

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「人工知能を巡る動向」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「人工知能を巡る動向」の内容。
その中でも「第三次AIブーム」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
本記事の範囲は問題数としては少ないものの、合格に向けては必須の基礎知識になります。
ここを理解していないと、機械学習やディープラーニングがどういうものかを理解できません。
ここから先の学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
第三次AIブームに関する内容が多くなってしまってので、記事を二つに分割してお届けしようと思いますね。
第三次AIブームとは?
第三次AIブームとは現在において、AIが急速に注目されていることを言います。
きっかけは2012年の画像認識大会。
トロント大学のチームが開発した「AlexNet」という機械が、他を圧倒して優勝したことが衝撃的だったようです。
この「AlexNet」に使われていたのがディープラーニング。
今までもディープラーニングの考えはあったのですが、PCの性能上できていなかったようですね。
しかしPCの精度も今までとは比べものにならないくらいの精度を持ち始めました。
これによりディープラーニングが実現。
現在のAIブームのきっかけを作ったと言われています。
では、そんな第三次AIブームの中でどんなキーワードがあったのでしょうか。
ILSVRC
ILSVRCとは第三次AIブームのきっかけとなった、画像認識を争う大会のこと。
ImageNet Large Scale Visual Recognition Challengeの略ですね。
上記にも述べましたが、2012年にトロント大学のチームが圧倒的な差で優勝したようです。
2012年以降もILSVRCは開催され、この出来事をきっかけに、画像認識は飛躍的に技術が向上。
今の画像認識技術があるのは、この大会での衝撃からのようですね。
ILSVRCではなく一番最初の単語だけを取って「ImageNet」という人も多いようです。
特徴量
特徴量とはデータの特徴を表す量のこと。
機械にインプットさせるデータでもあります。
エクセルの表データでイメージすると分かりやすいかもしれません。

例えば上の表で「売上」というデータの特徴を表したいとします。
すると、列名にも入っている「場所」「来店者数」「商品数」が「売上」に影響してそうではないでしょうか。
「ID」は微妙ですよね。
別の言い方をすると
「売上」というデータの特徴を「場所」「来店者数」「商品数」が表してそうです。
この「場所」「来店者数」「商品数」を特徴量と言います。

オートエンコーダ
オートエンコーダとはニューラルネットワークを用いた次元削減のこと。
「次元」というのは、特徴量(データの特徴を表す量)の数、とも言えます。
今は情報が大量すぎて、この「次元」の数が多いと、いくら性能の高いPCでも計算に時間がかかってしまいますよね。
そこで「元のデータの特徴を損なわないように、次元を減らそう」という考えの元、使われる技術です。
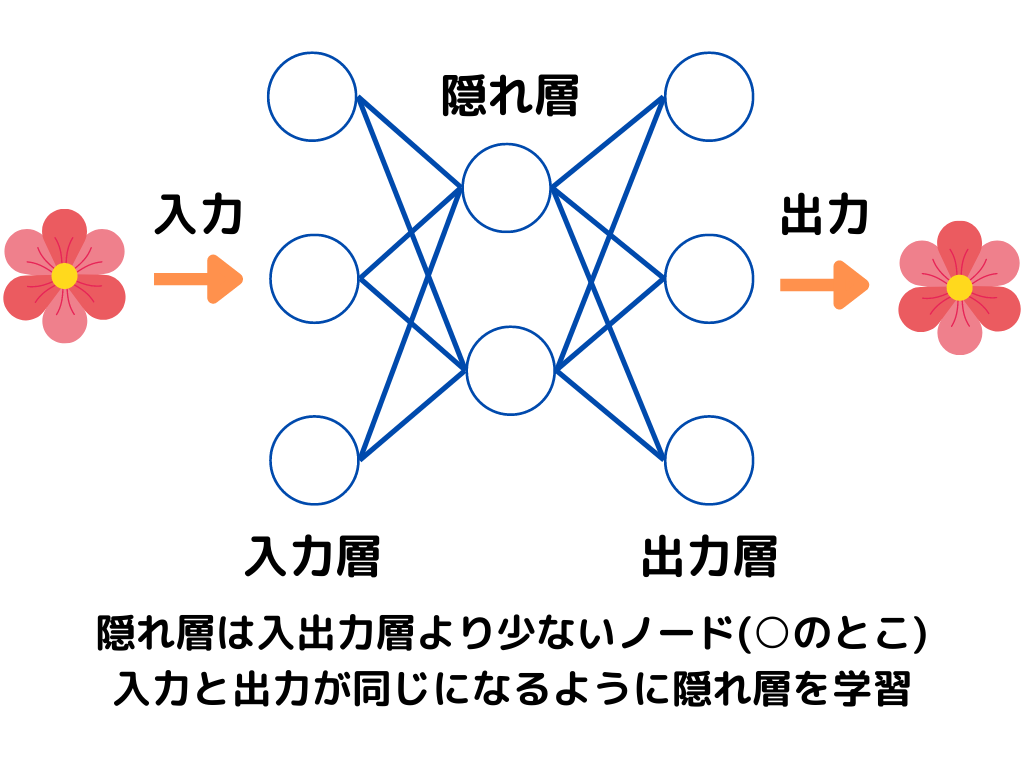
オートエンコーダは入力層、隠れ層、出力層の3層で構成され、入出力の形が同じになるようになっています。
そして隠れ層は一つしか持たず、入力層に対して「次元数が少なくなるように」調整。
詳しくは後の記事「ディープラーニングのアプローチ」で触れますね。
次元の呪い
次元の呪いとは以下の二つのことを言います。
・次元を増やすと必要なデータ数が指数的に増えていく
・データの空間が膨張する(データの端同士の距離が遠くなる)
イメージは以下の図のような感じ。

このように全データを埋めようとすると、必要なデータ数は3→9→27と、一気に増えていきます。
これが指数的に増えていく、と言うことですね。
さらに、データの端同士も3→√18 (4.24…)→√27 (5,196…)とだんだん遠くなっています。
これが「データの空間が膨張する」ということですね。
機械学習の定義
最近は色んな所で「機械学習」という言葉を耳にするようになりました。
この「学習」とは何なのでしょうか。
機械学習の定義は入力をパターン分類すること。
具体的には以下のようなできることがあります。
・パターン認識
・特徴量抽出
・画像認識
・一般物体認識
・OCR
一つずつ見ていきましょう。
パターン認識
パターン認識とは入力されたデータに、どのような傾向(パターン)があるかが分かること。
少ないデータなら人間でも「これとこれは関係がありそうだな」「これらはまとめられそう」などとパターンが分かります。
大量のデータになってくると人間が調べるのは無理なので、機械が似たデータをまとめたり、分類してくれたりしてくれるんです。
機械学習でできることのうちの一つですね。
特徴抽出
特徴量抽出とは元データの特徴量の中から、分析に重要だと思われる特徴量を少数選んで学習すること。
元データの特徴量を全て学習しても良いのですが、それだとビッグデータは計算に時間がかかりすぎてしまいますよね。
そこで、必要最低限な特徴量に絞ることで、よりたくさんのデータを短い時間で計算できるようになります。
画像認識
画像認識とはその名の通り、機械が画像を認識できること。
聞いたことがある人も多いと思います。
その画像はどういう画像に分類できるのか、といったことを機械が判断できるようになります。
例えば機械に入力された画像は猫の写真なのか犬の写真なのか判断する、といったような感じですね。
一般物体認識
これは、画像認識と被ってくるところもあります。
一般物体認識とは、画像に写っているもの(一般物体)を機械が認識できること。
画像認識と違う部分は、画像の分類ではないというところでしょうか。(主観です)
画像のどこに何が写っているか、を判断できるのが一般物体認識ですね。
OCR
OCRは、光学的文字認識(Optical Character Recognition/Reader)の略です。
OCRとは機械が、文字を読めるようになる技術のこと。
読み取った文字を、コンピュータが利用できるデジタルの文字コードに変換する技術です。
まとめ
今回は大項目「人工知能を巡る動向」の中の一つ第三次AIブームについての解説、第二弾でした。
本記事の重要キーワードは以下の通り。
・ILSVRC
・特徴量
・オートエンコーダ
・次元の呪い
・パターン認識
・特徴量抽出
・画像認識
・一般物体認識
・OCR
以上が大項目「人工知能を巡る動向」の中の一つ第三次AIブームの内容でした。
今までAIブームは何度もあった、ということを見てきましたよね。
でも途中で途切れている時期があるということは、それぞれのブーム時に問題点があったから。
なので、次の記事では「人工知能分野の問題」という大項目に入っていきます。
お楽しみに!
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント