

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「ディープラーニングの手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの手法」の内容。
その中でも「深層生成モデル」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
今回はディープラーニングの手法ということもあって、G検定のメインとなる内容。
ここを理解していないと、G検定合格は難しいでしょう。
ここから先の学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
今回は深層生成モデルの基本的な内容、基本的な手法を押さえていきたいと思います。
生成モデルの考え方
生成モデルの考え方は、モデルだけで新しいデータ(画像など)生み出そうというもの。
生成モデルの学習時には、既にあるデータを用いて学習を行います。
画像を例に取ってみましょう。
入力には画像データ(1ピクセルごとの色情報など)を用いて、画像の特徴を学習。
学習が完了したら、モデルのみで新しい画像を生成できるようになります。
生成モデルにディープラーニングを用いることで、より複雑な画像を生成できるようになりました。
変分オートエンコーダ(VAE)
変分オートエンコーダ(VAE)とは、実在しないデータ(画像)を生み出せるモデルのこと。
これにより、モデルは存在しない人の画像などのデータを作成できるようになりました。
VAEの大まかな流れは以下の通り。
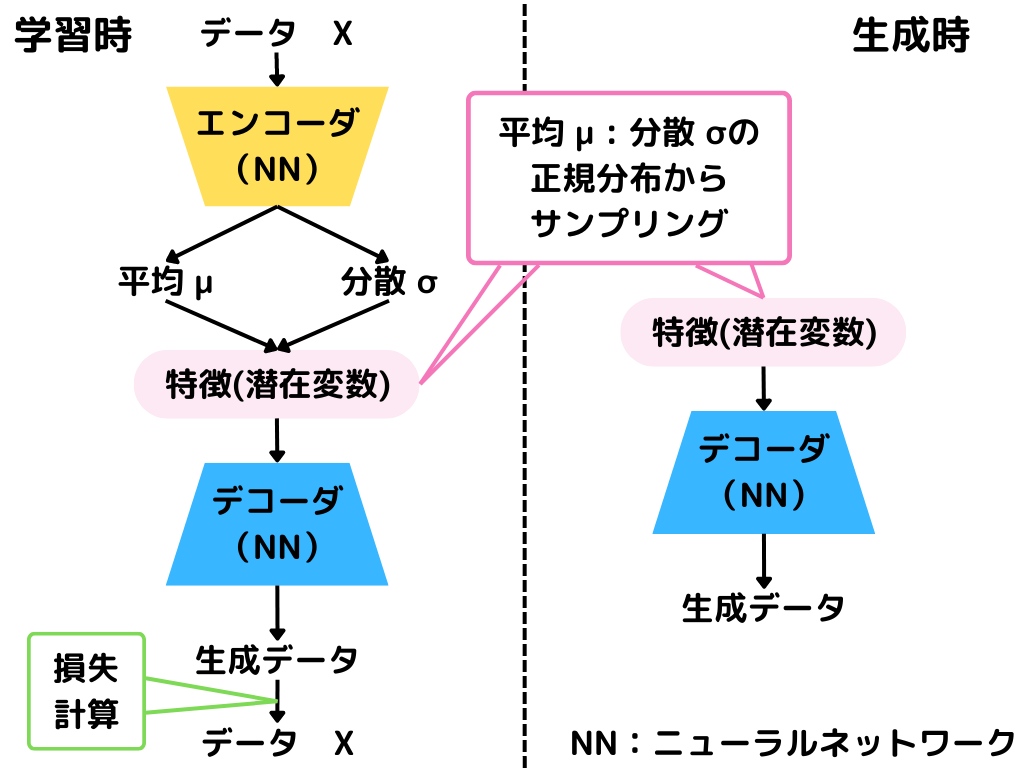
学習時はエンコーダで特徴を抽出し、その特徴からデコーダで画像を生成します。
生成画像を元の画像を見比べることで、似るように学習していく形ですね。
生成時にはデコーダだけを使い、画像を生成していきます。
エンコーダ・デコーダについて以下でもう少し詳しく見ていきましょう。
ちなみにオートエンコーダというものもあること、ご存じでしょうか。
G検定のシラバスにも載っており、以下の記事で解説しているので、見てみてください。

オートエンコーダは変分オートエンコーダと違い、「もともとのデータを忠実に再現したい」というのが目的でした。
エンコーダ部分
エンコーダ部分は元画像を受け取り、潜在変数を学習するニューラルネットワークになっています。
つまり入力は元画像、出力は潜在変数となりますね。
潜在変数というのは、元データから潜在的に分かる特徴のこと。
例えば「気温」「湿度」が分かれば「季節」が予測しやすいですね。
「季節」のように、元データから直接は分からないけど潜在的に分かるデータが潜在変数です。
エンコーダは学習時にしか使いません。
元画像の潜在変数の分布を学習し、その分布の平均と分散を出力します。
デコーダ部分
デコーダ部分は潜在変数を受け取り、画像を出力するニューラルネットワークになっています。
つまり入力は元潜在変数、出力は画像となりますね。
潜在変数は、エンコーダが出力した分布からランダムに取得。
取得した潜在変数から画像を出力して、正解画像に近づくように学習していきます。
生成時にはデコーダ部分しか使いません。

敵対的生成ネットワーク(GAN)
敵対的生成ネットワーク(GAN)とは疑似画像を生成するモデルと、疑似画像の正誤を判定するモデルを敵対させて画像を生成するモデル。
疑似画像を生成するモデルをジェネレータといい、疑似画像生成の犯罪者のようなイメージです。
疑似画像の正誤を判定するモデルをディスクリミネータといい、疑似画像を見分ける警察官のようなイメージかと。
全体の学習や生成の流れは以下の通り。
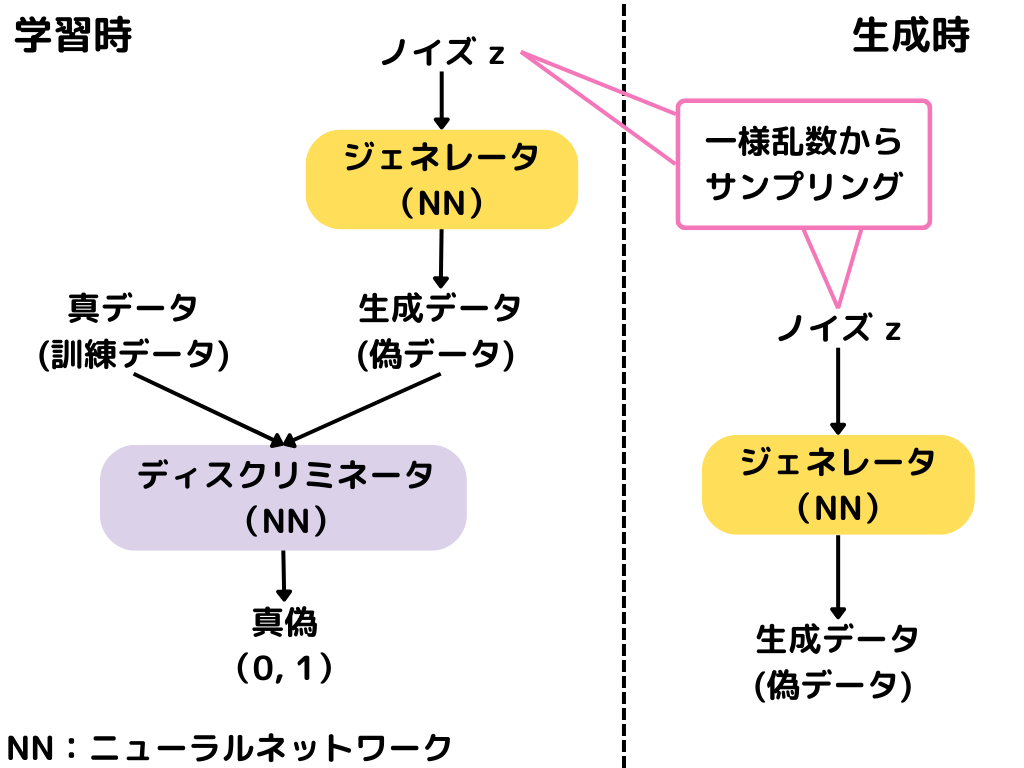
訓練時にはジェネレータとディスクリミネータを敵対させて学習していきます。
生成時にはジェネレータのみを使って画像生成するんですね。
以下でジェネレータとディスクリミネータについてもう少し詳しく見ていきましょう。
ジェネレータ
ジェネレータは、疑似データ(画像など)を生成するニューラルネットワーク。
入力はランダムなノイズで、出力は疑似データです。
出力する疑似データをディスクリミネータに見抜かれないように学習していきます。
損失関数は疑似データが偽物であると判断される確率。
つまり、損失関数を最小化するように学習していきます。
ディスクリミネータ
ディスクリミネータは、疑似データ(画像など)を判別するニューラルネットワーク。
入力はジェネレータが生成した疑似データで、出力は真偽(訓練データか疑似データか)です。
疑似データを訓練データ(正しいデータ)と見比べることで、疑似データが偽物か否かを判定します。
損失関数はジェネレータと同様で、疑似データが偽物であると判断される確率。
つまりジェネレータとは逆で、損失関数を最大化するように学習します。
続いて、GANの応用例を見ていきましょう。
DCGAN
DCGANとは、GANよりも自然な画像の生成が可能になったモデル。
基本的な構造はGANと変わりません。
GANではジェネレータとディスクリミネータに普通のニューラルネットワークを使っていました。
DCGANでは、畳み込みニューラルネットワーク(CNN)を使っています。
(プーリング層や全結合層はないんですが)
これによって、より自然な画像の生成が可能になりました。
CNNが画像によく使われることからも、これはイメージしやすいのではないでしょうか。
Pix2Pix
Pix2Pixとは、入力された画像に対応する画像を生成できるアルゴリズム。
こちらもGANの一種です。
二枚の画像をペアにしたものが入力されます。
するとpix2pixが二枚の画像の関係性を学習して、1枚の画像から対応するもう1つの画像を生成。
言葉よりも図を見た方が早いと思います。


Inputが入力画像、Ground truthが教師データです。
InputとGround truthの画像をペアにして学習させることで、Outputのような新しい画像が生成されます。
CycleGAN
CycleGANとは、pix2pixの発展バージョン。
つまりこちらもGANの一種ですね。
pix2pixは二枚の画像をペアにしていないと学習できませんでした。
でも、全てペアの画像を用意するって大変じゃないですか?
そこでCycleGANでは、ペアではなくても「こういう雰囲気の画像が欲しい」というデータで、学習できるようになりました。
例えば「風景画像」を「浮世絵風」や「モネの絵風」にしたい、といったことですね。
この場合pix2pixでは同じ場所の同じ視点からの画像が、「風景画像」「浮世絵」「モネの絵」すべてで必要でした。
CycleGANでは、同じ場所ではなくても「風景画像」「浮世絵」「モネの絵」のデータがあれば学習できます。
つまり以下のようなデータで学習ができるんです。
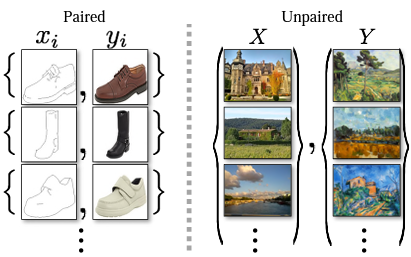
左はpix2pixでの学習データで、画像が「ペア(同じ形状など)」になっていないといけません。
しかしCycleGANでは、写真(X)と絵(Y)で全く違う場所の絵ばかりですよね。
これは「ペア」になっていません。
用意するデータが「ペア」でなくても良くなったので、比較的楽にデータを集められますね。
そして、学習したモデルを実際に使ってみると以下のようになります。

入力(input)は写真ですが、その写真が「モネ風(Monet)」「ゴッホ風(Van Gogh)」「浮世絵風(Ukiyo-e)」といった感じに変えられています。
この他にも写真の季節を変えたり、馬をシマウマにしたりといったことができるようですね。
まとめ
今回は大項目「ディープラーニングの手法」の中の一つ「深層生成モデル」についての解説でした。
本記事をまとめると以下の3つ。
・変分オートエンコーダ(VAE)
・敵対的生成ネットワーク(GAN)
・ジェネレータ
・ディスクリミネータ
・DCGAN
・Pix2Pix
・CycleGAN
以上が大項目「ディープラーニングの手法」の中の一つ「深層生成モデル」の内容でした。
ディープラーニングに関しても、細かく学習しようとするとキリがありませんし、専門的過ぎて難しくなってきます。
そこで、強化学習と同じように「そこそこ」で理解し、あとは「そういうのもあるのね」くらいで理解するのがいいでしょう。
そこで以下のようなことが重要になってくるのではないかと。
・ディープラーニングの特徴(それぞれの手法はどんな特徴があるのか)
・それぞれの手法のアルゴリズム(数式を覚えるのではなく、何が行われているか)
・何に使用されているのか(有名なもののみ)
ディープラーニングは様々な手法があるので、この三つだけでも非常に大変です。
しかし、学習を進めていると有名なものは、何度も出てくるので覚えられるようになります。
後は、新しい技術を知っているかどうかになりますが、シラバスに載っているものを押さえておけば問題ないかと。
次回は「ディープラーニングの手法」の「深層強化学習」に触れていきたいと思います。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント