

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「ディープラーニングの手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの手法」の内容。
その中でも「画像認識分野」に焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
ここを理解していないと、G検定に合格も難しいでしょう。
難しく内容も多い部分ですが、しっかり覚えていきたいですね。
今回は画像認識分野の中でも「物体識別」について押さえていきたいと思います。
画像認識タスク
画像認識タスクには、以下の3つに大別されます。
・物体識別タスク
・物体検出タスク
・セグメンテーションタスク
「画像認識って全部同じじゃないの?」と思った方は、注意して覚えるようにしましょう。
それぞれのタスクで、非常にたくさんの手法が開発されています。
そこで本記事では、それぞれのタスク毎に手法を分けて解説していきますね。
本日はセグメンテーションタスクについて触れていきましょう。
セグメンテーションタスク
セグメンテーションタスクとは位置をピクセル単位で検出し、ラベルを検出するタスクのこと。
画像に写っている全ての物体に対して行います。
コンピュータ画像も細かく見ていくと、一つ一つ四角に区切られていて、そこに色の情報が入ってるんですね。
この最小構成単位(一個の四角)を、ピクセル(画素)といいます。
ピクセル単位で位置を検出するので、物体検出タスクよりも物体の輪郭を捉えやすくなるようです。
イメージとしては以下の様な感じ。(セグメンテーションタスクの一種類です)

セグメンテーションタスクは、以下の三種類に分けることができます。
・セマンティックセグメンテーション
・インスタンスセグメンテーション
・パノプティックセグメンテーション
今回はセマンティックセグメンテーションについて触れていきます。
セマンティックセグメンテーション
セマンティックセグメンテーションとは、画像内の全ピクセルにラベルやカテゴリを関連づけるディープラーニングのアルゴリズム。
全ピクセルにラベル付けするので、物体の輪郭通りに位置を検出できます。
また、画像に写っているもの全てをラベル付けすることも可能ですね。
この方法のメリットは以下の通り。
・画像に写っているもの全てをラベル付けして分類できる
・決まった形がないもの(空、道路、海など)も区別できる
デメリットは以下の様な感じでしょうか。
・同じ物体であればラベルが同じになる(車、人など)
・車1,2や佐藤・鈴木さんの区別ができず
セマンティックセグメンテーションの関連用語としては以下の様なものがあります。
・FCN
・SegNet
・U-Net
・PSPNet
・Dilation/Atrous convolution
・DeepLab
それぞれ、シラバスに乗っている重要キーワードなので、覚えていきましょう。

FCN
FCN (Fully Convolutional Network)とは全結合層を持たない、ネットワークが畳み込み層のみで構成された畳み込みニューラルネットワークのこと。
セマンティックセグメンテーション用に作られたもののようです。
セマンティックセグメンテーションにディープラーニングを取り入れた最初の手法ですね。
普通のCNNでは、全結合層で二次元のデータを一次元にしてしまいます(1列に並び替える)。
これだと、物体の位置が分からないのでセマンティックセグメンテーションができません。
そこで最後の全結合層に工夫をすることで、全ての層を畳み込み層にし、位置の把握もできるようにしたようです。
U-Net
U-Netは、全層畳み込みネットワーク(FCN)の一種。
まず「エンコード」と「デコード」という言葉が出てくるので、軽く触れておきますね。
エンコードとは、データを別の形式に変換する事の総称
(今回は画像を畳み込んで、特徴抽出する過程)
デコードとは、変換されたデータを元に戻す作業の総称
(最終的な特徴マップから、元の画像を復元する作業)
といった感じでしょうか。
U-Netと呼ばれる所以は、論文の画像を見ると一目瞭然。
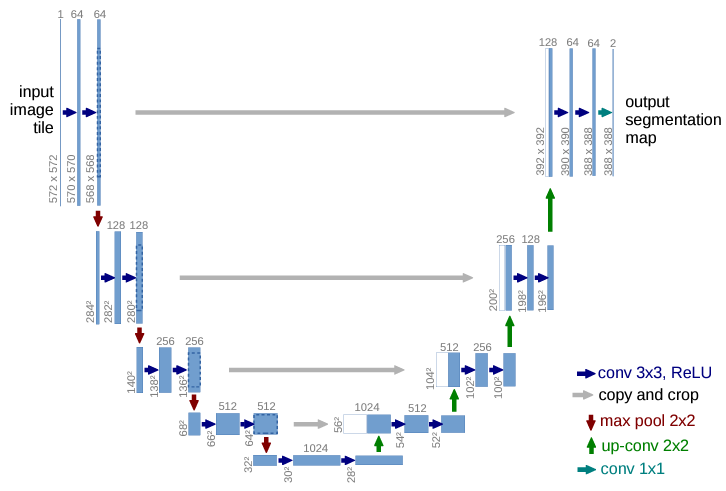
この形がUに見えることから、U-Netと呼ぶようです。
U字の左半分がエンコード、右半分がデコードですね。
畳み込まれた画像をデコードする際に、エンコードで使った情報を用いるのが特徴です。(灰色の矢印)
SegNet
SegNetは2017年にケンブリッジ大学が提案した、セマンティックセグメンテーションの1つ。
以下の2つの構造で成り立っています。
・入力画像から特徴マップの抽出を行うエンコーダ
・特徴マップと元の画像のピクセル位置の対応関係をマッピングするデコーダ
まずエンコーダでは、普通のCNNと同じように「畳み込み層」→「プーリング層」を繰り返すことで、特徴を抽出します。
この時点での特徴マップは、物体の大まかな位置とラベルが分かりますが、解像度が荒い状態。
そこでデコーダで、抽出した特徴マップを元の画像に戻しながら「位置」「ラベル」をマッピングします。
こうすることで、より正確に物体の位置、輪郭を捉えるようになったようですね。
PSPNet
PSPNetは、エンコーダ・デコーダを用いたセマンティックセグメンテーションの手法の1つ。
U-Net・SegNetのおかげで、セマンティックセグメンテーションはエンコーダ・デコーダを用いることが多くなったようです。
そこで、PSPNetもエンコーダ・デコーダを採用。
「エンコーダ」と「エンコーダとデコーダの間」の2つに工夫があります。
エンコーダにはResNet101の特徴抽出層を使用。
さらにエンコーダとデコーダの間にPyramid Pooling Moduleを追加しているのが特徴です。
Pyramid Pooling Moduleで得られるのは以下の2つ。
・特徴マップの大域的な情報
・特徴マップの局所的な部分の情報
DeepLab
DeepLabとは、Googleが作ったセマンティックセグメンテーション向け多層ニューラルネットワーク構造のこと。
以下の2つの構造を持っています。
・ResNetのニューラルネットワーク
・Dilated/Atrous畳み込み構造
「Dilated/Atrous畳み込み構造」という新しいものが出てきましたね。
これを持つことが、DeepLabの特徴になります。
では、「Dilated/Atrous畳み込み構造」とは何なのでしょうか。
Dilation/Atrous convolution
Dilation/Atrous convolutionは、隙間の空いた歯抜けのフィルタで畳み込む手法のこと。
畳み込みをするときのフィルタはn×nの正方形をしていました。
このフィルタを歯抜けさせたのが、Dilation/Atrous convolution(Dilated/Atrous畳み込み構造)。
poolingを使わずとも、小さなフィルターサイズで長距離の畳み込みができます。
イメージは以下の通り。
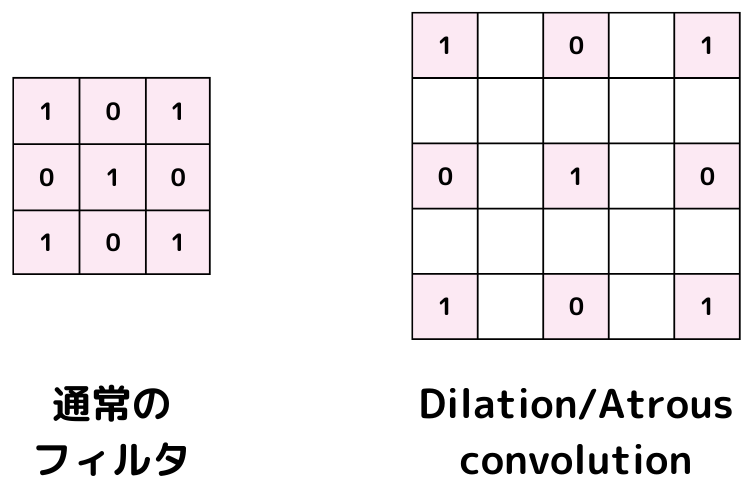
図で示したような構造が「歯抜け」です。
こうすることで、単純に一回のフィルタで計算できる面積が増えますよね。
つまり、より広範囲を効率的に計算できるようになったようです。
まとめ
今回は大項目「ディープラーニングの手法」の中の一つ「画像認識分野 セマンティックセグメンテーション」についての解説でした。
本記事をまとめると以下の3つ。
・セマンティックセグメンテーション
・FCN
・U-Net
・SegNet
・PSPNet
・DeepLab
・Dilation/Atrous convolution
以上が大項目「ディープラーニングの手法」の中の一つ「画像認識分野 セマンティックセグメンテーション」の内容でした。
ディープラーニングに関しても、細かく学習しようとするとキリがありませんし、専門的過ぎて難しくなってきます。
そこで、強化学習と同じように「そこそこ」で理解し、あとは「そういうのもあるのね」くらいで理解するのがいいでしょう。
そこで以下のようなことが重要になってくるのではないかと。
・ディープラーニングの特徴(それぞれの手法はどんな特徴があるのか)
・それぞれの手法のアルゴリズム(数式を覚えるのではなく、何が行われているか)
・何に使用されているのか(有名なもののみ)
ディープラーニングは様々な手法があるので、この三つだけでも非常に大変です。
しかし、学習を進めていると有名なものは、何度も出てくるので覚えられるようになります。
後は、新しい技術を知っているかどうかになりますが、シラバスに載っているものを押さえておけば問題ないかと。
次回は「ディープラーニングの手法」の「画像認識分野 インスタンスセグメンテーション・パノプティックセグメンテーション」に触れていきたいと思います。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント