

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「ディープラーニングの手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの手法」の内容。
その中でも「画像認識分野」に焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
ここを理解していないと、G検定に合格も難しいでしょう。
難しく内容も多い部分ですが、しっかり覚えていきたいですね。
今回は画像認識分野の中でも「物体識別」について押さえていきたいと思います。
画像認識タスク
画像認識タスクには、以下の3つに大別されます。
・物体識別タスク
・物体検出タスク
・セグメンテーションタスク
「画像認識って全部同じじゃないの?」と思った方は、注意して覚えるようにしましょう。
それぞれのタスクで、非常にたくさんの手法が開発されています。
そこで本記事では、それぞれのタスク毎に手法を分けて解説していきますね。
本日はセグメンテーションタスクについて触れていきましょう。
セグメンテーションタスク
セグメンテーションタスクとは位置をピクセル単位で検出し、ラベルを検出するタスクのこと。
画像に写っている全ての物体に対して行います。
コンピュータ画像も細かく見ていくと、一つ一つ四角に区切られていて、そこに色の情報が入ってるんですね。
この最小構成単位(一個の四角)を、ピクセル(画素)といいます。
ピクセル単位で位置を検出するので、物体検出タスクよりも物体の輪郭を捉えやすくなるようです。
イメージとしては以下の様な感じ。(セグメンテーションタスクの一種類です)

セグメンテーションタスクは、以下の三種類に分けることができます。
・セマンティックセグメンテーション
・インスタンスセグメンテーション
・パノプティックセグメンテーション
今回は「インスタンスセグメンテーション」「パノプティックセグメンテーション」について触れていきましょう。
インスタンスセグメンテーション
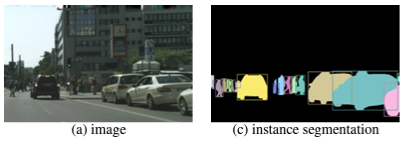
インスタンスセグメンテーションとは、画像内の全物体にラベルやカテゴリを関連づけるディープラーニングのアルゴリズムのこと。
セマンティックセグメンテーションよりも、詳しい物体の種類をラベル付けします。
人物ごと(佐藤さん、田中さんなど)・車の種類(ノア、ハスラー、ソリオなど)ごと、といった感じですね。
実際のイメージは以下のような感じ。
セマンティックセグメンテーションよりも優れているようにも見えますが、デメリットも存在します。
メリットとデメリットは、以下の通り。
メリット
より詳しい物体のラベル付けができる。
車1,2や佐藤・鈴木さんの区別ができる。
デメリット
道・空など決まった形のないラベルを検出できない
セマンティックセグメンテーションでは、空・道路など決まった形がないものにも、ラベルをつけられました。
これは、画像のピクセル(画素)全体に対して演算を行っているからですね。
しかし、インスタンスセグメンテーションは全ての物体に対してラベルを付与します。
なので、形が定まっていないと、何も付与しないようですね。

Mask R-CNN
Mask R-CNNとは、Faster R-CNNに「画像のピクセルレベルで意味が検出できる構造」を付与したモデル。
Mask R-CNNに関しては、以前の物体検出分野の際にも触れました。↓

実は「物体検出」と「インスタンスセグメンテーション」の2つを同時に行っているんです。
「画像をピクセルレベルで意味が検出できる構造」と言われて今回の記事を読んだ方は、ピンとくるかもしれません。
「ピクセルレベルで」という点が、セグメンテーションタスクですよね。
じゃあ、セグメンテーションタスクの中でも何を行っているかというと「インスタンスセグメンテーション」なんです。
このように、Mask R-CNNは「物体検出タスク」と「セグメンテーションタスク」のどちらも持っているアルゴリズムになりますね。
YOLACT, YOLACT++
YOLACT, YOLACT++とは、YOLOの派生形で物体検出のアルゴリズム。
YOLACTはインスタンスセグメンテーションと、物体検出に2つを組み合わせているようです。
YOLACT++もYOLOの派生形です。
名前の通り、YOLACTの改善版です。
どの点が改善されていたかの詳しい内容は、ここでは触れません。
シラバスにどちらの手法も載っていないためです。
それでも気になる方は調べてみるのも良いでしょう。
パノプティックセグメンテーション
パノプティックセグメンテーションとは、セマンティックセグメンテーションとインスタンスセグメンテーションの二つを合わせたアルゴリズム。
二つのいいとこ取りをしたイメージでしょうか。
つまり、
セマンティックセグメンテーションのように、物体と背景すべてにラベル付けをし、
インスタンスセグメンテーションのように、詳しい物体の種類までクラス分けする
といった感じでしょうか。
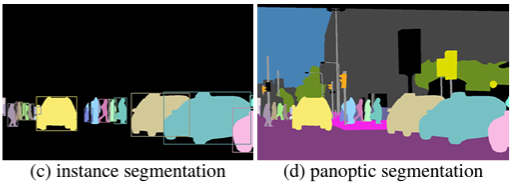
実際にパノプティックセグメンテーションを適用したイメージは以下の通り。

道路・空・歩道など、形のないものにも色がしっかりついていて、クラス分けできていますね。
さらに車・人それぞれにも違う色が付与されていて、異なる物体として検出していることが分かります。
Open Pose
Open Poseとは、深層学習を用いて人物の姿勢推定を行ったモデル。
2017年にカーネギーメロン大学が開発しました。
学習の主な流れは以下の通り。
1. confidense maps
入力画像から位置の推定する
2. Parts Affinity Fields
人間の関節と関節を結びつける領域のこと。これを検出する。
3. 1と2の集合から同じ人物の
部位を組み合わせ、姿勢状態を出力
Open poseはリアルタイムで、人物の関節・目・鼻・口といったパーツを検出できるようですね。
姿勢推定ができるようになったことで、スポーツ業界などを中心に利用が進んでいるようです。
今まで関節や人の姿勢というのは、体中にセンサを張り付けて推定していたからですね。
カメラとAI環境があれば姿勢推定ができるのは、今までよりも楽に効率的にできそうです。
マルチタスク学習
マルチタスク学習とは、単一のモデルで複数の課題を解くこと。
画像認識では以下のようなタスクを同時に行うことが多いです。
・領域識別
・クラス分類
・物体領域(セグメンテーション)の認識
古いモデルから改善されるごとに、一つのモデルでできることが増えていったようですね。
これまで見てきたように、新しいモデルになるにつれて高精度・様々なタスクができるようになっていることが分かったと思います。
まとめ
今回は大項目「ディープラーニングの手法」の中の一つ「画像認識分野 インスタンスセグメンテーション・パノプティックセグメンテーション」についての解説でした。
本記事をまとめると以下の3つ。
・インスタンスセグメンテーション
・Mask R-CNN
・パノプティックセグメンテーション
・Open pose
以上が大項目「ディープラーニングの手法」の中の一つ「画像認識分野 インスタンスセグメンテーション・パノプティックセグメンテーション」の内容でした。
ディープラーニングに関しても、細かく学習しようとするとキリがありませんし、専門的過ぎて難しくなってきます。
そこで、強化学習と同じように「そこそこ」で理解し、あとは「そういうのもあるのね」くらいで理解するのがいいでしょう。
そこで以下のようなことが重要になってくるのではないかと。
・ディープラーニングの特徴(それぞれの手法はどんな特徴があるのか)
・それぞれの手法のアルゴリズム(数式を覚えるのではなく、何が行われているか)
・何に使用されているのか(有名なもののみ)
ディープラーニングは様々な手法があるので、この三つだけでも非常に大変です。
しかし、学習を進めていると有名なものは、何度も出てくるので覚えられるようになります。
後は、新しい技術を知っているかどうかになりますが、シラバスに載っているものを押さえておけば問題ないかと。
次回は「ディープラーニングの手法」の「自然言語処理」に触れていきたいと思います。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント