータの前提が変わってしまいます。
そのため、時系列データは「予測に使用したデータは、その時点で使用して大丈夫なものか」という視点が重要ですね。
まとめ
今回は大項目「ディープラーニングの概要」の中の一つ「学習の最適化」についての解説、第二弾でした。
本記事の重要キーワードは以下の通り。
・局所最適解
・大域最適解
・鞍点
・プラトー
・ハイパーパラメータ
・グリッドサーチ
・ランダムサーチ
・バッチ学習
・ミニバッチ学習
・オンライン学習
・データリーケージ
以上が大項目「ディープラーニングの概要」の中の一つ「学習の最適化」の内容でした。
ディープラーニングに関しても、細かく学習しようとするとキリがありませんし、専門的過ぎて難しくなってきます。
そこで、強化学習と同じように「そこそこ」で理解し、あとは「そういうのもあるのね」くらいで理解するのがいいでしょう。
そこで以下のようなことが重要になってくるのではないかと。
・ディープラーニングの特徴(それぞれの手法はどんな特徴があるのか)
・それぞれの手法のアルゴリズム(数式を覚えるのではなく、何が行われているか)
・何に使用されているのか(有名なもののみ)
ディープラーニングは様々な手法があるので、この三つだけでも非常に大変です。
しかし、学習を進めていると有名なものは、何度も出てくるので覚えられるようになります。
後は、新しい技術を知っているかどうかになりますが、シラバスに載っているものを押さえておけば問題ないかと。
次回は「ディープラーニングの概要」の「最適化とそのほかのテクニック」です。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント