

※本記事はアフィリエイト広告を含んでいます

どーも、りけーこっとんです。
「G検定取得してみたい!」「G検定の勉強始めた!」
このような、本格的にデータサイエンティストを目指そうとしている方はいないでしょうか?
また、こんな方はいませんか?
「なるべく費用をかけずにG検定取得したい」「G検定の内容について網羅的にまとまってるサイトが見たい」
今回はG検定の勉強をし始めた方、なるべく費用をかけたくない方にピッタリの内容。
りけーこっとんがG検定を勉強していく中で、新たに学んだ単語、内容をこの記事を通じてシェアしていこうと思います。
結構、文章量・知識量共に多くなっていくことが予想されます。
そこで、超重要項目と重要項目、覚えておきたい項目という形で表記の仕方を変えていきたいと思いますね。
早速G検定の中身について知りたいよ!という方は以下からどうぞ。

具体的にどうやって勉強したらいいの?
G検定ってどんな資格?
そんな方は以下の記事を参考にしてみてください。

なお、りけーこっとんは公式のシラバスを参考に勉強を進めています。
そこで主な勉強法としては
分からない単語出現 ⇒ web検索や参考書を通じて理解 ⇒ 暗記する
この流れです。
※この記事は合格を保証するものではありません


大項目「ディープラーニングの手法」
G検定のシラバスを見てみると、試験内容が「大項目」「中項目」「学習項目」「詳細キーワード」と別れています。
本記事は「大項目」の「ディープラーニングの手法」の内容。
その中でも「音声処理と自然言語処理分野」というところに焦点を当ててキーワードを解説していきます。
G検定の大項目には以下の8つがあります。
・人工知能とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的な手法
・ディープラーニングの概要
・ディープラーニングの手法
・ディープラーニングの社会実装に向けて
・数理統計
とくに太字にした「機械学習とディープラーニングの手法」が多めに出るようです。
今回はディープラーニングの手法ということもあって、G検定のメインとなる内容。
ここを理解していないと、G検定合格は難しいでしょう。
ここから先の学習の理解を深めるために、そしてG検定合格するために、しっかり押さえておきましょう。
今回は自然言語処理の基本的な内容、基本的な手法を押さえていきたいと思います。
音声処理は自然言語処理の一分野ですが、重要キーワードが多いので、後の記事で詳しく解説しますね。
今までの記事で、見たことある単語も出てくるとは思いますが、復習の意味も兼ねて触れていきます。
マルチタスク学習
まずは画像処理分野でも触れた「マルチタスク学習」について触れたいと思います。
マルチタスク学習とは、単一のモデルで複数の課題を解くこと。
自然言語処理では以下のようなタスクを同時に行うことが多いです。
・品詞づけ
・文節判定
・係り受け
・文意関係(補強・反対・普通)
・文関係の度合い
古いモデルから改善されるごとに、一つのモデルでできることが増えていったようですね。
画像処理分野でも見てきたように、新しいモデルになるにつれて高精度・様々なタスクができるようになっていることが分かったと思います。
RNN
RNNとは、時系列データを扱うためのモデル。
正式名称は、リカレントニューラルネットワーク (RNN)です。
時系列データ、というのが自然言語処理のデータになります。
時系列データとは何かというと「決まった時間ごとに取得したデータ」のこと。
時系列データは入力を一つ一つ独立して見ることはしません。
時間に沿って、一連の流れで入力されたデータとして取り扱うんです。
なので「時間的に前のデータが後ろのデータに影響する」ということが起こります。
例えば「毎年6月は雨が降りやすい(前年のデータが今年にも影響している)」といった風に。
これが自然言語でも、同様のことが起こると考えます。
文章で「私」という単語が入力されたら、次に来る単語は何でしょうか?
「動物」「車」などが入ってはおかしいですよね。
「は」「の」「を」「に」「が」などが入るというのは予想できるのではないでしょうか。
このように自然言語処理は「時系列データ」として扱えるんですね。
つまりRNNを使えるということ。
RNNは時間ごとに、ニューラルネットワークを用いて予測値を出力します。
この時、過去の入力による隠れ層の状態を、現在の入力に対する出力を求めるために使います。
図にすると以下のような感じ。
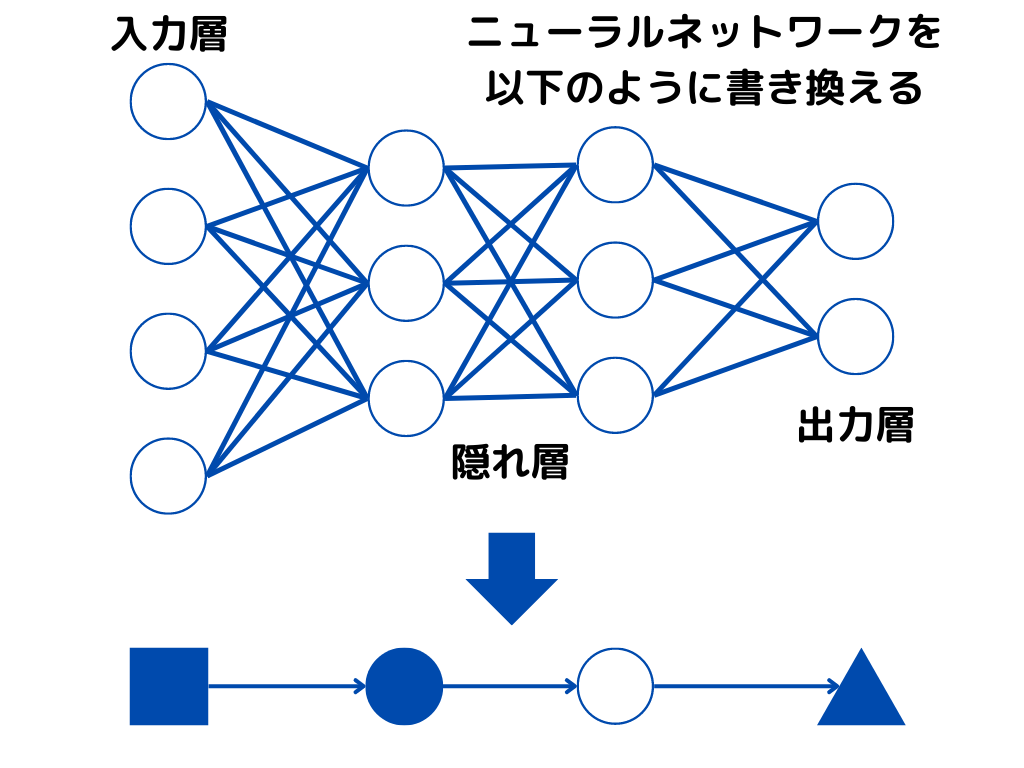
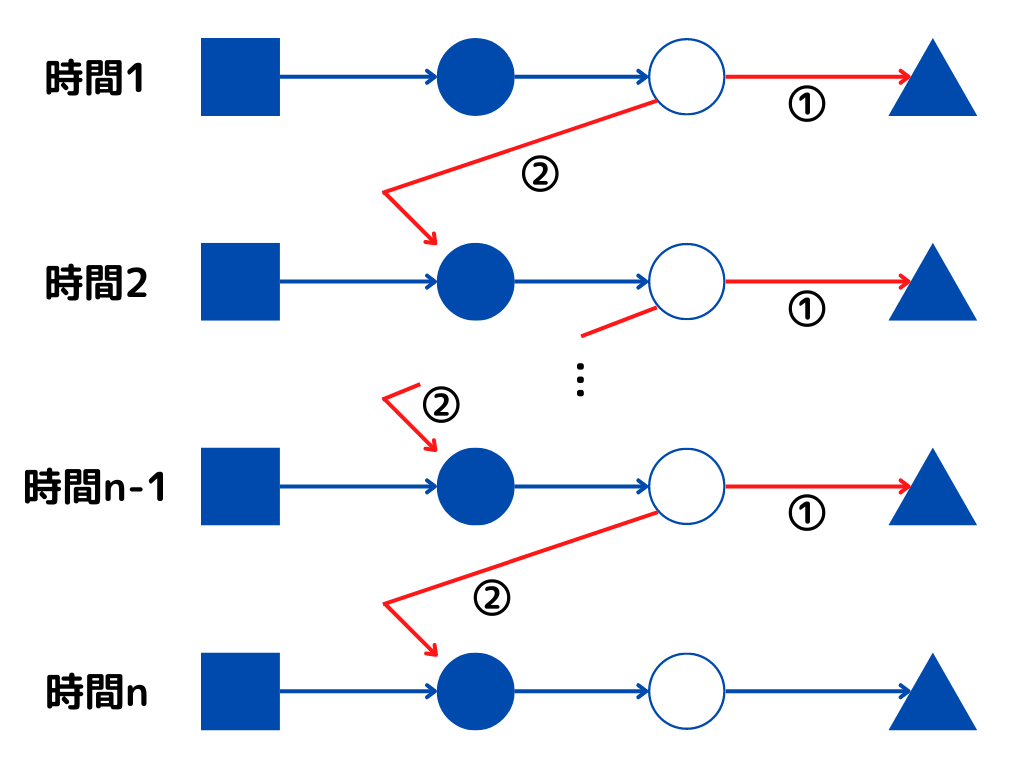
隠れ層を
①「普通のニューラルネットワークとして利用」
②「次の時間のニューラルネットワークに入力するために利用」
という二つの用途で使うのが特徴。
他のニューラルネットワークと比べて、勾配消失問題が起きやすいというのも特徴です。
BPTT
BPTTとは、RNNにおける誤差逆伝播の名称のこと。
Backpropagation Through Timeの略でBPTTといいます。
日本語にすると「通時的誤差逆伝播」で、時間方向にも誤差逆伝播が起きるということです。
LSTM
LSTMとは、RNNの時系列に関する部分を改良したモデルのこと。
LSTMは、Long Short-Term Memoryの略ですね。
入力・出力重み衝突問題を解決するために用いられています。
入力重み衝突とは、
現在の入力に対して
「過去の情報の重みは小さくしなければならないが、将来のためには大きな重みでなければならない」
という矛盾が新しいデータの特徴を取り込むときに発生すること。
出力重み衝突とは、
上記の矛盾が、現在の状態を次時刻の隠れ層に出力するときに発生すること。
二つの違いは上記の矛盾が入力に発生するか、出力に発生するかの違いだけです。
簡単に言うと「今はいらないけど、将来は使いたい」データをどうするか、ということですね。
LSTMは次の二つの構造から成り立っています。
CEC:情報を記憶する構造
データの運搬量を調整する3つのゲートを持つ構造
CECについてはシラバスにも載っているので、後で少し解説しますね。
また活用分野には、画像キャプション・文章生成などがあるようです。

CEC
CECとはConstant Error Carouselの略で、LSTMに用いられる記憶構造。
RNNの「今は必要ないけど、将来必要」というデータをうまく使いたいのが、LSTMでした。
そしてCECと、3つのゲートを持つ構造です。
3つのゲートには
「忘却ゲート」:データを忘れるかどうかを判定する
「入力ゲート」:CECへの入力信号の通過度合いを調整
「出力ゲート」:CECからの出力信号の通過度合いを調整
があります。
そして3つのゲートは、全てCECに情報をうまく記憶させるために存在しています。
CECは「情報を適度に忘れて、将来のために使うデータを記憶できる」が目的です。
GRU
GRUとはGated Recurrent Unit の略で、LSTMを軽量化したモデルのこと。
詳しく述べようとすると難しくなりすぎてしまうので、G検定では以下の二つが覚えられればいいかと。
・「リセットゲート」と「更新ゲート」の2つのゲートを用いた構造
・CECはなくなっている
CECがなくなったうえに、ゲートの数が減っていますね。
これがLSTMを軽量化したといわれる理由です。
つまり計算が軽量になり、高速にできるようになりました。
双方向 RNN
双方向 RNNとは、過去と未来の情報を踏まえて出力できるRNN。
双方向 RNN はBidirectional RNNという英語表記で書かれることもあります。
構造としては、2つのRNNが組み合わさったような構造です。
1つは時系列通りに学習し、もう1つは時系列を遡って学習します。
このように時系列を2方向から学習するため「双方向」という名前がついているようですね。
Seq2Seq
Seq2Seqとは入力の時系列データに対して、出力も時系列データで行うこと。
実は上記で述べてきたRNNやLSTMは、時系列データから1つの値を予測するものでした。
出力が一つなので、文章であれば1単語が出力されるような感じです。
これだと英語翻訳のような「文章から文章を予測する」ことができません。
1単語の出力なので、文章から1単語を予測するイメージですね。
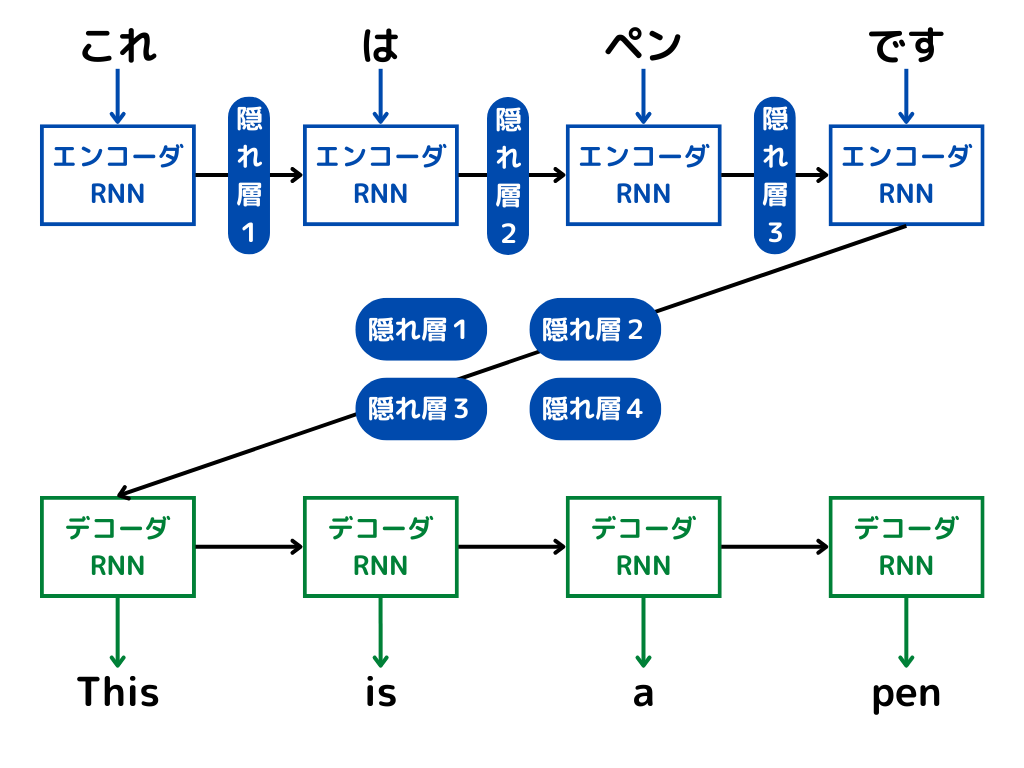
「文章から文章を予測したい」問題をエンコーダ・デコーダモデルで解決したのがSeq2Seq。
エンコード・デコードってなんだっけ?という方は、以下の記事を見てみてください。

ざっくりとした処理の手順は以下の通り。
1.文章をエンコーダに入力
2.エンコーダが「context」と呼ばれる形式に変換
3.「context」をデコーダが受け取る
4.デコーダが「context→文章」に変換して出力
エンコーダ・デコーダにはそれぞれRNNが用いられています。
Attention
Attentionとは、入力データと出力データにおける重要度(アライメント)のようなものを計算する手法。
普通のSeq2Seqでは、長文には適用が困難であることが分かっていたようですね。
そこで、Attentionを用いることで長文でも予測できるようにしたようです。
デコーダ側で出力を出す前に、エンコーダから受け取ったデータに「重要度」を与えるのがAttention。
重要度を与えるだけなので、RNNにくっつけたりすることで効率的な翻訳を手助けするイメージですね。
これによりデータの対応関係を求めて「どの単語の重要度が高いのか」を判断できるようです。
詳しい話はもっと複雑なので、興味がある方は調べてみるといいかもしれません。
そしてAttentionといっても何種類かあるので、シラバスに載っていたものを簡単に解説します。
Encoder-Decoder Attention
Encoder-Decoder Attentionとはその名の通り、エンコーダとデコーダから構成されるAttentionのこと。
これが最も基本的なAttentionのようです。
エンコーダ・デコーダの基本的なイメージは以下の通り。
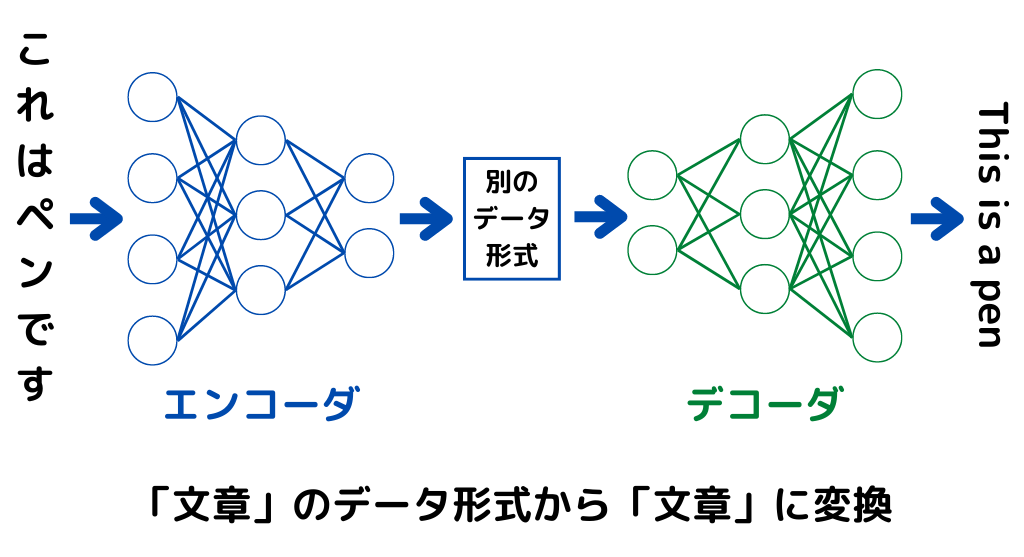
エンコーダのニューラルネットワークで、データ形式の変換を行っています。
そしてデコーダのニューラルネットワークで、変換されたデータ形式を元に戻していますね。
このエンコーダ・デコーダ部分のニューラルネットワークがそれぞれ、複数のRNNで構成されるのがEncoder-Decoder Attention。
自然言語処理では、一つの単語に対してRNNを通し、隠れ層を更新していきます。
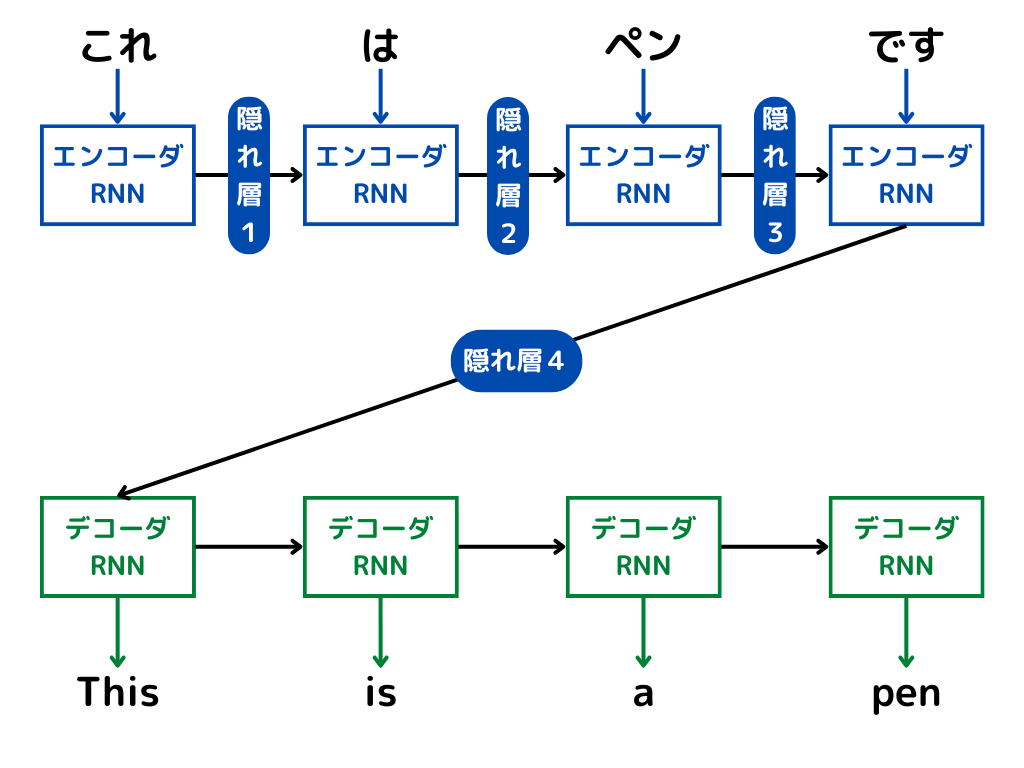
エンコーダからデコーダに渡されるのは、エンコーダの最後の隠れ層だけです。
しかしAttentionでは、Encoder の最後の隠れ層の状態だけでなく、全ての隠れ層の状態を利用。
つまり、以下のようなイメージになります。
より具体的には、Encoder の全ての隠れ層を”重み付けして”足すことで、重要度を判断しているようです。
Source-Target Attention
Source-Target Attentionは、異なるデータ間の関連を求める仕組みのこと。
異なるデータというのは文章で考えると、
・I play baseball.
・私は野球をします。
のように、翻訳前と翻訳後の文章みたいなもの。
この場合、以下のような関連を求めます。
・I →私
・play →します
・baseball →野球
後の記事で解説するTransfomerのデコーダ側で用いられる技術です。
Self-Attention
Self-Attentionとは、同一のデータ内で関連を求める仕組みのこと。
先ほどのSource-Target Attentionとは異なり、一つの文章内で単語の関係を考えます。
「I play baseball.」を例にとると、
Iとplay、playとbaseballは関連が強い
といったように単語同士の関係を考えるイメージでしょうか。
エンコーダ・デコーダ構造を持たず、自身を特徴づける単語を検索できます。
これによりAttentionは、RNNなどの言語処理の手助けをする役割から、RNNを使わなくてもよくなりました。
後の記事で解説するTransformerではエンコーダとデコーダの初期段階で使われている技術になります。
まとめ
今回は大項目「ディープラーニングの手法」の中の一つ「音声処理と自然言語処理」についての解説でした。
本記事をまとめると以下の通り。
・マルチタスク学習
・RNN
・BPTT
・LSTM
・入力、出力重み衝突
・CEC
・GRU
・双方向RNN
・Seq2Seq
・Attention
・Encoder-Decoder Attention
・Source-Target Attention
・Self-Attention
以上が大項目「ディープラーニングの手法」の中の一つ「自然言語処理」の内容でした。
ディープラーニングに関しても、細かく学習しようとするとキリがありませんし、専門的過ぎて難しくなってきます。
そこで、強化学習と同じように「そこそこ」で理解し、あとは「そういうのもあるのね」くらいで理解するのがいいでしょう。
そこで以下のようなことが重要になってくるのではないかと。
・ディープラーニングの特徴(それぞれの手法はどんな特徴があるのか)
・それぞれの手法のアルゴリズム(数式を覚えるのではなく、何が行われているか)
・何に使用されているのか(有名なもののみ)
ディープラーニングは様々な手法があるので、この三つだけでも非常に大変です。
しかし、学習を進めていると有名なものは、何度も出てくるので覚えられるようになります。
後は、新しい技術を知っているかどうかになりますが、シラバスに載っているものを押さえておけば問題ないかと。
次回は「ディープラーニングの手法」の「自然言語処理」の解説第二弾。
覚える内容が多いですが、りけーこっとんも頑張ります!
ではまた~
続きは以下のページからどうぞ!




コメント