
G検定|自然言語処理|Transformer・BERT・GPT・GPT-2, 3などを分かりやすく解説

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。
なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


目次
大項目「ディープラーニングの手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの手法」の内容。
その中でも「音声処理と自然言語処理分野」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
今回はディープラーニングの手法ということもあって、G検定のメインとなる内容。
ここを理解していないと、G検定合格は難しいでしょう。
ここから先の学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
今回は自然言語処理の最近利用されている応用手法を押さえていきたいと思います。
音声処理は自然言語処理の一分野ですが、重要キーワードが多いので、後の記事で詳しく解説しますね。
今までの記事で、見たことある単語も出てくるとは思いますが、復習の意味も兼ねて触れていきます。
まずは「言語モデル」についておさらいしておきますね。
言語モデル
言語モデルとは、文の品詞や統語構造、単語と単語、文書と文書などの関係性について定式化したもののこと。
自然言語処理の分野で、幅広く用いられているようです。
多くの場合は統計学的な観点から数式などを用いて、確率的に定めて式にしていきます。
最も可能性の高い組み合わせを文章化できるようですね。
代表例は以下の通り。
構文解析
Nグラムモデル
隠れマルコフモデル
最大エントロピーモデル
N-gram
N-gramとは、好きな文字数(N個)で文章を分割できる手法のこと。
言語モデルの一種でしたね。
区切り方は「文字数」「単語数」とあるようです。
「これはペンです」を例にとると、
文字数1で分割したときは
「こ / れ / は / ペ / ン / で / す」
文字数2で分割したときは
「これ / はペ / ンで / す」
という感じで分けられます。
単語数1で分割すると、
「これ / は / ペン / です」
となり、形態素解析と同じ分割にできることが分かるでしょうか。
形態素解析には「辞書」を使って分割していましたが、N-gramには不要という点がメリットでしょう。
任意の文字数は連続するN個の単語や、文字のまとまり内の文脈を考慮して決めます。
隠れマルコフモデル
隠れマルコフモデルとは、マルコフモデルの「状態」が隠れたもの。
マルコフモデルを理解できないと、隠れマルコフモデルが分かりません。
なので、マルコフモデルの解説を少しだけしたいと思います。
結構難しいので、丁寧に分かりやすく書いていきますね。
マルコフモデル(マルコフ過程)
「マルコフ過程(マルコフかてい)とは、マルコフ性をもつ確率過程のことをいう。すなわち、未来の挙動が現在の値だけで決定され、過去の挙動と無関係であるという性質を持つ確率過程である。」マルコフ過程(wikipedia)
マルコフ性と確率過程が分からないですよね。
それぞれ見ていきましょう。
確率過程
「確率過程(かくりつかてい、英語: stochastic process)は、時間とともに変化する確率変数のことである。」確率過程(wikipedia)
確率変数って何?という方は以下の記事を参考にしてみてください。
つまり「確率で変わる値が、さらに時間とともに変化する」のが確率過程といえます。
マルコフ性
マルコフ性とは、確率過程の性質の一種。
将来の状態が、今の状態のみから決まる性質のことです。
例えば天気の例を見てみましょう。
※天気は「晴れ」「曇り」「雨」しかないものとします。
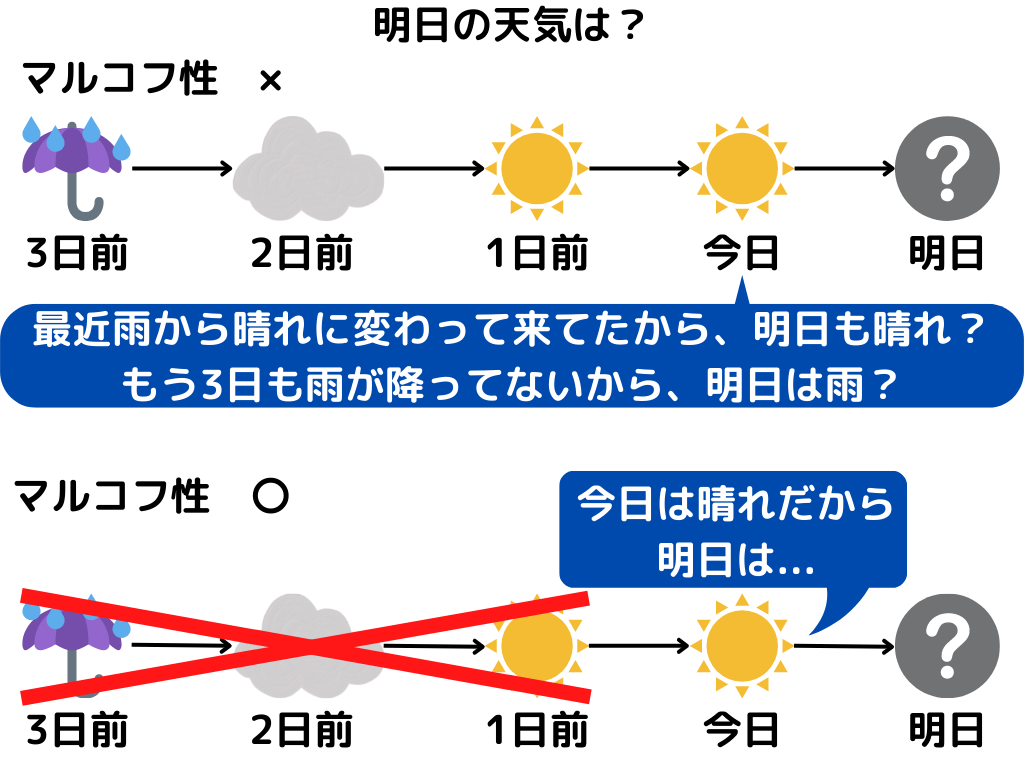
このように明日の天気が、今日の天気だけで決まると仮定することですね。
つまりマルコフ過程とは「将来の状態が現在の状態のみから決まる性質を持つ、時間によって変化する確率変数」と言い換えられます。
では、隠れマルコフモデルに戻りますね。
先ほどの天気の変わる確率を状態遷移図という以下のような図でも描けます。
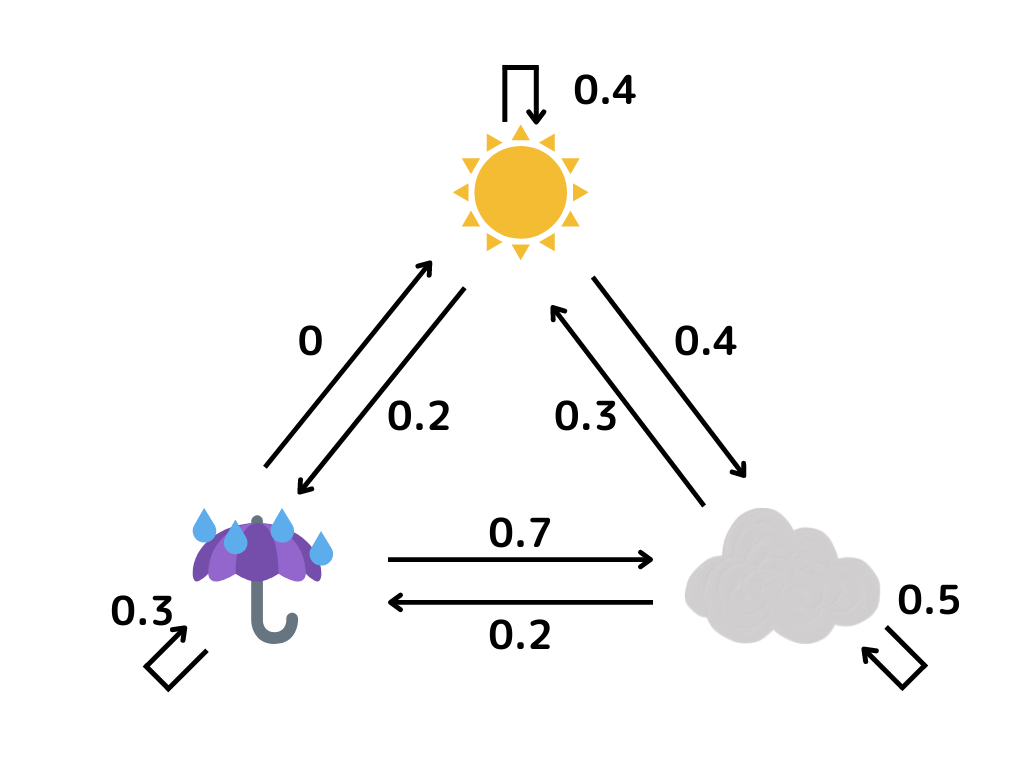
これに以下の仮定を追加します。
・自分は上記のような「天気が変わる確率」が分かっている
・友達が天気によって「スポーツ」「ゲーム」「買い物」のどれかを行い、その確率が分かる
・友達から「やったこと」は聞くが「天気」は分からない
「スポーツ」「ゲーム」「買い物」が出力と呼ばれ、自分が友達に聞くことで観測できますよね。
ただ「やったこと」に影響している状態(例では「天気」)は、自分からは分かりません。
これは「(自分から見て)状態が隠れている」といえるのではないでしょうか。
さて、隠れマルコフモデルとは、マルコフモデルの「状態」が隠れたもの、でしたね。
つまり先ほどの「天気と友達がやったこと」の例は、隠れマルコフモデルということになります。
図にするとこんな感じ。
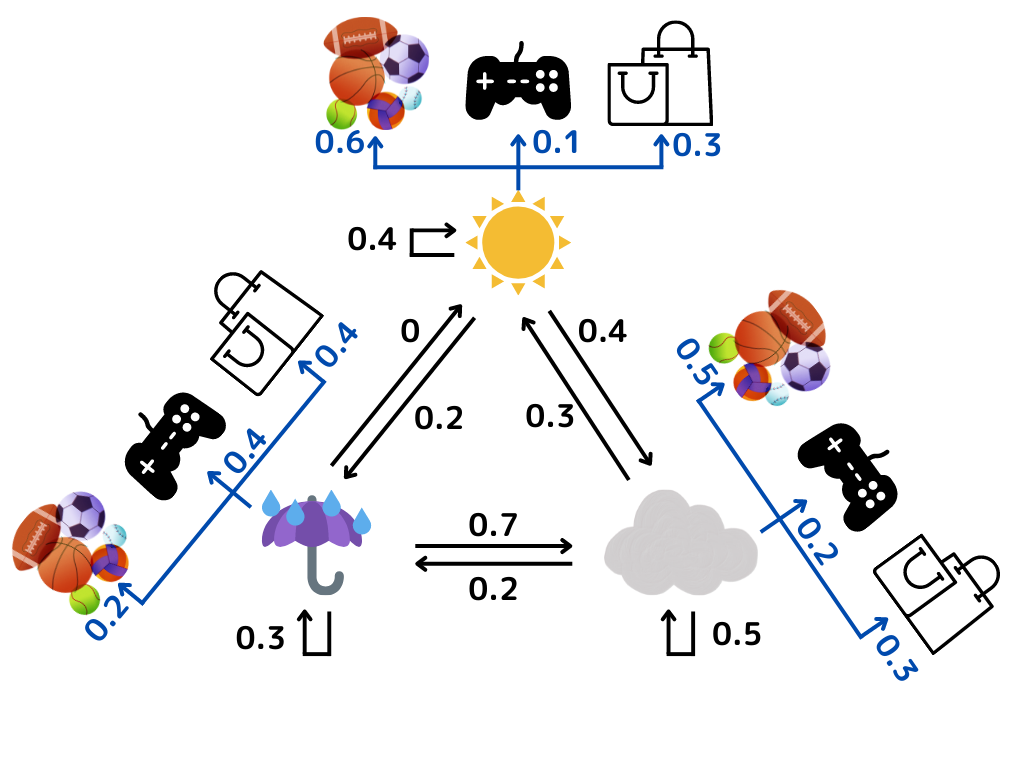
すごく複雑に見えますが、先ほどの例を図にしただけですね。
「天気は真ん中の三角形で変化し、それぞれの天気で友達の行動が変化する」という意味になります。
青矢印が「観測可能な出力」、黒矢印が「隠れた状態遷移」ですね。
Transformer
Transformerとは、RNNやCNNも用いずAttention(self-Attention)を使用している自然言語処理モデルのこと。
翻訳においては、それまで開発されていた手法を大きく上回ったようですね。
(翻訳以外に使われることもあります)
さらに学習時間の短縮にも成功したようです。
Transfomerは以下の二つの特徴があります。
・エンコーダ、デコーダ構造を持つ
・Attentionを主軸に構成している
先ほどの章でも述べましたが、二種類のAttentionが用いられています。
デコーダ側に用いられているのがSource-Target Attention、
エンコーダとデコーダの初期段階に使われているのがSelf-Attentionです。

位置エンコーディング
位置エンコーディングとは、Self-Attentionに位置情報を与える役割を持つ構造のこと。
実はSelf-Attentionには、単語の位置情報を考慮できる仕組みがありません。
重要度を出し「この単語同士は関連が強い」ということは分かるんですが、同じ単語を入れ替えて文章を作っても全く同じ値になってしまいます。
「私は野球をします」と「野球はします私を」が区別できません。
なのでTransformerのエンコーダ・デコーダ両方で各特徴ベクトルに対し,その位置に対応した値を足し合わせます。
そうすることで、位置を上手く考慮して翻訳が可能に。
このTransfomerは便利で、様々なところで使われています。
これから紹介する手法は、全てTransfomerをベースに考えられた応用手法です。
BERT
BERTとは、文頭と文末から読むことで「文脈を読むこと」を可能にしたモデル。
2018年にGoogle発表し、SoTAを達成しました。
当時の技術の中で、最も良い(最先端レベル)性能を発揮したということですね。
大規模なデータセットを用いて訓練した学習済みモデル(Pre-trained Models)の一つでもあります。
Transformerが使用され、さらに事前学習として以下の二つが使用されているようです。
MLM
(Masked Language Model)
文中の複数箇所をマスクし、本来の単語を予測する事前学習。
NSP
(Next Sentence Prediction)
連続した文かどうか判定する。
ALBERT
ALBERTとは、BERTの軽量版です。
A Lite BERTの略で、その名の通りBERTを軽くしたものですね。
パラメータの削減と学習速度向上が可能となっています。
XLNet
XLNetとは、BERTの改良版。
BERTはMasked Language Modelが、ノイズを発生させてしまうという問題があったようです。
そこでXLNetでは、Masked Language Modelに工夫をしています。
そのことによって、より長い文章に対応できるようになったようですね。
GPT
GPTとは、テキスト生成モデルの一つ。
2018年に、Open AIが考案しました。
特徴は以下の通り。
・Transformerをベースに作られる、テキスト生成モデル
・ラベルなしデータで言語モデルの事前学習
・言語モデルと分類器のファインチューニングを同時に行う
・1.1億のパラメータを使用
GPT-2
GPT-2とは、GPTの改良版のこと。
2019年にOpen AIから発表されました。
与えられたテキストの単語を元に、逐次的に次の単語を予測します。
GPTと異なる点は以下の二つ。
・ファインチューニングを行わない(または少数でOK)
・15億のパラメータを持つ
パラメータ数が約15倍になったことで、より高精度な文章生成ができるようですね。
GPT-3
GPT-3とは、GPT-2の改良版。
Open AIが2020年に開発しました。
基本的にはGPT-2とあまり変わらないようです。
最も異なるのは、1750億ものパラメータを持つこと。
圧倒的にパラメータ数が増えてますよね。
これによって、人間と大差ない文章生成が可能になっているようです。
GLUE
GLUEとは、自然言語処理の標準評価指標(ベンチマーク)のこと。
言語に関するテストデータが含まれていて、総合的な言語能力のスコアを算出します。
具体的には以下の通り。
・同義言い換え
・質疑応答
・文法が正しいか etc…
英語圏の自然言語処理では、この指標が基準になっているようです。
Vision Transformer
Vision Transformerとは、2020年にGoogleが発表した画像認識モデルのこと。
Transformerを応用したモデルを画像認識タスクにも応用したものです。
画像を単語のように分割し、CNNは使用しません。
自然言語処理分野の話ではあるのですが、画像処理が出てきました。
このようにTransfomerは、自然言語処理分野以外にも使われることがあります。
基本的には自然言語処理ですが、必ずしもそうではないということは覚えておきましょう。
まとめ
今回は大項目「ディープラーニングの手法」の中の一つ「音声処理と自然言語処理」についての解説第三弾でした。
本記事をまとめると以下の通り。
・言語モデル
・N-gram
・隠れマルコフモデル
・Transformer
・位置エンコーディング
・BERT
・MLM
・NSP
・GPT
・GPT-2
・GPT-3
・GLUE
・Vision Transfomer
以上が大項目「ディープラーニングの手法」の中の一つ「自然言語処理」の内容でした。
ディープラーニングに関しても、細かく学習しようとするとキリがありませんし、専門的過ぎて難しくなってきます。
そこで、強化学習と同じように「そこそこ」で理解し、あとは「そういうのもあるのね」くらいで理解するのがいいでしょう。
そこで以下のようなことが重要になってくるのではないかと。
・ディープラーニングの特徴(それぞれの手法はどんな特徴があるのか)
・それぞれの手法のアルゴリズム(数式を覚えるのではなく、何が行われているか)
・何に使用されているのか(有名なもののみ)
ディープラーニングは様々な手法があるので、この三つだけでも非常に大変です。
しかし、学習を進めていると有名なものは、何度も出てくるので覚えられるようになります。
後は、新しい技術を知っているかどうかになりますが、シラバスに載っているものを押さえておけば問題ないかと。
次回は「ディープラーニングの手法」の「音声処理」に触れていきたいと思います。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!





