

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「ディープラーニングの手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの手法」の内容。
その中でも「画像認識分野」に焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
ここを理解していないと、G検定に合格も難しいでしょう。
難しく内容も多い部分ですが、しっかり覚えていきたいですね。
今回は画像認識分野の中でも「物体識別」について押さえていきたいと思います。
画像認識タスク
画像認識タスクには、以下の3つに大別されます。
・物体識別タスク
・物体検出タスク
・セグメンテーションタスク
「画像認識って全部同じじゃないの?」と思った方は、注意して覚えるようにしましょう。
それぞれのタスクで、非常にたくさんの手法が開発されています。
そこで本記事では、それぞれのタスク毎に手法を分けて解説していきますね。
本日は物体検出タスクについて触れていきましょう。
物体検出タスク
物体検出タスクとは、画像に写っている全ての物体の矩形領域の位置、ラベルを検出するタスク。
前回の記事の「物体識別タスク」とは何が違うかというと、位置情報まで検出する点です。
基本的なCNNの説明で「位置情報はいらないからプーリング層で位置情報を上手く消す」という説明をしました。
でも、位置まで把握したいこともありますよね。
画像内に、複数の物体があった場合はどうなってしまうのでしょうか?
位置情報を消してしまっては、上手く学習ができないこともあります。
そこで「写っている物体が何(ラベル)で、どこ(位置)にあるのか」を検出できるタスクが、物体検出タスクです。
矩形領域
矩形領域とは、画像の中に写っている物体のある領域を矩形で表したもの。
矩形というのは長方形のことですね。
バウンディングボックスと言われる事も。
こちらの言い方の方が多かったりするので、覚えておくと良いと思います。
物体検出タスクでは、最初にバウンディングボックスを作成するんですね。
そしてバウンディングボックス内の物体の種類を判別していく流れになります。
R-CNN
R-CNNとは、物体検出のための基本的なCNNモデル。
最初に入力画像から関心領域を抽出します。
検出したい物体がどこにあるか、ですね。
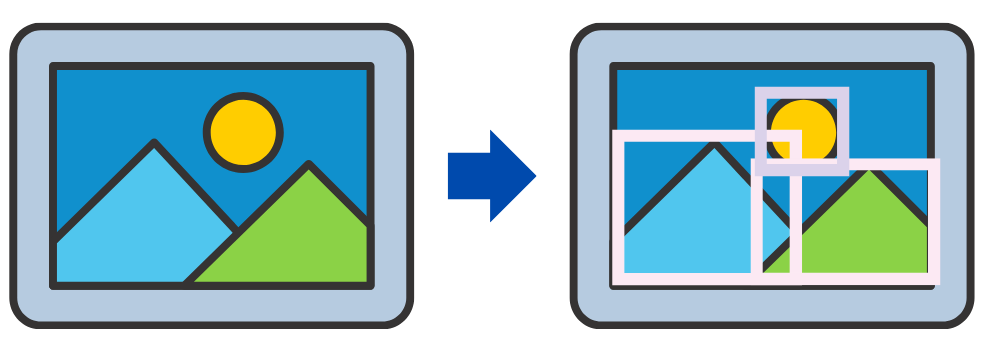
そして検出したい物体に注目し、それをバウンディングボックスで囲います。
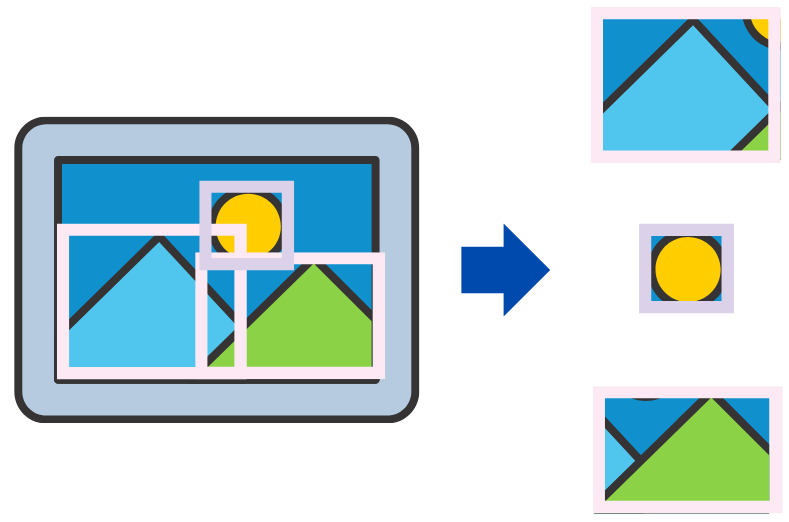
囲むときには、対象の物体が四角にピッタリ収まるように囲むようです。
次に四角の領域毎にニューラルネットワーク(CNN)に通して、特徴量を出力。
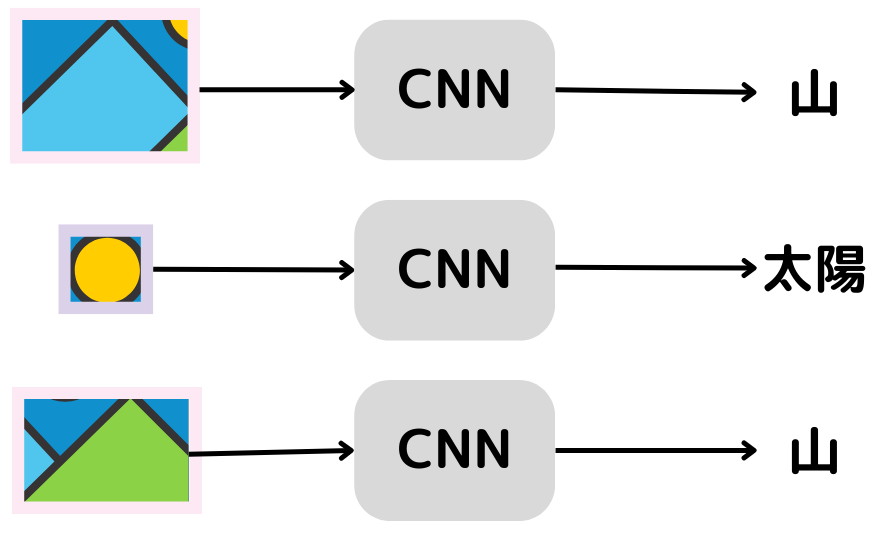
CNNは画像分類によく用いられる手法ということは覚えているでしょうか。
特徴が抽出できたら画像を分類することで、領域毎の物体ラベル(物体の種類)が分類できます。
Fast R-CNN
Fast R-CNNとはその名の通り、R-CNNよりも速い計算速度のR-CNN。
先ほど「R-CNNは四角の領域毎にニューラルネットワーク(CNN)に通して、特徴量を出力」と説明しましたね。
しかしそれだと、一回の計算でも重いニューラルネットワークを何回もやらなければいけません。
これでは、計算に時間がかかってしまうのも当然のこと。
そこで一つ一つの関心領域ではなく、画像全体に対して1回だけニューラルネットワークを実行します。
これにより演算回数の削減ができ、より計算速度が早いR-CNNができたようですね。

Faster R-CNN
Faster R-CNNとは、Fast R-CNNよりもさらに計算効率を上げたモデルのこと。
R-CNN、Fast R-CNNでは、バウンディングボックスの作りかたが一緒でした。
主な流れとしては、
物体の場所把握→バウンディングボックス作成→ニューラルネットワーク(CNN)に通してラベル分類
でしたね。
Faster R-CNNでは、最初の2工程もニューラルネットワークに組み込んでしまいます。
そうすることで、手順が
「バウンディングボックス作成→ニューラルネットワーク」だったものが、
「ニューラルネットワーク」のみとなります。
このようにして計算量の削減を行ったようですね。
Mask R-CNN
Mask R-CNNとは、Faster R-CNNに「画像のピクセルレベルで意味が検出できる構造」を付与したモデル。
これにより、物体の種類も判別できるようになりました。
「R-CNNができることと何が違うの?」と思いますよね。
Faster R-CNNまでは「車、飛行機、電車」のようなもの(ラベルという)を判別することはできました。
しかし「車」といっても色んな種類がありますよね。
同じ「車」だったとしても、それが「ルークス」なのか「ノア」なのか「ワゴンR」なのか…
これがFaster R-CNNまでは判別できなかったんです。
しかし「画像をピクセルレベルで意味が検出できる構造」を付与することで、同じ「車」でも何の種類(クラス)なのかが判別可能に。
なので物体検出に加え、ラベルの種類を認識しクラス分類も行うことができるようになりました。
色んなサイトを見てると、「ラベル」や「クラス」はごっちゃになって説明されている気がします。
上記のように具体例で覚えた方が覚えやすいでしょう。
Mesh R-CNN
Mesh R-CNNとは、二次元画像から3Dメッシュの画像を生成する機能があるCNNのこと。
この手法より前にも、二次元→三次元の研究は行われていました。
しかし、範囲は限定的で精度も良くなかったようです。
Mesh R-CNNによって、より広範囲で精度が良い3Dメッシュを作成できるようですね。
FPN
FPNとはCNNの後ろにくっつけた、マルチスケールの画像の特徴集約を行う構造。
Feature Pyramid Networksの略でFPNです。
画像のスケールが変わることに対応しなきゃいけない時などに使えるようですね。
例えば画像が2, 3倍と拡大されたり、0.5倍と縮小されたり…
FPNは普通のCNNの後ろにくっつけます。
普通のCNNでは層を重ねる毎に、画像のスケールが小さくなったことは覚えているでしょうか?
画像のスケールが小さくなって、特徴を抽出できたのがCNNでした。
最後の特徴マップから今度は、スケールを元に戻していきます。
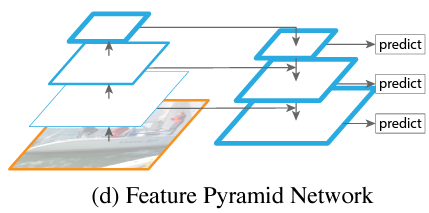
この戻す過程でピラミッドに見えることから、Feature Pyramid Networksと覚えるのが良いでしょう。
戻しながら、同じスケールの特徴マップと合わせて予測することで、画像のスケールが変わる予測でも精度良くできたようです。
YOLO
YOLOとは、リアルタイム物体検出アルゴリズムのこと。
You Look Only Onseの略でYOLOです。
物体検出では、バウンディングボックス作成してラベルを識別する、という流れでしたよね。
しかしYOLOでは、
・バウンディングボックス作成して、物体検出
・バウンディングボックス内のラベル識別
これらを同時に行います。
そうすることで、画像入力から出力までの時間が短くなり、リアルタイムで物体検出が可能になったようです。
SSD
SSDとは、YOLOと同系統の1ステージ型検出アルゴリズム。
Single shot MuitiBox Detectorの略でSSDですね。
1ステージ型検出アルゴリズムとは、R-CNNの発展型です。
R-CNNや、その関連技術はバウンディングボックスを作成するために、以下の流れを踏んでいました。
バウンディングボックス作成→CNNに通す→修正→バウンディングボックス作成→・・・
これでは時間がかかってしまうので、画像全体を一回のCNN演算で「物体検出」「ラベル識別」を行おうというものがSSD。
YOLOにも、同様の特徴がありましたね。
では、YOLOとの違いは何なのでしょうか?
・YOLOよりも小さい物体検出に長けている
・YOLOよりも低解像度でも、比較的高精度に検出可能
この辺りが、YOLOと異なる点と言えると思います。
まとめ
今回は大項目「ディープラーニングの手法」の中の一つ「画像認識分野 物体検出」についての解説でした。
本記事をまとめると以下の3つ。
・物体検出タスク
・矩形領域
・R-CNN
・Fast R-CNN
・Faster R-CNN
・Mask R-CNN
・FPN
・YOLO
・SSD
以上が大項目「ディープラーニングの手法」の中の一つ「画像認識分野 物体検出」の内容でした。
ディープラーニングに関しても、細かく学習しようとするとキリがありませんし、専門的過ぎて難しくなってきます。
そこで、強化学習と同じように「そこそこ」で理解し、あとは「そういうのもあるのね」くらいで理解するのがいいでしょう。
そこで以下のようなことが重要になってくるのではないかと。
・ディープラーニングの特徴(それぞれの手法はどんな特徴があるのか)
・それぞれの手法のアルゴリズム(数式を覚えるのではなく、何が行われているか)
・何に使用されているのか(有名なもののみ)
ディープラーニングは様々な手法があるので、この三つだけでも非常に大変です。
しかし、学習を進めていると有名なものは、何度も出てくるので覚えられるようになります。
後は、新しい技術を知っているかどうかになりますが、シラバスに載っているものを押さえておけば問題ないかと。
次回は「ディープラーニングの手法」の中の一つ「画像認識分野 セマンティックセグメンテーション」に触れていきたいと思います。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント